 View figure.
View figure.This chapter contains syntax diagrams, semantic
descriptions, rules, and examples of the use of the SQL statements listed in
the following table.
| SQL Statement | Function | Refer to Page |
|---|---|---|
| ACQUIRE DBSPACE | Obtains and names a dbspace. | ACQUIRE DBSPACE |
| ALLOCATE CURSOR | Defines a cursor and associates it with a result set locator variable. | ALLOCATE CURSOR |
| ALTER DBSPACE | Alters the percentage of free space. Also alters the lock size of a PUBLIC dbspace. | ALTER DBSPACE |
| ALTER PROCEDURE | Alters the definition of an existing stored procedure. | ALTER PROCEDURE |
| ALTER PSERVER | Alters the definition of an existing stored procedure server. | ALTER PSERVER |
| ALTER TABLE | Adds a column to a table or manages referential constraints. | ALTER TABLE |
| ASSOCIATE LOCATORS | Obtains the RESULT SET LOCATOR value for each result set returned by a stored procedure. | ASSOCIATE LOCATORS |
| BEGIN DECLARE SECTION | Marks the beginning of a host variable declaration section. | BEGIN DECLARE SECTION |
| CALL | Invokes a stored procedure. | CALL |
| CLOSE | Closes a cursor. | CLOSE |
| Extended CLOSE | Closes a cursor defined by an Extended DECLARE CURSOR statement. | Extended CLOSE |
| COMMENT ON | Replaces or adds a comment to the description of a table, view, or column. | COMMENT ON |
| COMMENT ON PROCEDURE | Replaces or adds a comment to the description of a stored procedure identified. | COMMENT ON PROCEDURE |
| COMMIT | Terminates a logical unit of work and commits the database changes made by that logical unit of work. | COMMIT |
| CONNECT | Connects to an application server. | CONNECT (for VM) |
| CREATE INDEX | Defines an index on a table. | CREATE INDEX |
| CREATE PACKAGE | Creates a package. | CREATE PACKAGE |
| CREATE PROCEDURE | Defines a stored procedure. | CREATE PROCEDURE |
| CREATE PSERVER | Defines a stored procedure server. | CREATE PSERVER |
| CREATE SYNONYM | Defines an alternate name for a table or view. | CREATE SYNONYM |
| CREATE TABLE | Defines a table. | CREATE TABLE |
| CREATE VIEW | Defines a view of one or more tables or views. | CREATE VIEW |
| DECLARE CURSOR | Defines an SQL cursor. | DECLARE CURSOR |
| Extended DECLARE CURSOR | Defines a cursor that is to be associated with a statement that was prepared using an Extended PREPARE statement. | Extended DECLARE CURSOR |
| DELETE | Deletes zero or more rows from a table. | DELETE |
| DESCRIBE | Describes the result columns of a prepared statement. | DESCRIBE |
| Extended DESCRIBE | Describes the result columns of a SELECT statement that was prepared using an Extended PREPARE statement. | Extended DESCRIBE |
| DESCRIBE CURSOR | Obtains information about the result set that is associated with the cursor and puts that information into a descriptor. | DESCRIBE CURSOR |
| DESCRIBE PROCEDURE | Obtains information about the result sets returned by a stored procedure and puts that information into a descriptor. | DESCRIBE PROCEDURE |
| DROP | Deletes a dbspace, index, package. synonym, table, or view | DROP |
| DROP PROCEDURE | Deletes the definition of a stored procedure. | DROP PROCEDURE |
| DROP PSERVER | Deletes the definition of a stored procedure server. | DROP PSERVER |
| DROP STATEMENT | Deletes a statement from a package created with CREATE PACKAGE. | DROP STATEMENT |
| END DECLARE SECTION | Marks the end of a host variable declaration section. | END DECLARE SECTION |
| EXECUTE | Executes a prepared SQL statement. | EXECUTE |
| Extended EXECUTE | Executes an SQL statement prepared using an Extended PREPARE statement. | Extended EXECUTE |
| EXECUTE IMMEDIATE | Prepares and executes an SQL statement. | EXECUTE IMMEDIATE |
| EXPLAIN | Obtains information about the structure and execution performance of a DELETE, INSERT, UPDATE, or SELECT statement. | EXPLAIN |
| FETCH | Assigns values of a row of a result table to host variables. | FETCH |
| Extended FETCH | Assigns values of a row in a result table to host variables using a cursor defined by an Extended DECLARE CURSOR statement. | Extended FETCH |
| GRANT (Package Privileges) | Grants privilege to execute statements in a package | GRANT (Package Privileges) |
| GRANT (System Authorities) | Grants system authorities. | GRANT (System Authorities) |
| GRANT (Table Privileges) | Grants privileges on a table or view. | GRANT (Table Privileges) |
| INCLUDE | Inserts declarations into a source program. | INCLUDE |
| INSERT | Inserts zero or more rows into a table. | INSERT |
| LABEL ON | Replaces or adds a label on the description of a table, view, or column. | LABEL ON |
| LOCK DBSPACE | Either prevents concurrent processes from changing a dbspace or prevents concurrent processes from using a dbspace. | LOCK DBSPACE |
| LOCK TABLE | Either prevents concurrent processes from changing a table or prevents concurrent processes from using a table. | LOCK TABLE |
| OPEN | Opens a cursor. | OPEN |
| Extended OPEN | Opens a cursor defined by an Extended DECLARE CURSOR statement. | Extended OPEN |
| PREPARE | Prepares an SQL statement (with optional parameters) for execution within the same logical unit of work. | PREPARE |
| Extended PREPARE | Prepares an SQL statement into a package created with CREATE PACKAGE. | Extended PREPARE |
| PUT | Inserts (a row of) data into a table. | PUT |
| Extended PUT | Inserts (a row of) data into a table using a cursor defined by an Extended DECLARE CURSOR statement. | Extended PUT |
| REVOKE (Package Privileges) | Revokes the privilege to execute statements in a package. | REVOKE (Package Privileges) |
