Data Warehouse Center Administration Guide
The Data Warehouse Center provides several different ways to move data,
depending on your needs:
- To move a small amount of data, you can use SQL steps to select the source
data and insert it into a target table.
- To move large amounts of data, you can use the export and load warehouse
programs to export data from a table into a file, and then load the data into
another table. If the performance of an SQL step is not meeting your
needs, try using the export and load warehouse programs.
- To move changes to data rather than moving the whole source, use the
replication warehouse programs with a replication source.
In addition to the above methods, the DB2 Control Center has an import and
export utility that you can use to move data. For more information, see
the DB2 Universal Database Data Movement Utilities Guide and
Reference.
You can use an SQL step to select source columns and insert the data from
the columns into a target table. You can either specify that the Data
Warehouse Center generate the target table based on the source data, or use
the source data to update an existing table.
You can use a warehouse source or a warehouse target as a source for an SQL
step. The Parameters page of the Step notebook will not be available
for this step until you link it to a source in the Process Model
window. You can also link this step to a target in the Process Model
window. If you don't link the step to a target, you can specify
that a table is created when the step runs.
You cannot change an SQL step that is in production mode.
To select and insert data:
- Open the step notebook.
- Specify general information about the program. For more
information, see Providing general information about a step.
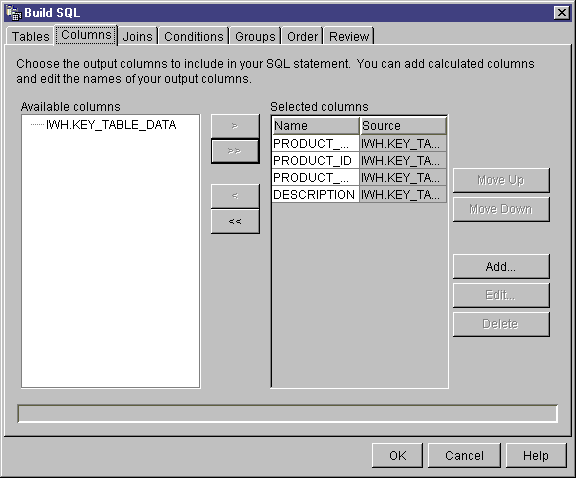
- On the SQL Statement page, create an SQL statement either by using SQL
Assist or manually:
To erase the text in the SQL statement field, click
Clear. If you want to create new SQL, you must click
Edit again.
- Optional: When you finish generating or editing your SQL statement,
click Test to test the SQL query. The Data Warehouse Center
returns sample results of your query.
- Optional: On the Column Mapping page, view or modify your column
mappings. For more information, see Defining column mapping information.
- On the Processing Options page, in the Population type list,
specify whether the step appends or replaces data in the target. For
more information about population types, see Defining processing options.
- In the Agent Site list, select an agent site where you want
your step to run. The selections in this list are agent sites that are
common to the source tables and the target table.
- If you want to have the option to run your step at any time, select the
Run on demand check box. Your step must be in test or
production mode before you can run it.
- Optional: Select the Populate externally check box if the
step is populated externally, meaning that it is started in some way other
than by the Data Warehouse Center. The step does not require any other
means of running in the Data Warehouse Center in order for you to change the
mode to production.
If the Populate externally check box is not selected, then the
step must either have a schedule, be linked to a transient table that is input
to another step, or be started by another program in order for you to change
the mode to production.
- In the Retry area, specify how many times you want the step to
run again if it needs to be retried and the amount of time that you want to
pass before the next run of the step. For more information about the
Retry area, see Defining processing options.
- In the Return Codes area, select the return code level that you
want to receive if no rows are returned, or if an SQL warning occurs when your
step is run.
- In the Incremental commit check box and the Every x
rows field, specify whether you want the step to perform an incremental
commit and, if so, how often you want the commit to occur. For more
information about incremental commit, see Incremental commit.
- Click OK to save your changes and close the step
notebook.
Incremental commit is an option that is available for all SQL steps that
allows you to control the commit scope of the data that is managed by the Data
Warehouse Center. Incremental commit can be used when the volume of
data to be moved by the agent is large enough that the DB2 log files might
fill up before the entire work of the step is complete, or when you want to
save partial data. SQL steps will complete with an error if the amount
of data being moved exceeds the DB2 maximum log files that have been
allocated.
The incremental commit option allows you to specify the number of rows
(rounded to the nearest factor of 16) to be processed before a commit is
performed. The agent selects and inserts data, committing
incrementally, until it completes the data movement successfully. When
the data movement completes successfully, outdated editions are removed (if
the target has editions).
You should consider the following concerning incremental commit:
- If you do not specify incremental commit, and an error is returned, the
data will be rolled back to its original state.
- If you specify incremental commit for a step with a population type of
Replace, the warehouse cannot be restored to its original state if an error
occurs after a commit is issued.
- Steps with a population type of Append with no edition can contain partial
data if an error occurs after a commit is issued.
- Steps with a population type of Append with editions can contain partial
data if an error occurs after a commit is issued, but the outdated editions
will not be deleted.
- The performance of your database can suffer because a significant number
of commits can occur.
- If the source and target databases are the same, the SQL cannot be
optimized. If you specify incremental commit, the Data Warehouse Center
uses Select and Insert logic rather than using the optimized Insert from
Select.
- Tables that use incremental commit and have editions might require
additional space for the table because the outdated edition is not deleted
until the new edition is successfully inserted.
You can use the supplied export programs, such as DB2 data export, to
extract data from a DB2 database and write it to a flat file. You can
use the supplied load programs, such as DB2 load replace, to extract data from
a file and write it to another DB2 database.
Recommendation: Use these programs instead of the Data
Warehouse Center's SQL processing when there is a substantial amount of
data to load. Experiment to see which one is more efficient for
you.
The bulk load and export programs operate on a delimited data file and a
DB2 database. The database server does not need to reside on the agent
site, but the source or target file must reside on the agent site. The
number and order of the input and output fields must match.
These programs write log files in the directory that is specified by the
VWS_LOGGING environment variable. The default value of VWS_LOGGING is
x:\vwswin\logging\ on Windows NT and OS/2, and /var/IWH on
UNIX, where x is the drive on which you installed the warehouse
agent.
The value of the VWS_LOGGING environment variable is the default value of
the Trace Log Directory field in the Configuration notebook.
If you change the value of the Trace Log Directory field, the Data
Warehouse Center writes the log files to the new directory that you specified,
but the value of VWS_LOGGING does not change.
For a complete list of parameters, restrictions, and return codes for these
programs, see "Steps and tasks" in the online help.
The sections that follow describe how to define the different step subtypes
for the DB2 Universal Database warehouse programs.
The sections about the DB2 UDB export and DB2 UDB load warehouse programs
describe how to define the basic values for these programs. Information
about defining the advanced features for the DB2 Universal Database Insert and
DB2 Universal Database load warehouse programs are described in the online
help.
You can use the supplied warehouse programs to export data from a DB2
UDB database or a database that is defined in ODBC.
Use the Step Properties notebook for DB2 UDB export to create a step that
can be used to export data from a DB2 Universal Database table or view to a
file located at the agent site.
The database server does not need to be on the agent site. However,
the target file must be on the agent site.
Specify the name of the target file as it is used on the agent site.
DB2 UDB export creates the target file if it does not exist, and replaces it
if it exists.
Requirement: The source table, or view, must be linked to
the step in the Process Model window. The step must be linked to the
warehouse target.
DB2 UDB export steps do not use the Column Mapping page.
To define values for a step that runs a DB2 Universal Database export
warehouse program:
- Open the step notebook.
- Specify general information about the warehouse program. For more
information, see Providing general information about a step.
- Optional: On the Parameters page, specify information for the export
step:
- In the Delimiters group box, change the delimiter types by
clicking on the down arrow to display a list of valid delimiters, and select
one:
- The column delimiter specifies the character that is used to delimit each
column exported to the target file.
- The character delimiter specifies the character that is used to enclose
character based columns that are exported to the target file.
- The decimal delimiter specifies the character that is used as a decimal
point in number columns that are exported to the target file.
- Create or update SQL statements in the SELECT statement
field:
- Click Build SQL to open SQL Assist, which will help you build
and generate the SQL statements. The Build SQL window opens.
- Click Edit to edit the SQL statements shown. The SQL
statement field becomes available.
- Click Test to test the SQL statements shown. The Sample
Contents window opens.
- Click Clear to clear the SQL statements shown. The SQL
statements in the SELECT statement field are deleted.
- To specify advanced options for the export, click
Advanced. See the online help for this window for
information about specifying these options.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
Use the Data export with ODBC to file (VWPEXPT2) warehouse program to
select data in a table that is contained in a database registered in ODBC, and
write the data to a delimited file. To run this program on AIX or UNIX,
use the ODBC version of the warehouse agent.
This step subtype uses a warehouse source or target file as a
source. You connect a source to the step in the Process Model
window. The output file is generated on the agent site.
This warehouse program is available for the following operating
systems:
- Windows NT
- AIX
- Solaris Operating Environment
- OS/2
The Column Mapping page is not available for this step.
To define values for a step that runs this warehouse program:
- Open the step notebook.
- Specify general information about the warehouse program. For more
information, see Providing general information about a step.
- On the Parameters page, in the Column delimiter field, click or
type the character that you want to use as a column delimiter.
- Create or generate SQL either using SQL Assist or manually:
- To use SQL Assist to generate a SELECT statement, click Build
SQL. SQL Assist opens. After you close SQL Assist, the
newly generated SQL is displayed in the SELECT statement field.
- To create SQL manually, or you want to edit SQL that is generated by SQL
Assist, click Edit. The SELECT Statement field is
available. SQL Assist is no longer available.
Optional: If you want to erase the text in the SELECT statement
field, click Clear. If you want to create new SQL, you must
click Edit again.
- Optional: When you finish generating or editing your SQL, click
Test to test the SQL query. The Data Warehouse Center
returns sample results of your query.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
You can use the supplied warehouse programs to load data into a DB2
Universal Database, DB2 for AS/400, and DB2 for OS/390 database.
Use the DB2 Universal Database Load Step Properties notebook to create a
step that loads data from a source or target file into a DB2 Universal
Database table.
You can use a warehouse source or target as a source for this step
subtype. Link the source to the step subtype in the Process Model
window. Then, link the step subtype to a warehouse target.
The Column Mapping page is not available for this step.
To define values for a step that runs a DB2 Universal Database load
warehouse program:
- Open the step notebook.
- Specify general information about the warehouse program. For more
information, see Providing general information about a step.
- Optional: On the Parameters page do the following:
- Select the load mode from the Load mode drop-down list.
The possible values are:
- INSERT - loads the table and appends data from the file to the existing
table. (This is the default.)
- REPLACE - loads the table and replaces all the data in the existing
table.
- RESTART - restarts a load process that was abnormally terminated.
- TERMINATE - terminates a currently executing load process.
- In the Delimiters group box, change the delimiter types by
clicking on the down arrow to display a list of valid delimiters, and select
one:
- The column delimiter specifies the character that is used to delimit each
column in the file to be loaded.
- The character delimiter specifies the character that is used to enclose
character-based columns in the file to be loaded.
- The decimal delimiter specifies the character that is used as a decimal
point in number columns in the file to be loaded.
- To specify advanced options for the load, click
Advanced. See the online help for this window for
information about specifying these options.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
Use the DB2 UDB for AS/400 Data Load Insert (VWPLOADI) program to load data
from a flat file to a DB2 UDB for AS/400 table. The load operation
appends new data to the end of existing data in the table.
Before you define this step subtype, you must connect the step to a
warehouse source and a warehouse target in the Process Modeler.
Acceptable source files for the AS/400 implementation of VWPLOADI are
AS/400 QSYS source file members or stream files in Integrated File System
(IFS), the root file system.
Tip: You can improve both performance and storage use by
using QSYS file members instead of stream files. CPYFRMIMPF makes a
copy of the entire stream file to QRESTORE and then loads the copy into your
table. See the online help for CPYFRMIMPF for more information.
Target tables can reside only in the QSYS file system.
You can make changes to the step only when the step is in development
mode.
Before the program loads new data into the table, it exports the table to a
backup file, which you can use for recovery.
The Column Mapping page is not available for this step.
To use this program, you must have the following PTFs applied to the
AS/400 agent site:
Command PTF:
|
5769SS100 VRM420 SF46911
|
Code PTF:
|
5769SS100 VRM420 SF46976
|
Maintenance PTF:
|
5769SS100 VRM420 SF49466
|
These PTFs provide the AS/400 CPYFRMIMPF and CPYTOIMPF commands (LOAD and
EXPORT), which are required to run VWPLOADI program. These PTFs also
install the online help for these commands.
The user profile under which this program and the warehouse agent run
must have at least read/write authority to the table that is to be
loaded.
The following requirements apply to the VWPLOADI program. For
information about the limitations of the CPYFRMIMPF command, see the
restrictions section of the online help for the CPYFRMIMPF command. To
view the online help for this command, type CPYFRMIMPF on the
AS/400 command prompt, and press F1.
- The Data Warehouse Center definition for the agent site that is running
the program must include a user ID and password. The database server
does not need to be on the agent site. However, the source file must be
on the database server. Specify the fully qualified name of the source
files as defined on the DB2 server system.
- If the program detects a failure during processing, the table is
emptied. If the load process generates warnings, the program returns as
successfully completed.
- The default behavior for VWPLOADI is to tolerate all recoverable data
errors during LOAD (ERRLVL(*NOMAX)).
To override this behavior, include the ERRLVL(n) keyword in the
fileMod string parameter, where n = the number of permitted
recoverable errors.