| REVOKE (System Authorities) | Revokes system authorities. | REVOKE (System Authorities) |
| REVOKE (Table Privileges) | Revokes privileges on a table or view. | REVOKE (Table Privileges) |
| ROLLBACK | Terminates a logical unit of work and backs out the database changes made by that unit of work. | ROLLBACK |
| SELECT INTO | Specifies a result table of no more than one row and assigns the values to host variables. | SELECT INTO |
| UPDATE | Updates the values of one or more columns in zero or more rows of a table. | UPDATE |
| UPDATE STATISTICS | Update statistics on tables and indexes in system catalogs. | UPDATE STATISTICS |
| WHENEVER | Defines actions to be taken on the basis of SQL return codes. | WHENEVER |
The SQL statements described in this chapter are classified as executable or nonexecutable. The Invocation section in the description of each statement indicates whether the statement is executable.
An executable statement can be invoked in three ways:
Depending on the statement, you can use some or all of these methods. The Invocation section in the description of each statement tells you which methods can be used.
A nonexecutable statement can only be embedded in an application program.
In addition to the statements described in this chapter, there is one more SQL statement construct: the select-statement. (See select-statement.) It is not included in this chapter because it is used differently from other statements.
A select-statement can be invoked in three ways:
The first two methods are called, respectively, the static and the dynamic invocation of select-statement.
The different methods of invoking an SQL statement are discussed below in more detail. For each method, the discussion includes the mechanism of execution, interaction with host variables, and testing if the execution was successful.
You can include SQL statements in a source program that will be submitted to the preprocessor. Such statements are said to be embedded in the program. An embedded statement can be placed where a similar host language statement is allowed in the program. You must precede each embedded statement with EXEC SQL.
An executable statement embedded in an application program is run every time a statement of the host language would be processed if specified in the same place. (Thus, for example, a statement within a loop is run every time the loop is processed, and a statement within a conditional construct is run only when the condition is satisfied.)
An embedded statement can contain references to host variables. A host variable referenced in this way can be used in two ways:
In particular, all references to host variables in expressions and predicates are effectively replaced by current values of the variables, that is, the variables are used as input. The treatment of other references is described individually for each statement.
All executable statements should be followed by a test of an SQL return code (see SQL Return Codes). Alternatively, you can use the WHENEVER statement (which is itself nonexecutable) to change the flow of control immediately after the execution of an embedded statement.
If the program is prepared with the NOEXIST option (see the DB2 Server for VSE & VM Application Programming manual), then objects referenced in SQL statements need not exist when the statements are prepared.
An embedded nonexecutable statement is processed only by the preprocessor. The preprocessor reports any errors encountered in the statement. The statement is never processed, and acts as a no-operation if placed among executable statements of the application program. Therefore, you should not follow such statements by a test of an SQL return code.
Your application program can dynamically build an SQL statement in the form of a character string placed in a host variable. In general, the statement is built from some data available to the program (for example, input from a terminal). The statement so constructed can be prepared for execution by means of the (embedded) statement PREPARE and processed by means of the (embedded) statement EXECUTE. Alternatively, you can use the (embedded) statement EXECUTE IMMEDIATE to prepare and process a statement in one step.
A statement that is going to be dynamically prepared must not contain references to host variables. It can instead contain parameter markers. (See PREPARE for rules concerning the parameter markers.) When the prepared statement is processed, the parameter markers are effectively replaced by current values of the host variables specified in the EXECUTE statement. (See EXECUTE for rules concerning this replacement.) After prepared, a statement can be processed several times with different values of host variables. Note that parameter markers are not allowed in EXECUTE IMMEDIATE.
The successful or unsuccessful execution of the statement is indicated by the setting of an SQL return code in the SQLCA after the EXECUTE (or EXECUTE IMMEDIATE) statement. You should check the SQL return code as described above for embedded statements. See SQL Return Codes for more information.
You can include a select-statement as a part of the (nonexecutable) statement DECLARE CURSOR. Such a statement is processed every time you open the cursor by means of the (embedded) statement OPEN. After the cursor is open, you can retrieve the result table a row at a time by successive executions of the FETCH statement.
The select-statement used in this way may contain references to host variables. These references are effectively replaced by the values that the variables have at the moment of executing OPEN.
Your application program can dynamically build a select-statement in the form of a character string placed in a host variable. In general, the statement is built from some data available to the program (for example, a query obtained from a terminal). The statement so constructed can be prepared for execution by means of the (embedded) statement PREPARE, and referenced by a (nonexecutable) statement DECLARE CURSOR. The statement is then processed every time you open the cursor by means of the (embedded) statement OPEN. After the cursor is open, you can retrieve the result table one row at a time by successive executions of the FETCH statement.
The select-statement used in that way must not contain references to host variables. It can instead contain parameter markers. (See PREPARE for rules concerning the parameter markers.) The parameter markers are effectively replaced by the values of the host variables specified in the OPEN statement. (See OPEN for rules concerning this replacement.)
A capability for entering SQL statements from a terminal is part of the architecture of the database manager. This product provides ISQL and the Database Services utility for this facility. An associated product, Query Management Facility (QMF), also provides interactive access to DB2 Server for VSE & VM databases. A statement entered in this way is said to be issued interactively. See the DB2 Server for VSE & VM Interactive SQL Guide and Reference manual and the DB2 Server for VSE & VM Database Services Utility manual for more information and examples.
A statement issued interactively must be an executable statement that does not contain parameter markers or references to host variables. These make sense only in the context of an application program.
An application program containing executable SQL statements must either provide a structure named SQLCA or a stand-alone integer variable named SQLCODE (SQLCOD in FORTRAN and RPG). An SQLCA is provided automatically in REXX and RPG. In other languages, an SQLCA can be obtained by using the INCLUDE SQLCA statement. INCLUDE SQLCA must not be used if a stand-alone SQLCODE is provided.
The SQLCA includes an integer variable named SQLCODE (SQLCOD in FORTRAN and RPG). The option of providing a stand-alone SQLCODE instead of an SQLCA allows for conformance with the ISO/ANSI SQL standard. This option can be requested with either the STDSQL(89) or NOSQLCA preprocessor option as described in the DB2 Server for VSE & VM Application Programming manual.
Regardless of whether the application program provides an SQLCA or a stand-alone variable, SQLCODE is set by the database manager after each SQL statement is processed. All IBM database managers conform to the ISO/ANSI SQL standard, as follows:
The meaning of SQLCODE values other than 0 and 100 is usually product-specific.
SQLSTATE is also set by the database manager after execution of each SQL statement. Thus, application programs can check the execution of SQL statements by testing SQLSTATE instead of SQLCODE. SQLSTATE (SQLSTT in FORTRAN and RPG) is a character string variable in the SQLCA.
SQLSTATE provides application programs with common codes for common error conditions. Furthermore, SQLSTATE is designed so that application programs can test for specific errors or classes of errors. The coding scheme is the same for all database managers and is based on the proposed ISO/ANSI SQL2 standard. See "SQLSTATEs" in the DB2 Server for VM Messages and Codes or the DB2 Server for VSE Messages and Codes manual for more information and a complete list of the possible values of SQLSTATE.
Static SQL statements can include host language or SQL comments. SQL comments are introduced by two hyphens.
These rules apply to the use of SQL comments:
For host language rules regarding the use of SQL comments, see the DB2 Server for VSE & VM Application Programming manual.
This example shows how to include comments in a statement:
CREATE VIEW PRJ_MAXPER -- projects with most support personnel
AS SELECT PROJNO, PROJNAME -- number and name of project
FROM PROJECT
WHERE DEPTNO = 'E21' -- systems support dept code
AND PRSTAFF > 1
The ACQUIRE DBSPACE statement causes the database manager to find and name an available dbspace.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
Syntax
Description
If the dbspace name of a private dbspace is qualified, the qualifier is the owner of the dbspace. Otherwise, the authorization ID of the statement is the owner of the dbspace. The owner has all privileges on the dbspace. The privileges can be granted by the owner and cannot be revoked from the owner.
If the dbspace name of a public dbspace is qualified, the qualifier must be "PUBLIC".
Example
Acquire a private dbspace in storage pool number 3 and call it FCPSPACE. Leave 25% of the space free on each page.
ACQUIRE PRIVATE DBSPACE NAMED FCPSPACE
(STORPOOL=3, PCTFREE=25)
|The ALLOCATE CURSOR statement defines a cursor and associates it with a |result set locator variable.
|Invocation
|This statement can be embedded in an application program. It is an |executable statement that can be dynamically prepared. It cannot by |issued interactively.
|Authorization
|None required.
|Syntax
|
>>-ALLOCATE--cursor-name--CURSOR FOR RESULT SET--rs-locator-variable-->
>--------------------------------------------------------------><
|Description |
|Notes |
|One restriction is that a statement identifier cannot be used for an |ALLOCATE CURSOR statement if the same statement identifier has been used for a |DECLARE CURSOR statement. For example, the following SQL statements are |not valid because the PREPARE statement uses STMT1 as an identifier for the |ALLOCATE CURSOR statement when it has already been used for a DECLARE CURSOR |statement:
|DECLARE C1 CURSOR FOR STMT1; | |PREPARE STMT1 FROM | 'ALLOCATE C2 CURSOR FOR RESULT SET ?'; INVALID
|If an ALLOCATE CURSOR statement is dynamically prepared, the DYNALC prep |option must be used for the preprocessor to successfully process any FETCH |statements issued against the allocated cursor. If the prep option is |not used, the preprocessor returns SQLCODE -504 for these FETCH statements |because the cursor was not identified by the prep.