You can find more information about the ERRLVL keyword in the online help
for the CPYFRMIMPF command.
To define values for a step that uses this program:
- Open the step notebook.
- Specify general information about the program. For more
information, see Providing general information about a step.
- Click the Parameters tab.
- Optional: To specify the delimiters of your load program, click
Specify only the delimiters of the MODSTRING. Otherwise, the
default entries in the Record, Column, Character
strings, and Decimal point fields are used.
Specify the delimiters for your load program:
- In the Record list, specify how you want to indicate the end of
record.
- In the Column list, specify the character that you want to use
as a column delimiter.
- In the Character strings field, specify the character that you
want to use to indicate character strings.
- In the Decimal point field, click the character that you want
to use to indicate a decimal point.
- Optional: To add parameters to the program, click
Type Modstring parameters. Type your parameters in the field
under the radio button.
This field is used to modify the file characteristics that the CPYFRMIMPF
command expects the input file to have. If this parameter is omitted,
all of the default values that the CPYFRMIMPF command expects are assumed to
be correct.
Some of the default characteristics of the input file are:
- The file is comma delimited.
- Strings and date/time values are enclosed in quotation marks.
- Date and time values are in ISO format.
- The decimal point is represented by a period character.
For more information on the default values for the CPYFRMIMPF command, see
the AS/400 online help for the CPYFRMIMPF command.
The format for the FileMod string is:
- The string must contain valid CPYFRMIMPF command keywords. All of
the valid keywords for the CPYFRMIMPF command are described in the online help
for the command.
- Each keyword must be followed immediately by its value. The value
must be enclosed in parentheses.
- Each keyword must be separated from the next keyword by a space.
Requirement: Certain parameters require that you enclose
values in two single quotation marks. For example, the FLDDLM command
must have the values enclosed by two single quotation marks. The Data
Warehouse Center generates the AS/400 CALL statement for VWPLOADI in the
form:
CALL PGM(QIWH/VWPLOADI) PARM('fromfile' 'totable' 'filemodstring')
Two single quotation marks together tell the AS/400 command prompt
processor that your parameter value contains a single quotation mark.
This prevents the command line processor from confusing a single quotation
mark with the regular end-of-parameter marker.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
The VWPLOADI program provides two kinds of diagnostic
information:
- The return code, as documented in the Data Warehouse Center Concepts
online help
- The VWPLOADI trace
Important: Successful completion of this program does not
guarantee that the data was transferred correctly. For stricter error
handling, use the ERRLVL parameter.
The VWPLOADI trace files are located in the Integrated File System in
the /QIBM/UserData/IWH directory.
The VWPLOADI trace file has the following name format:
VWxxxxxxxx.VWPLOADI
where xxxxxxxx is the process ID of the VWPLOADI run that
produced the file.
To view trace files from a workstation:
- Use Client Access/400 to map your AS/400 root file system to a logical
drive, or use FTP to copy the file to the workstation.
- Open the trace file with a text editor to view the information.
To use Client Access/400 to map an AS/400 system to a
logical drive on an NT workstation:
- Set up a Client Access/400 connection to your AS/400 system over
TCP/IP.
- Open the Windows NT File Explorer.
- From the Explorer menu, click Tools --> Map Network
Drive.
- Type the path name:
\\hostname\.
where hostname is the fully qualified TCP/IP host name of your
AS/400 system.
- Click OK.
Requirement: If you use Client Access/400 to access the
trace file, you must define the file extension .VWPLOADI to
Client Access/400. Defining this extension allows Client Access/400 to
translate the contents of files with this extension from EBCDIC to
ASCII.
To define a file extension to Client Access/400:
- From Windows NT, select Start --> Programs
--> IBM AS400 Client Access --> Client Access
Properties.
The Client Access notebook opens.
- Click the Network Drives tab.
- In the File extension: field, type
.VWPLOADR.
- Click Add.
- Click Apply.
- Click OK.
You should now be able to load the file into any ASCII text editor or word
processor.
If there was a failure of any of the system commands issued by
VWPLOADI, then there will be an exception code recorded in the VWPLOADI trace
file. To get an explanation for the exception:
- At an AS/400 command prompt, enter DSPMSGD RANGE(xxxxxxx),
where xxxxxxx is the exception code. For example, you might
enter DSPMSGD RANGE(CPF2817).
The Display Formatted Message Text panel is displayed.
- Select option 30 to display all information. A message
similar to the following message is displayed:
Message ID . . . . . . . . . : CPF2817
Message file . . . . . . . . : QCPFMSG
Library . . . . . . . . . : QSYS
Message . . . . : Copy command ended because of error.
Cause . . . . . : An error occurred while the file was
being copied.
Recovery . . . : See the messages previously listed.
Correct the errors, and then try the
request again.
The second line in the VWPLOADR trace file contains the information that
you need to issue the WRKJOB command.
To view the spool file, you can cut and paste the name of the message file
to an AS/400 command prompt after the WRKJOB command and press Enter.
View the spool file for the job to get additional information about any errors
that you may have encountered.
Use the DB2 UDB for AS/400 Data Load Replace (VWPLOADR) program to load
data from a flat file to a DB2 UDB for AS/400 table. The load operation
completely replaces existing data in the table.
Before you define this step subtype, you must connect the step to a
warehouse source and a warehouse target in the Process Modeler.
Acceptable source files for the AS/400 implementation of the VWPLOADR
program are AS/400 QSYS source file members or stream files in Integrated File
System (IFS), the root file system.
Tip: You can improve both performance and storage use by
using QSYS file members instead of stream files. CPYFRMIMPF copies the
entire stream file to QRESTORE and then loads the copy into your table.
See the online help for CPYFRMIMPF for more information.
Target tables can reside only in the QSYS file system.
You can make changes to the step only when the step is in development
mode.
The Column Mapping page is not available for this step.
To use this program, you must have the following PTFs applied to the
AS/400 agent site:
Command PTF:
|
5769SS100 VRM420 SF46911
|
Code PTF:
|
5769SS100 VRM420 SF46976
|
Maintenance PTF:
|
5769SS100 VRM420 SF49466
|
These PTFs provide the AS/400 CPYFRMIMPF and CPYTOIMPF commands (LOAD and
EXPORT). These are the commands that makes the VWPLOADR program
work. These PTFs also install the online help for these
commands.
The user profile under which this program and the warehouse agent run
must have at least read/write authority on the table that is to be
loaded.
The following requirements apply to the VWPLOADR program. For
information about the limitations of the CPYFRMIMPF command, see the
restrictions section of the online help for the CPYFRMIMPF command. To
view the online help for this command, type CPYFRMIMPF on the
AS/400 command prompt and press F1.
- The Data Warehouse Center definition for the agent site that is running
the program must include a user ID and password. The database server
does not need to be on the agent site. However, the source file must be
on the database server. Specify the fully qualified name of the source
files as defined on the DB2 server.