|The following rules apply when you use an allocated cursor: |
|A rollback and an implicit and explicit close will destroy allocated |cursors. A commit destroys allocated cursors that are not defined WITH |HOLD by the stored procedure. However, note that DB2 Server for VSE |& VM does not support CURSOR WITH HOLD. Destroying an allocated |cursor closes the associated cursor in the stored procedure.
|Examples
|The statement in the following example is assumed to be in a PL/I |program.
|Define and associate cursor C1 with the result set locator variable |:loc1 and the related result set returned by the stored procedure:
| EXEC SQL ALLOCATE C1 CURSOR FOR RESULT SET :loc1
|
|
The ALTER DBSPACE statement lets you change the amount of free space that the database manager reserves on each data page, and lets you change the type of a lock on a public dbspace.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
Syntax
Description
Examples
Alter your private dbspace named FCPSPACE so that no space is reserved on any of the pages.
ALTER DBSPACE FCPSPACE (PCTFREE=0)
Alter a public dbspace named SPACE so that the pages are locked and the amount of free space is reduced to 3%.
ALTER DBSPACE PUBLIC.SPACE
(PCTFREE=3, LOCK=PAGE)
The ALTER PROCEDURE statement is used to alter the definition of an existing stored procedure. It updates the catalog and the corresponding cached information.
The STOP PROC command must be issued with the REJECT option before the ALTER PROCEDURE statement will be accepted.
Invocation
This statement can be issued from an application program or interactively. It is an executable statement that can be dynamically prepared.
Authorization
The issuer of the ALTER PROCEDURE must have DBA authority.
Syntax
ALTER PROCEDURE
>>-ALTER PROCEDURE---procedure-name----+-----------------+------>
'-AUTHID--authid--'
.-,-----------------.
V | (1)
>--------+-------------+--+------------------------------------><
'-| options |-'
Notes:
options
|--+-LANGUAGE-+-ASSEMBLE-+---------------------------------+----|
| +-C--------+ |
| +-COBOL----+ |
| '-PLI------' |
+-EXTERNAL NAME--external-program-name------------------+
+-SERVER GROUP--+-------------------+-------------------+
| '-server-group-name-' |
+-+-DEFAULT SERVER GROUP YES-+--------------------------+
| '-DEFAULT SERVER GROUP NO--' |
| (2) |
+---+-----------------+---+-GENERAL-----------------+---+
| '-PARAMETER STYLE-' | (3) | |
| '-GENERAL WITH NULLS------' |
+---STAY RESIDENT-+-NO--+-------------------------------+
| '-YES-' |
+-+-PROGRAM TYPE MAIN-----+-----------------------------+
| | (4) | |
| '-PROGRAM TYPE SUB------' |
+-RUN OPTIONS--run-time-options-------------------------+
+-RESULT--+-SET--+---integer----------------------------+
| '-SETS-' |
+-COMMIT ON RETURN-+-NO--+------------------------------+
| '-YES-' |
| (1) (5) |
+-+-NOT DETERMINISTIC-----------+-----------------------+
| | (1) (6) | |
| '-DETERMINISTIC---------------' |
| (1) |
+-+-CONTAINS SQL-----------+----------------------------+
| | (1) | |
| +-NO SQL-----------------+ |
| | (1) | |
| +-READS SQL DATA---------+ |
| | (1) | |
| '-MODIFIES SQL DATA------' |
| (1) |
+-+-NO COLLID-------------------+-----------------------+
| | (1) | |
| '-COLLID--collection-id-------' |
| (1) |
+-+-WLM ENVIRONMENT------+-name-----+-+-----------------+
| | '-(name,*)-' | |
| | (1) | |
| '-NO WLM ENVIRONMENT----------------' |
| (1) |
+-ASUTIME-------+-NO LIMIT--------+---------------------+
| '-LIMIT--integer--' |
| (1) |
+-+-------------------------------+---------------------+
| '-EXTERNAL SECURITY-+-DB2-----+-' |
| +-USER----+ |
| '-DEFINER-' |
| (1) |
'-+-NO DBINFO------+------------------------------------'
| (1) |
'-DBINFO---------'
Notes:
Only the parameters that are meaningful to DB2 Server for VSE & VM are described here. If a parameter is not specified on the ALTER PROCEDURE statement, its value is unchanged.
Description
The SERVER GROUP clause can be specified without a server group name. This provides the ability to take a stored procedure out of a named group and move it to the default group. If server-group-name is not specified, the stored procedure must be able to run in the default group. The DEFAULT SERVER GROUP clause determines whether the stored procedure can run in the default stored procedure server group.
The COMMIT operation includes the work performed by the calling application as well as the stored procedure. Any cursors that are open when the COMMIT occurs will be closed during COMMIT processing.
Examples
ALTER PROCEDURE MYPROC STAY RESIDENT NO
The ALTER PSERVER statement alters the definition of an existing stored procedure server.
The STOP PSERVER command must be issued with the NOIMPLICIT option before the ALTER PSERVER statement will be accepted.
Invocation
This statement can be issued from an application program or interactively. It is an executable statement that can be dynamically prepared.
Authorization
The issuer of the ALTER PSERVER statement must have DBA authority.
Syntax
>>-ALTER PSERVER------------------------------------------------>
.-,------------------------------.
V (1) |
>-----procedure-server----+---------------------------+--+-----><
+-GROUP--+------------+-----+
| '-group-name-' |
+-+-AUTOSTART NO--+---------+
| '-AUTOSTART YES-' |
'-DESCRIPTION--description--'
Notes:
|
Description
Examples
ALTER PSERVER SRV1 GROUP GRP2, AUTOSTART NO
The ALTER TABLE statement adds a single column to an existing table, and adds, drops, activates, or deactivates primary and foreign keys.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
To create, drop, activate, or deactivate a foreign key, the authorization ID of the statement must also hold at least one of the following on the parent table:
To drop, activate, or deactivate a primary key, the authorization ID of the statement must also hold at least one of the following on each table that has a foreign key referencing the primary key that is being dropped.
Notes: Notes:
fieldproc-block
|--FIELDPROC--program_name----+-------------------------+-------|
| .-,-----------. |
| V | |
'-(-----constant---+---)--'
primary-key-block
.-,------------------------------.
V (1) .-ASC--. |
|--PRIMARY KEY---(------------column_name--+------+--+---)------>
'-DESC-'
.-PCTFREE = 10------.
>-----+-------------------+-------------------------------------|
'-PCTFREE = integer-'
referential-constraint-block
.-,--------------.
V |
|--FOREIGN KEY--+-----------------+--(-------column_name---+---->
'-constraint_name-'
>----)--REFERENCES--table_name----+---------------------------+-|
| .-RESTRICT--. |
'-ON DELETE--+-CASCADE---+--'
'-SET NULL--'
unique-block
|--UNIQUE--+-----------------+---------------------------------->
'-constraint_name-'
.-,------------------------------.
V (1) .-ASC--. |
>----(------------column_name--+------+--+---)------------------>
'-DESC-'
.-PCTFREE = 10------.
>-----+-------------------+-------------------------------------|
'-PCTFREE = integer-'
Description
Adding the new column must not make the total byte count of all columns exceed the maximum record size of approximately 4072 bytes. For more information, see Notes.
Defining a primary key on a table sets up the table to be referenced by another table's foreign key to establish a referential constraint.
The following restrictions for ON DELETE are checked when a table is altered.
For additional information and examples of application restrictions see Definition Restrictions.
It is not possible to:
It is not a good practice to:
In these cases, a warning is issued but the duplicate specification is accepted.
Adding, dropping, activating, or deactivating keys invalidates the packages that access tables affected by these changes in the keys. When an SQL statement attempts to invoke an incorrect package, the database manager tries to dynamically rebind the package.
The characteristics of a primary key or foreign key cannot be directly altered. All specifications of the key must first be dropped and then respecified.
Examples
Add a new column named RATING, which is one character long, to the DEPARTMENT table.
ALTER TABLE DEPARTMENT
ADD RATING CHAR
Add a new column named SITE_NOTES to the PROJECT table. Create SITE_NOTES as a varying-length column with a maximum length of 1000 characters. The values of the column do not have an associated character set and therefore should not be translated.
ALTER TABLE PROJECT
ADD SITE_NOTES VARCHAR(1000) FOR BIT DATA
Assume a new table EQUIPMENT has been created with the following columns:
Column Name Data Type
EQUIP_NO INT
EQUIP_DESC VARCHAR(50)
LOCATION VARCHAR(50)
EQUIP_OWNER CHAR(3)
Add a referential constraint to the EQUIPMENT table so that the owner (EQUIP_OWNER) must be a department number (DEPTNO) that is present in the DEPARTMENT table. If a department is removed from the DEPARTMENT table, the owner (EQUIP_OWNER) values for all equipment owned by that department should become unassigned (or set to null). Give the constraint the name DEPT_EQUIP.
ALTER TABLE EQUIPMENT
ADD FOREIGN KEY DEPT_EQUIP (EQUIP_OWNER)
REFERENCES DEPARTMENT
ON DELETE SET NULL
Add a constraint to the PROJECT table to ensure that there are not two entries in the table with the same value for project name (PROJNAME).
ALTER TABLE PROJECT
ADD UNIQUE (PROJNAME)
See example 1 in CREATE INDEX for an alternate method of ensuring unique project names.