- If the program detects a failure during processing, the table will be
emptied. If the load generates warnings, the program returns as
successfully completed.
- This implementation of the VWPLOADR program differs from VWPLOADR on other
platforms. Specifically, it does not delete all loaded records if the
load operation fails for some reason.
Normally, this program replaces everything in the target table each time it
is run, and automatically deletes records from a failed run. However,
if the load operation fails, avoid using data in the target table. If
there is data in the target table, it will not be complete.
- The default behavior for VWPLOADR is to tolerate all recoverable data
errors during LOAD (ERRLVL(*NOMAX)).
To override this behavior, include the ERRLVL(n) keyword in the
fileMod string parameter, where n = the number of permitted
recoverable errors.
You can find more information about the ERRLVL keyword in the online help
for the CPYFRMIMPF command.
To define values for a step that uses this program:
- Open the step notebook.
- Specify general information about the program. For more
information, see Providing general information about a step.
- Click the Parameters tab.
- Optional: If you want to specify the delimiters of your
load program, click Specify only the delimiters of the
MODSTRING. If you do not click this radio button, the default
entries in the Record, Column, Character strings, and Decimal point fields are
assumed to be correct.
- If you clicked Specify only the delimiters of the MODSTRING,
specify the delimiters for your load program:
- In the Record list, specify how you want to indicate the end of
record.
- In the Column list, specify the character that you want to use
as a column delimiter.
- In the Character strings field, specify the character that you
want to use to indicate character strings.
- In the Decimal point field, click the character that you want
to use to indicate a decimal point.
- Optional: To add additional parameters to the program, click
Type Modstring parameters. Type your parameters in the field
under the radio button.
This field is used to modify the file characteristics that the CPYFRMIMPF
command expects the input file to have. If this parameter is omitted,
all of the default values that the CPYFRMIMPF command expects are assumed to
be correct.
Some of the default characteristics of the input file are:
- The file is comma delimited.
- Strings and date/time values are enclosed in quotation marks.
- Date and time values are in ISO format.
- The decimal point is represented by a period character.
For more information on the default values for the CPYFRMIMPF command, see
the AS/400 online help for the CPYFRMIMPF command.
The format for the FileMod string is:
- The string must contain valid CPYFRMIMPF command keywords. All of
the valid keywords for the CPYFRMIMPF command are described in the online help
for the command.
- Each keyword must be followed immediately by its value. The value
must be enclosed in parentheses.
- Each keyword must be separated from the next keyword by a space.
Attention: Certain parameters require that you enclose
values in two single quotation marks. For example, the FLDDLM command
must have the values enclosed by two single quotation marks. You must
do this because the Data Warehouse Center generates the AS/400 CALL statement
for VWPLOADI in the form:
CALL PGM(QIWH/VWPLOADI) PARM('fromfile' 'totable' 'filemodstring')
Two single quotation marks together tells the AS/400 command prompt
processor that your parameter value contains a single quotation mark
character. This prevents the command line processor from confusing your
single quotation mark character with the regular end-of-parameter
marker.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
The VWPLOADR program provides two kinds of diagnostic
information:
- The return code, as documented in the Data Warehouse Center Concepts
online help
- The VWPLOADR trace
Important: Successful completion of this program does not
guarantee that the data was transferred correctly. For stricter error
handling, use the ERRLVL parameter.
The VWPLOADR trace files are located in the Integrated File System in
the /QIBM/UserData/IWH directory.
The VWPLOADR trace file has the following name format:
VWxxxxxxxx.VWPLOADR
where xxxxxxxx is the process ID of the VWPLOADR run that
produced the file.
To view trace files from a workstation:
- Use Client Access/400 to map your AS/400 root file system to a logical
drive, or use FTP to copy the file to the workstation.
For information about using Client Access/400, see "Viewing the VWPLOADR trace via Client Access/400".
- Open the trace file with a text editor to view the information.
To use Client Access/400 to map an AS/400 system to a
logical drive on an NT workstation:
- Set up a Client Access/400 connection to your AS/400 system over
TCP/IP.
- Open the Windows NT File Explorer.
- From the Explorer menu, select Tools --> Map Network
Drive.
- Type the pathname:
\\hostname\.
where hostname is the fully qualified TCP/IP host name of your
AS/400 system.
- Click OK.
Requirement: If you use Client Access/400 to access the
trace file, you must define the file extension .VWPLOADR to
Client Access/400. Defining this extension allows Client Access/400 to
translate the contents of files with this extension from EBCDIC to
ASCII.
To define a file extension to Client Access/400:
- From Windows NT, click Start --> Programs -->
IBM AS400 Client Access --> Client Access Properties.
The Client Access notebook opens.
- Click the Network Drives tab.
- Type .VWPLOADR in the File extension:
field.
- Click Add.
- Click Apply.
- Click OK.
You should now be able to load the file into any ASCII text editor or word
processor.
If there was a failure of any of the system commands issued by
VWPLOADR, then there will be an exception code recorded in the VWPLOADR trace
file. To get an explanation for the exception:
- At an AS/400 command prompt, enter DSPMSGD RANGE(xxxxxxx),
where xxxxxxx is the exception code. For example, you might
enter DSPMSGD RANGE(CPF2817).
The Display Formatted Message Text panel is displayed.
- Select option 30 to display all information. A message
similar to the following message is displayed:
Message ID . . . . . . . . . : CPF2817
Message file . . . . . . . . : QCPFMSG
Library . . . . . . . . . : QSYS
Message . . . . : Copy command ended because of error.
Cause . . . . . : An error occurred while the file was
being copied.
Recovery . . . : See the messages previously listed.
Correct the errors, and then try the
request again.
The second line in the VWPLOADR trace file contains the information that
you need to issue the WRKJOB command.
To view the spool file, you can copy and paste the name of the message file
to an AS/400 command prompt after the WRKJOB command, and press Enter.
View the spool file for the job to get additional information about any errors
that might have occurred.
Use the DB2 for OS/390 Load warehouse program to load records into one or
more tables in a table space.
To define a values for a step that uses this warehouse program:
- Open the step notebook.
- Specify general information about the warehouse program. For more
information, see Providing general information about a step.
- On the Parameters page, if you want to preformat pages in the table space
and index spaces that are associated with the table, select the Entire
table space and index spaces are preformatted check box to have the free
pages between the high-used RBA (or page) to the high-allocated RBA be
preformatted in the table space and index spaces associated with the
table. The preformatting occurs after the data is loaded and the
indexes are built.
- To specify whether records are to be loaded into an empty or non-empty
table space, select the Specify RESUME option at table space level
check box.
- Click NO to load records into an empty table space. If
the table space is not empty, and you did not specify REPLACE, the LOAD
process ends with a warning message. For nonsegmented table spaces that
contain deleted rows or rows of dropped tables, using the REPLACE option
provides more efficiency.
- Click YES to drain the table space, which can inhibit
concurrent processing of separate partitions. If the table space is
empty, a warning message is issued, but the table space is loaded.