Alter a table to create log records with the partial before image for UPDATE operations where DataPropagator Capture is not capturing updates for the table:
ALTER TABLE SALARY1
DATA CAPTURE NONE
Alter a table to create log records with the full before image for UPDATE operations because DataPropagator Capture requires this information for update log records:
ALTER TABLE SALARY2
DATA CAPTURE CHANGES
|The ASSOCIATE LOCATORS statement obtains the RESULT SET LOCATOR value for |each result set data type returned by a stored procedure.
|Invocation
|This statement can be embedded in an application program. It is an |executable statement that can be dynamically prepared. It cannot by |issued interactively.
|Authorization
|None required.
|Syntax
Notes:
|
>>-ASSOCIATE----+----------------+---+-LOCATOR-------+---------->
'-| RESULT SET |-' | (1) |
'-LOCATORS------'
.-,----------------------.
V |
>-----(-----rs-locator-variable---+---)---WITH PROCEDURE-------->
>-----+-host-variable--+---------------------------------------><
'-procedure-name-'
written in Assembler, C, COBOL, and PL/I.
|Description |
|If a host-variable is specified, it must be a character-string |variable and it must not include an indicator variable. Note that the |value is not converted to uppercase.
|If procedure-name is specified, it must be an ordinary identifier, |which implies that it cannot contain blanks or special characters, and the |value is converted to uppercase. Therefore, if it is necessary to use a |lowercase name that contains blanks or special characters, then the name must |be specified in a host-variable. The procedure name must be |left-justified. The form in which a procedure name exists varies |according to the server where the procedure is stored. |
|In all of these cases the total length of the procedure name including its |implicit or explicit full path must not be longer than 254 bytes.
|For portability, the procedure name should be specified as a single token |no larger than eight bytes.
|The ASSOCIATE LOCATORS statement can only be executed against a stored |procedure that has already been invoked by the program using the SQL CALL |statement. |
|Notes |
|If the number of result set locator variables listed in the ASSOCIATE |LOCATORS statement is more than the number of locators returned by the stored |procedure, then the extra variables are assigned a value of zero.
|Examples
|The statements in the following examples are assumed to be in PL/I |programs.
|Use :loc1 and :loc2 to obtain the result set locator values |for the two result sets returned by stored procedure P1:
| EXEC SQL ASSOCIATE RESULT SET LOCATORS (:loc1, :loc2) | WITH PROCEDURE P1;
|Use :loc1 and :loc2 to obtain the result set locator values |for the two result sets returned by the stored procedure named by host |variable :hv1:
| EXEC SQL ASSOCIATE LOCATORS (:loc1, :loc2) | WITH PROCEDURE :hv1;| |
The BEGIN DECLARE SECTION statement marks the beginning of an SQL declare section where host variables must be defined.
Invocation
This statement can only be embedded in an application program. It is not an executable statement. It is not supported in REXX.
Authorization
None required.
Syntax
>>-BEGIN DECLARE SECTION--------------------------------------->< |
Description
The BEGIN DECLARE SECTION statement can be coded in the application program wherever variable declarations can appear in accordance with the rules of the host language. An SQL declare section ends with an END DECLARE SECTION statement, described on page END DECLARE SECTION.
The BEGIN DECLARE SECTION and the END DECLARE SECTION statements must be paired and may not be nested.
SQL statements (other than the 'INCLUDE text-file-name' form of the INCLUDE statement) cannot be specified within an SQL declare section.
In programs other than REXX, all variables referenced in SQL statements must be declared in one or more SQL declare sections. With the exception of Assembler, the SQL declare section must appear before the first reference to the variable. In REXX, host variables are declared without the use of these statements; meaning they are implicitly declared.
Variables declared outside an SQL declare section must not have the same name as variables declared within an SQL declare section.
In an Assembler program, define the host variables HVSMINT (smallint), HVVCHR24 (varchar(24)), and HVDEC72 (dec(7,2)).
EXEC SQL BEGIN DECLARE SECTION
HVSMINT DS H
HVVCHR24 DS H,CL24
HVDEC72 DS PL4'12345.67'
EXEC SQL END DECLARE SECTION
In a C program, define the host variables hv_smint (smallint), hv_vchar24 (varchar(24)), hv_double (float), and host structure name_structure (char(9),char(9)).
EXEC SQL BEGIN DECLARE SECTION;
static short hv_smint;
static struct hv_char {
short hv_vchar24_len;
char hv_vchar24_value[24];
} hv_vchar24;
static double hv_double;
static struct name_struct {
char lname[9];
char fname[9];
} name_structure;
EXEC SQL END DECLARE SECTION;
In a COBOL program, define the host variables HV-SMINT (smallint), HV-VCHAR24 (varchar(24)), HV-DEC72 (dec(7,2)), and host structure NAME-STRUCTURE (char(9),char(9)).
WORKING-STORAGE SECTION.
EXEC SQL BEGIN DECLARE SECTION END-EXEC.
01 HV-SMINT PIC S9(4) COMP-4.
01 HV-VCHAR24.
49 HV-VCHAR24-LENGTH PIC S9(4) COMP-4.
49 HV-VCHAR24-VALUE PIC X(24).
01 HV-DEC72 PIC S9(5)V9(2) COMP-3.
01 NAME-STRUCTURE.
05 FNAME PIC X(9).
05 LNAME PIC X(9).
EXEC SQL END DECLARE SECTION END-EXEC.
In a FORTRAN program, define the host variables HVSMINT (smallint), HVCHAR24 (char(24)), and HVDOUBLE (float).
EXEC SQL BEGIN DECLARE SECTION
INTEGER*2 HVSMINT
CHARACTER*24 HVCHAR24
REAL*8 HVDOUBLE
EXEC SQL END DECLARE SECTION
Note: Because varying-length character strings are not supported in FORTRAN, a character host variable large enough to use the largest expected value must be used.
In a PL/I program, define the host variables HV_SMINT (smallint), HV_VCHAR24 (varchar(24)), HV_DEC72 (dec(7,2)), and host structure NAME_STRUCTURE (char(9),char(9)).
EXEC SQL BEGIN DECLARE SECTION;
DCL HV_SMINT BINARY FIXED(15);
DCL HV_VCHAR24 CHAR(24) VARYING;
DCL HV_DEC72 FIXED DECIMAL(7,2);
DCL 01 NAME_STRUCTURE,
05 FNAME CHAR(9),
05 LNAME CHAR(9);
EXEC SQL END DECLARE SECTION;
The CALL statement invokes a stored procedure. The database manager uses the cached information from SYSTEM.SYSROUTINES, SYSTEM.SYSPARMS, and SYSTEM.SYSPSERVERS to process the statement.
Invocation
This statement must be embedded in an application program. It is an executable statement that cannot be dynamically prepared. However, a host variable can be specified for the procedure-name, enabling the procedure name to be resolved at run time.
Authorization
The privileges required to execute the CALL statement are determined by the application server and must be held by the owner of the package containing the CALL statement. If the server is DB2 Server for VSE & VM, that authorization ID must have at least one of the following for each of the packages associated with the stored procedure:
Syntax
>>-CALL----+-procedure-name-+----------------------------------->
'-host-variable--'
>-----+-------------------------------------+------------------><
+-(--+-------------------------+---)--+
| | .-,------------------. | |
| | V | | |
| '----+-host-variable-+--+-' |
| +-constant------+ |
| '-NULL----------' |
'-USING DESCRIPTOR--descriptor-name---'
|
Description
If procedure-name is specified it must be an ordinary identifier, which implies that it cannot contain blanks or special characters, and that the value is converted to upper case. If it is necessary to use lower case names, blanks, or special characters, the name must be specified in a host-variable.
If a host-variable is specified, it must be a character-string variable and it must not include an indicator variable. Note that the value is not converted to upper case. Procedure-name must be left-justified.
The procedure name can take one of several forms. The forms supported vary according to the server at which the procedure is stored.
The name of the procedure to execute. The name can be up to 18 characters long, and must match a value in the NAME column of the SYSTEM.SYSROUTINES catalog table.
In all these cases, the total length of the procedure name including its implicit or explicit full path must not be longer than 254 bytes.
An implicit or explicit three part name. The parts are as follows:
The external program name is assumed to be the same as the procedure-name
For portability, procedure-name should be specified as a single token no larger than 8 bytes. Note that when the SQL CALL statement is preprocessed, the database manager does not check whether the procedure is defined, or whether the caller is authorized to invoke it. This checking is done at run time only.
Each specification of a host-variable, constant, or NULL is a parameter of the CALL. If USING DESCRIPTOR is specified, each host variable described by the identified SQLDA is a parameter of the CALL. The nth parameter of the CALL corresponds to the nth parameter of the stored procedure. When the CALL statement is executed, the number of parameters of the CALL must be the same as the number of parameters expected by the stored procedure, and each pair of corresponding parameters must be consistent as explained below.
Each parameter of the stored procedure is defined at the server. In addition to attributes such as data type and length, the description of each parameter indicates how it is used by the stored procedure:
DB2 Server for VSE & VM gets the parameter descriptions from the cached information from the new catalog table SYSTEM.SYSPARMS.
Other servers might acquire parameter descriptions from other sources such as the SQL DECLARE PROCEDURE statement.
When the CALL statement is executed, the value of each parameter of the CALL defined as IN or INOUT is assigned to the corresponding parameter of the stored procedure in accordance with the DB2 Server for VSE & VM rules for assigning values to host variables. Control is then passed to the stored procedure in accordance with the calling conventions of the host language. When execution of the stored procedure is complete, the value of each parameter defined as OUT or INOUT is assigned to the corresponding parameter of the CALL in accordance with the DB2 Server for VSE & VM rules for assigning values to host variables.
| Note: | DB2 Server for VSE & VM does not support the use of structures or arrays for stored procedure parameters. |
Before the CALL statement is processed, the user must set the following fields in the SQLDA:
Notes
Examples
A package for a PL/I application exists on DB_A. A package for the stored procedure REPORT1 exists on DB_B. The SYSTEM.SYSROUTINES table on DB_B describes the procedure REPORT1 which allows nulls and has two parameters. The first parameter is defined as IN and the second as OUT. Here are some of the statements in the PL/I application that runs at DB_A:
EXEC SQL CONNECT TO DB_B;
VAR1 = 920176;
IVAR2 = -1;
EXEC SQL
CALL REPORT1(:VAR1, :VAR2 INDICATOR :IVAR2);
The CLOSE statement closes a cursor. In doing so, it stops the usage of the group of rows pointed to by the named cursor. Closing the cursor permits the database manager to release the resources associated with maintaining an open cursor.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
None required. See DECLARE CURSOR for the authorization required to use a cursor.