Loading begins at the current end of data in the table space. Space
occupied by rows marked as deleted or by rows of dropped tables is not
reused.
If the table space is not empty, and you are not replacing contents (the
Reset table space and indexes to empty before load check box is not
checked), a DB2 UDB for OS/390 message is issued, and the utility job step
terminates with a job step condition code of 8. For nonsegmented table
spaces, space occupied by rows that are marked as deleted or by rows of
dropped tables is not used.
- If you want the newly loaded rows to replace all existing rows of all
tables in the table space, and not just those of the table that you are
loading, select the Reset table space and indexes to empty before
load check box (LOAD REPLACE) .
- Specify one of the Input data file type radio buttons to select
the code page type for the input data. If you specify ASCII, numeric,
date, time, and time stamp internal formats are not affected.
- Select the Format of the input records check box to identify
the format of the input record. The format must be compatible with DB2
unload format (UNLOAD) or with SQL/DS(TM) unload format. This action
uniquely determines the format of the input. No field specifications
are allowed in an INTO TABLE option.
The DB2 unload format specifies that the input record format is compatible
with the DB2 unload format. The DB2 unload format is the result of
REORG with the UNLOAD ONLY option. Input records that were unloaded by
the REORG utility are loaded into the tables from which they were
unloaded. Do not add or change column specifications between the REORG
UNLOAD ONLY and the LOAD FORMAT UNLOAD. DB2 reloads the records into
the same tables from which they were unloaded.
The SQL/DS unload format specifies that the input record format is
compatible with the SQL/DS unload format. The data type of a column in
the table to be loaded must be the same as the data type of the corresponding
column in the SQL/DS table. SQL/DS strings that are longer than the DB2
limit cannot be loaded.
- Select the Allow no substitution characters in a string check
box to prohibit substitution characters from being placed in a string as a
result of a conversion. When this check box is selected and DB2 UDB for
OS/390 determines that a substitution character has been placed in a string as
a result of a conversion, it performs one of the following actions:
- If discard processing is active, DB2 issues message DSNU310I and places
the record in the discard file.
- If discard processing is not active, DB2 issues message DSNU334I, and the
utility abnormally terminates.
- Select the CCSIDs for the input file check box to specify up to
three coded character set identifiers (CCSIDs) for the input data. Type
a valid integer value in one or all of the fields. The default CCSID is
the one that you chose when you installed DB2 Universal Database for
OS/390. If any of the fields relating to the CCSID are left blank, the
field will use the installation default. You can specify SBCS, DBCS
(double byte character set) data, or mixed DBCS (graphics and double byte
character sets).
- Select the Enforce check and referential constraints
check boxes to have DB2 notify you when there are check constraints and
referential constraints. When constraints are enforced, and the loading
operation detects a violation, DB2 deletes the errant row and issues a message
to identify it. If you choose to enforce constraint, and referential
constraints exist, sort input and sort output data sets are required.
- In the Maximum number of records to be written on discard data
set field, specify a maximum number of source records to be written on
the discard data set. The value can range from 0 to
2,147,483,647. If the maximum number is reached, LOAD processing
abnormally ends, the discard data set is empty, and you cannot see which
records were discarded. The default is 0, which means that there is no
maximum. In this case, the entire input data set can be
discarded.
- Type the name of the discard data set in the Discard data set
field. This is a work data set that is required if you specify a number
of records to be discarded. This data set holds copies of records that
did not get loaded. It also holds copies of records that were loaded,
then removed. It must be a sequential data set that is readable by BSAM
services. SYSDISC is the data definition name that is associated with
the data set name.
- Type the name of a work data set for error processing in the Error
data set field. This data set stores information about errors
that occur in the load processing. This field is required if you
specified a number of records to be discarded during load processing.
SYSERR is the data definition name that is associated with the data set
name.
- Click Advanced to open the DB2 for OS/390 Load Table Space
notebook. From this notebook you can specify additional options for
loading data into a table. You can also select to gather statistics for
a table space, index, or both. The statistics are stored in the DB2 for
OS/390 catalog.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
The sections that follow describe how to define the different step
subtypes for the warehouse file programs.
Use the warehouse program Copy file using FTP (VWPRCPY) to copy files on
the agent site to and from a remote host.
Before you copy files to OS/390, you must allocate their data sets.
You cannot transfer VSAM data sets. When you define a step that uses
this warehouse program, select a source file and select a target file.
One file must be stored on the agent site, and the other must be stored on the
OS/390 system.
This warehouse program is available for the following operating
systems:
- Windows NT
- AIX
- Solaris Operating Environment
- AS/400
- OS/2
The Column Mapping page is not available for this step subtype.
To define a step that runs this warehouse program:
- Open the step notebook.
- Specify general information about the warehouse program. For more
information, see Providing general information about a step.
- On the Parameters page, click either Copy files from the remote host
to the agent site (GET method) or Copy files from the agent site to
the remote host (PUT method).
- In the Transfer type area, click either ASCII or
Binary.
- In the Remote system name field, type the name of the remote
system from which or to which to copy files.
- In the Remote user ID field, type the user ID to use to connect
to the remote host.
- In the Remote password field, type the password for the user
ID.
- In the Verify remote password field, type the password
again.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
If you are having problems accessing a remote file on a secure UNIX system,
verify that the home directory of the user ID contains a .netrc
file. The
.netrc file must contain an entry that includes the host name of the
agent site and the remote user ID that you want to use.
For example, the host name of the agent site is
glacier.stl.ibm.com. You want to transfer a file
using FTP from the remote site kingkong.stl.ibm.com to
the agent site, using the remote user ID vwinst2. The
~vwinst2/.netrc file must contain the following entry:
machine glacier.stl.ibm.com login vwinst2
Use the warehouse program Run FTP command file (VWPFTP) to transfer files
from a remote host using FTP. When you define a step that uses this
warehouse program, do not specify a source or target table for the
step.
This warehouse program is available for the following operating
systems:
- Windows NT
- AIX
- Solaris Operating Environment
- AS/400
- OS/2
The Column Mapping page is not available for this step.
To define values for a step that runs this warehouse program:
- Open the step notebook.
- Specify general information about the warehouse program. For more
information, see Providing general information about a step.
- On the Parameters page, in the Remote System Name field, type
the name of the remote system to access.
- In the FTP command file (full path name) filed type the path
and file name of the FTP command file.
In the FTP command file, you must supply the following information, in the
order listed, and on separate lines:
- User ID
- Password
- One or more FTP commands, each on a separate line
In the following example, you use FTP to log on to the remote host using
the user ID and password, get the remote file, and put it in the specified
local directory:
nst1
password
get /etc/services d:/udprcpy.out
quit
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
If you are having problems accessing a remote file on a secure UNIX system,
verify that the home directory of the user ID contains a .netrc
file. The
.netrc file must contain an entry that includes the host name of the
agent site and the remote user ID that you want to use.
For example, the host name of the agent site is
glacier.stl.ibm.com. You want to transfer a file
using FTP from the remote site kingkong.stl.ibm.com to
the agent site, using the remote user ID vwinst2. The
~vwinst2/.netrc file must contain the following entry:
machine glacier.stl.ibm.com login vwinst2
Use the Submit OS/390 JCL jobstream (VWPMVS) warehouse program to submit a
JCL jobstream that resides on OS/390 to an OS/390 system for execution.
The job must have a MSGCLASS and SYSOUT routed to a held output
class.
Before you use the Submit OS/390 JCL Jobstream warehouse program, test your
JCL file by running it from TSO under the same user ID that you plan to use
with the program.
This warehouse program runs successfully if the OS/390 host name, user ID,
and password are correct. If you want to test the validity of the
results generated by the JCL, you must write your own testing logic. If
the FTP session times out, this program returns an FTP error, even if the JCL
ultimately runs successfully on the OS/390 system.
The Submit OS/390 JCL Jobstream warehouse program also receives the JES log
file on the agent site. It erases the copy of the JES log from any
previous jobs on the agent site before submitting a new job for
processing. It also verifies that the JES log file is downloaded to the
agent site after the job completes.
The Submit OS/390 JCL Jobstream warehouse program requires TCP/IP
3.2 or later installed on OS/390. Verify that the FTP service is
enabled before using the program.
When you define a step that uses this warehouse program, do not specify a
source or target table for the step.
This warehouse program is available for the following operating
systems:
- Windows NT
- AIX
- Solaris Operating Environment
- OS/2
The Column Mapping page is not available for this step.
To define values for a step that runs this warehouse program:
- Open the step notebook.
- Specify general information about the warehouse program. For more
information, see Providing general information about a step.
- On the Parameters page, in the MVS system name field, type the
name of the MVS host on which to run the job.
- In the MVS User ID field, type the user ID to use to connect to
the MVS host.
- In the MVS password field, type the password for the user
ID.
- In the Verify MVS password field, type the password
again.
- In the MVS JCL File field, type the name of the JCL file to
submit. The name must consist of the user ID plus one character.
- In the Local spool file full path name field, type the path and
file name of the file on the agent site that is to receive the JES log
file. You must define a .netrc file in the same directory as the
JES file.
- On the Processing Options page, provide information about how your step
processes. For more information, see Defining processing options.
- Click OK to save your changes and close the step
notebook.
If you are having problems accessing a remote file on a secure UNIX system,
verify that the home directory of the user ID contains a .netrc
file. The
.netrc file must contain an entry that includes the host name of the
agent site and the remote user ID that you want to use.
For example, the host name of the agent site is
glacier.stl.ibm.com. You want to transfer a file
using FTP from the remote site kingkong.stl.ibm.com to
the agent site, using the remote user ID vwinst2. The
~vwinst2/.netrc file must contain the following entry:
machine glacier.stl.ibm.com login vwinst2
Replication is a process of maintaining a defined set of data in more than
one location. It involves copying designated changes from one location
(a source) to another (a target), and synchronizing the data in both
locations. The source and target can be in logical servers (such as a
DB2 database or a DB2 for OS/390 subsystem or data-sharing group) that are on
the same machine or on different machines in a distributed network.
You can use the replication capabilities of the Data Warehouse Center when
you want to keep a warehouse table synchronized with an operational table
without having to fully load the table each time the operational table is
updated. With replication, you can use incremental updates to keep your
data current.
You can use the Data Warehouse Center to define a replication step, which
will replicate changes between any DB2 relational databases. You can
also use other IBM products (such as DB2 DataJoiner and DataPropagator(TM)
NonRelational) or non-IBM products (such as Microsoft SQL Server and Sybase
SQL Server) to replicate data between many database products -- both
relational and nonrelational. The replication environment that you need
depends on when you want data updated and how you want transactions
handled.
To define a replication step with the Data Warehouse Center, you must
belong to a warehouse group that has access to the process in which the step
will be used.
The Data Warehouse Center supports five types of replication:
- User copy
- Produces target tables that are read-only copies of the replication source
with no replication control columns added. These tables look like
regular source tables and are a good starting point for replication.
They are the most common type of target table.
- Point-in-time
- Produces target tables that are read-only copies of the replication source
with a timestamp column added. The timestamp column is originally
null. When changes are replicated, values are added to indicate the
time when updates are made. Use this type of table if you want to keep
track of the time of changes.
- Base aggregate
- Produces read-only tables that summarize the contents of a source
table. Base aggregate replication tables are useful for tracking the
state of a source table on a regular basis. Aggregate tables use SQL
column functions (such as SUM and AVG) to compute summaries of the entire
contents of the source tables or of the recent changes made to source table
data.
- Change aggregate
- Produces tables that work with the change data in the control tables, not
with the contents of the source table. This type of replication is
useful for tracking the changes made between each Apply program cycle.
- Staging table
- Produces read-only tables that contain data from committed
transactions. Also called consistent change-data tables (CCD tables),
these tables contain different data if they are condensed, noncondensed,
complete, or noncomplete.
- A condensed staging table contains only the most current value
for a row. The Apply program updates only rows that are already in
condensed tables. Condensed tables are useful for staging changes to
remote locations and for summarizing hot-spot updates before they are
replicated to targets.
- A noncondensed staging table contains a history of changes to a
row. The Apply program appends rows to noncondensed tables.
Noncondensed staging tables are useful for auditing purposes.
- A complete staging table contains all the rows that you want to
replicate from the source table.
- A noncomplete staging table is empty when it is created, and
rows are appended as changes are made to the source table.
For a replication step, promoting to test mode will create the target table
and generate the subscription set. The first time a replication step is
run, a full refresh copy is made. Promoting a replication step to
production mode will enable the schedules that have been defined. You
can make changes to a step only when it is in development mode.
You define replication sources in the same way that you define other
relational sources with the Data Warehouse Center. In addition to the
other database objects that can be returned from a database (tables, views,
and system tables), you can choose to return replication-enabled tables and
views. A table or view must be defined for replication using the DB2
Control Center before it can be used as a replication source in the Data
Warehouse Center. For instructions on defining a table or view as a
replication source, see the DB2 Replication Guide and
Reference.
When you define a replication-enabled table as a warehouse source table,
the before and after image columns are identified by before or
after after the column name.
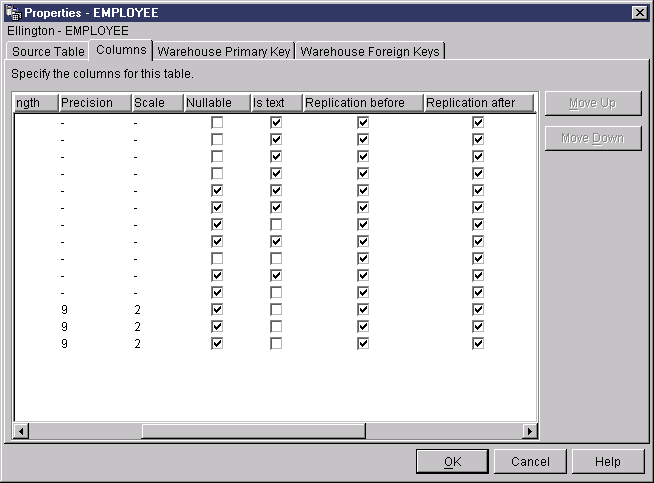
If you choose to retrieve only replication-enabled tables from the source
database, only the columns within the table that are enabled for replication
will be retrieved.
For instructions on defining a replication source in the Data Warehouse
Center, see Defining a DB2 warehouse source.
A source table used for a user copy or point-in-time replication step must
have a primary key. Use the DB2 Control Center to define a primary key
for each table that you want to include in a user copy or point-in-time
replication step.
To define a user copy, point-in-time, or base aggregate replication
step:
- Define a process object.
- Open the process object.
- Add one or more warehouse sources.
- Add one or more warehouse targets.
- Open the step notebook.
- Specify information for your step:
- In the Name field, you can type a new name for the step.
Otherwise, you can keep the name that the Data Warehouse Center automatically
supplied for the step.
- Optional: In the Administrator field, type the name of
the person who is responsible for the maintenance of this step.
- Optional: In the Description field, type a business
description for your step. This description can be a maximum of 255
characters.
- Optional: In the Notes field, type detailed information
that might be helpful to users who can access this step.
- On the Parameters page, select the columns that you want to replicate from
the Available columns list, and click >. The
columns that you select move to the Selected columns list.
The Available columns list shows only the columns that have been
enabled for change capture.
To include all of the items in the Available columns list, click
>>.
- Optional: Click Add Calculated Column to open a window in
which you can create derived columns. The derived columns that you
create are displayed in the Selected columns list.
- Optional: To select which rows are to be replicated, write a WHERE
statement to subselect rows.
- On the Column Mapping page, map the output columns that result from the
SQL statement that you defined on the Parameters page to columns in your
target table. On this page, output columns from the Parameters page are
referred to as source columns. Source columns are listed on the left
side of the page. Target columns from the output table linked to the
step are listed on the right side of the page. Use the Column Mapping
page to perform the following tasks:
- To create a mapping, click a source column and drag it to a target
column. An arrow is drawn between the source column and the target
column.
- To delete a mapping, right-click an arrow and click
Delete.
- If the output table is not used by any steps that are in test or
production mode, you can change the attributes of the target column. To
rename a target column, double-click the column name, and type the new
name. You can also modify any other attributes of the target column by
double-clicking the attribute.
- To move a target column up or down the list, select the column.
Then, click the up arrow or down arrow buttons. If the target column is
mapped to a source column, the mapping remains intact.
If the Parameters page produces no output columns, or if this step is not
linked to a target table and you did not specified automatic generation of a
default table in the Parameters page, you will not be able to use this page to
map your columns. Some steps will not allow you to change the column
mapping.
- On the Processing Options page, select an agent site where you want your
step to run from the Agent Site drop-down list. The
selections in this list are agent sites that are common to the source tables
and the target table.
- The Population type for replication steps can have only one value,
Replicate.
- If you want the option to run your step at any time, select the Run
on demand check box. Your step must be in test or production mode
before you can run it.
- Optional: Select the Populate externally check box if the
step is populated externally, meaning that it is started in some way other
than by the Data Warehouse Center. The step does not require any other
means of running in the Data Warehouse Center in order for you to change the
mode to production.
If the Populate externally check box is not selected, then the
step must have a schedule, be linked to a transient table that is input to
another step, or be started by another program in order for you to change the
mode to production.
- In the Retry area, specify how many times you want the step to
run again if it needs to be retried, and the amount of time that you want to
pass before the next run of the step.
- In the Replication control database field, select the control
database or subsystem that contains the replication control tables for the
Apply program.
- In the Database type list, select the database type for the
replication control database.
- In the User ID field, type the user ID to access the
replication control database.
- In the Password field, type the password for the user ID that
will access the database.
- In the Verify password field, type the password again.
- In the Subscription set name field, type the name of the
subscription set. This name can contain a maximum of 18 characters and
can be an ordinary or delimited qualifier.
- Optional: In the Apply qualifier field, type the name of
the apply qualifier. The apply qualifier name must be unique for every
replication step that is defined. If you do not specify an apply
qualifier, the Data Warehouse Center generates one for you.
- Optional: In the Event name field, type the event
name. The event name is the name of the event that is posted in the
event table that the Apply program reads. The event name must be unique
for every replication step that is defined. If you do not specify an
event name, the Data Warehouse Center generates one for you.
- In the Blocking factor field, specify the number of minutes
worth of change data that can be replicated during a subscription
cycle.
- Click OK to save your changes and close the notebook.
- Link the step to the warehouse sources.
- Link the steps to the warehouse targets.
- Promote the step to test mode.
- Run the step to test it.
- Schedule the step.
- Promote the step to production mode.
A change aggregate replication step produces tables that work with the
change data in the control tables, but not with the contents of the source
table.
To define a change aggregate replication step:
- Define a process object.
- Open the process object.
- Add one or more warehouse sources.
- Add one or more warehouse targets.
- Open the step notebook.
- Specify information for your step:
- In the Name field, you can type a new name for the step, or,
you can keep the name that the Data Warehouse Center automatically supplied
for the step.
- Optional: In the Administrator field, type the name of
the person who is responsible for the maintenance of this step.
- Optional: In the Description field, type a business
description for your step. This description can be a maximum of 255
characters.
- Optional: In the Notes field, type detailed information
that might be helpful to users who can access this step.
- On the Parameters page, select the columns that you want to replicate from
the Available columns list, and click >. The
columns that you select move to the Selected columns list.
The Available columns list shows only the columns that are enabled
for change capture.
If you want to include all of the items in the Available columns
list, click >>.
- Optional: Click Add Calculated Column to open a window in
which you can create derived columns. The derived columns that you
create are displayed in the Selected columns list.
- Optional: To select which rows are to be replicated, write a WHERE
statement to subselect rows.
- Optional: To add calculated columns, add a GROUP BY
statement. You can group rows according to the group defined in the
GROUP BY statement.
- On the Column Mapping page, map the output columns that result from the
SQL statement that you defined on the Parameters page to columns on your
target table. On this page, output columns from the Parameters page are
referred to as source columns. Source columns are listed on the left
side of the page. Target columns from the output table that are linked
to the step are listed on the right side of the page. Use the Column
Mapping page to perform the following tasks:
- To create a mapping, click a source column and drag it to a target
column. An arrow is drawn between the source column and the target
column.
- To delete a mapping, right-click an arrow, and click
Delete.
- If the output table is not used by any steps that are in test or
production mode, you can change the attributes of the target column. To
rename a target column, double-click the column name and type the new
name. You can also change any other attributes of the target column by
double-clicking the attribute.
- To move a target column up or down the list, select the column.
Then, click the up arrow or down arrow buttons. If the target column is
mapped to a source column, the mapping remains intact.
If the Parameters page produces no output columns, or if this step is not
linked to a target table and you did not specify automatic generation of a
default table in the Parameters page, you cannot use this page to map your
columns. Some steps will not allow you to change the column
mapping.
- On the Processing Options page, select an agent site where you want your
step to run from the Agent Site drop-down list. The
selections in this list are agent sites that are common to the source tables
and the target table.
- The Population type for replication steps can have only one value,
Replicate.
- If you want the option to run your step at any time, select the Run
on demand check box. Your step must be in test or production mode
before you can run it.
- Optional: Select the Populate externally check box if the
step is populated externally, meaning that it is started in some way other
than by the Data Warehouse Center. The step does not require any other
means of running in the Data Warehouse Center in order for you to change the
mode to production.
If the Populate externally check box is not selected, then the
step must have a schedule, be linked to a transient table that is input to
another step, or be started by another program in order for you to change the
mode to production.
- In the Retry area, specify how many times you want the step to
run again if it needs to be retried, and the amount of time that you want to
pass before the next run of the step.
- In the Replication control database field, select the control
database or subsystem that contains the replication control tables for the
Apply program.
- In the Database type list, select the database type for the
replication control database.
- In the User ID field, type the user ID to access the
replication control database.
- In the Password field, type the password for the user ID that
will access the database.
- In the Verify password field, type the password again.
- In the Subscription set name field, type the name of the
subscription set. This name can contain a maximum of 18 characters and
can be an ordinary or delimited qualifier.
- Optional: In the Apply qualifier field, type the name of
the apply qualifier. The apply qualifier name must be unique for every
replication step that is defined. If you do not specify an apply
qualifier, the Data Warehouse Center generates one for you.
- Optional: In the Event name field, type the event
name. The event name is the name of the event that is posted in the
event table that the Apply program reads. The event name must be unique
for every replication step that is defined. If you do not specify an
event name, the Data Warehouse Center generates one for you.
- In the Blocking factor field, specify the number of minutes
worth of change data that can be replicated during a subscription
cycle.
- Click OK to save your changes and close the notebook.
- Link the step to the warehouse sources.
- Link the steps to the warehouse targets.
- Promote the step to test mode.
- Run the step to test it.
- Schedule the step.
- Promote the step to production mode.
A staging table replication step produces read-only tables that contain
data from committed transactions. A source table that is used for a
staging table replication step must have a primary key. Use the DB2
Control Center to define a primary key for each table that you want to include
in a staging table replication step.
To define a staging table replication step:
- Define a process object.
- Open the process object.
- Add one or more warehouse sources.
- Add one or more warehouse targets.
- Open the step notebook.
- Specify information for your step:
- In the Name field, you can type a new name for the step.
Otherwise, you can keep the name that the Data Warehouse Center automatically
supplied for the step.
- Optional: In the Administrator field, type the name of
the person who is responsible for the maintenance of this step.
- Optional: In the Description field, type a business
description for your step. This description can be a maximum of 255
characters.
- Optional: In the Notes field, type detailed information
that might be helpful to users who can access this step.
- On the Parameters page, select the columns that you want to replicate from
the Available columns list, and click >. The
columns that you select move to the Selected columns list.
The Available columns list shows only the columns that are enabled
for change capture.
To include all of the items in the Available columns list, click
>>.
- Optional: Click Add Calculated Column to open a window in
which you can create derived columns. The derived columns that you
create are displayed in the Selected columns list.
- Optional: To select which rows are to be replicated, write a WHERE
statement to subselect rows.
- Optional: Click Staging table options to change any
properties for your table. This option is available if you choose a
replication type of Staging Table.
- On the Column Mapping page, map the output columns that result from the
SQL statement that you defined on the Parameters page to columns on your
target table. On this page, output columns from the Parameters page are
referred to as source columns. Source columns are listed on the left
side of the page. Target columns from the output table linked to the
step are listed on the right side of the page. Use the Column Mapping
page to perform the following tasks:
- To create a mapping, click a source column and drag it to a target
column. An arrow is drawn between the source column and the target
column.
- To delete a mapping, right-click an arrow, and click
Delete.
- If the output table is not used by any steps that are in test or
production mode, you can change the attributes of the target column. To
rename a target column, double-click the column name and type the new
name. You can also change any other attributes of the target column by
double-clicking the attribute.
- To move a target column up or down the list, select the column.
Then, click the up arrow and down arrow buttons. If the target column
is mapped to a source column, the mapping remains intact.
If the Parameters page produces no output columns, or if this step is not
linked to a target table and you did not specify automatic generation of a
default table in the Parameters page, you cannot use this page to map your
columns. Some steps will not allow you to change the column
mapping.
- On the Processing Options page, select an agent site where you want your
step to run from the Agent Site drop-down list. The
selections in this list are agent sites that are common to the source tables
and the target table.
- The Population type for replication steps can have only one value,
Replicate.
- If you want the option to run your step at any time, select the Run
on demand check box. Your step must be in test or production mode
before you can run it.
- Optional: Select the Populate externally check box if the
step is populated externally, meaning that it is started in some way other
than by the Data Warehouse Center. The step does not require any other
means of running in the Data Warehouse Center in order for you to change the
mode to production.
If the Populate externally check box is not selected, then the
step must have a schedule, be linked to a transient table that is input to
another step, or be started by another program in order for you to change the
mode to production.
- In the Retry area, specify how many times you want the step to
run again if it needs to be retried, and the amount of time that you want to
pass before the next run of the step.
- In the Replication control database field, select the control
database or subsystem that contains the replication control tables for the
Apply program.
- In the Database type list, select the database type for the
replication control database.
- In the User ID field, type the user ID to access the
replication control database.
- In the Password field, type the password for the user ID that
will access the database.
- In the Verify password field, type the password again.
- In the Subscription set name field, type the name of the
subscription set. This name can contain a maximum of 18 characters and
can be an ordinary or delimited qualifier.
- Optional: In the Apply qualifier field, type the name of
the apply qualifier. The apply qualifier name must be unique for every
replication step that is defined. If you do not specify an apply
qualifier, the Data Warehouse Center generates one for you.
- Optional: In the Event name field, type the event
name. The event name is the name of the event that is posted in the
event table that the Apply program reads. The event name must be unique
for every replication step that is defined. If you do not specify an
event name, the Data Warehouse Center generates one for you.
- In the Blocking factor field, specify the number of minutes
worth of change data that can be replicated during a subscription
cycle.
- Click OK to save your changes and close the notebook.
- Link the step to the warehouse sources.
- Link the steps to the warehouse targets.
- Promote the step to test mode.
- Run the step to test it.
- Schedule the step.
- Promote the step to production mode.
[ Top of Page | Previous Page | Next Page ]