>>-CLOSE--cursor_name------------------------------------------>< |
Description
When the CLOSE statement is processed, the cursor must be in the open state. When the CLOSE statement is processed, the indicated cursor leaves the open state, and its active set becomes undefined. No FETCH or PUT statement can be processed on the cursor, and no DELETE or UPDATE statement can refer to its current position, until the cursor is reopened by an OPEN statement.
Notes
Explicitly closing cursors as soon as possible can improve performance.
When a CLOSE statement is processed in a program that is blocking PUTS, the remaining rows in an incomplete block are inserted. SQLERRD(3) contains the number of rows that were successfully inserted.
Note that both the COMMIT and ROLLBACK statements automatically close all cursors (except when blocking an insert cursor - a COMMIT or ROLLBACK statement issued when there is an OPEN with a blocked insert cursor results in an error). CLOSE, however, does not cause a commit or rollback operation; these operations must be coded separately.
Examples
In a COBOL program, use the cursor C1 to fetch the values from the first four columns of the EMP_ACT table a row at a time and put them in the following host variables:
Finally, close the cursor.
EXEC SQL BEGIN DECLARE SECTION END-EXEC.
77 EMP PIC X(6).
77 PRJ PIC X(6).
77 ACT PIC S9(4) COMP-4.
77 TIM PIC S9(3)V9(2) COMP-3.
EXEC SQL END DECLARE SECTION END-EXEC.
.
.
.
EXEC SQL DECLARE C1 CURSOR FOR
SELECT EMPNO, PROJNO, ACTNO, EMPTIME
FROM EMP_ACT END-EXEC.
EXEC SQL OPEN C1 END-EXEC.
EXEC SQL FETCH C1 INTO :EMP, :PRJ, :ACT, :TIM END-EXEC.
IF SQLSTATE = '02000'
PERFORM DATA-NOT-FOUND
ELSE
PERFORM GET-REST-OF-ACTIVITY UNTIL SQLSTATE IS NOT EQUAL TO '00000'.
EXEC SQL CLOSE C1 END-EXEC.
.
.
.
GET-REST-OF-ACTIVITY.
EXEC SQL FETCH C1 INTO :EMP, :PRJ, :ACT, :TIM END-EXEC.
.
.
.
The Extended CLOSE statement "closes" the cursor_name which was opened by an Extended OPEN statement.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-CLOSE--cursor_variable-------------------------------------->< |
Description
When the cursor is closed, its active set becomes undefined. No FETCH or PUT statement can be processed on the cursor, and no DELETE or UPDATE statement can refer to its current position, until the cursor is reopened by an Extended OPEN statement.
Notes
CLOSE permits the database manager to release the resources associated with maintaining an open cursor.
In most respects, the Extended CLOSE statement is identical to the CLOSE statement (CLOSE). However, in the Extended CLOSE statement, the cursor_variable is a host variable, thereby making it possible for a user to provide the cursor_variable when the program is run and to CLOSE the cursor in a logical unit of work or program other than the one in which the statement was prepared.
Examples
CLOSE :CURSOR1
The COMMENT ON statement adds or replaces comments (also called remarks) in the catalog descriptions of tables, views, or columns.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include one of the following:
>>-COMMENT ON--------------------------------------------------->
>-----+--| options_a |------------------------IS--str_constant----+>
| .-,--------------------------------. |
| V | |
'--+-table_name-+---(-----column_name--IS--str_constant---+---)-'
'-view_name--'
>--------------------------------------------------------------><
options_a
|--+-TABLE--+-table_name-+--------------+-----------------------|
| '-view_name--' |
'-COLUMN--+-table_name.column_name-+-'
'-view_name.column_name--'
|
Description
The comment is placed into the REMARKS column of the SYSTEM.SYSCOLUMNS catalog table, for the row that describes the column.
Examples
Insert a comment for the EMPLOYEE table into the catalog.
COMMENT ON TABLE EMPLOYEE
IS 'Reflects first quarter 1981 reorganization'
Insert a comment for the EMP_VIEW1 view into the catalog.
COMMENT ON TABLE EMP_VIEW1
IS 'View of the EMPLOYEE table without salary information'
Insert a comment for the EDLEVEL column of the EMPLOYEE table into the catalog.
COMMENT ON COLUMN EMPLOYEE.EDLEVEL
IS 'highest grade level passed in school'
Insert two comments into the catalog for two different columns of the EMPLOYEE table.
COMMENT ON EMPLOYEE (WORKDEPT IS 'see DEPARTMENT table for names', EDLEVEL IS 'highest grade level passed in school ')
The COMMENT ON PROCEDURE statement adds or replaces comments to the REMARKS column of the SYSTEM.SYSROUTINES catalog table for the row that describes the stored procedure identified.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The issuer must have DBA authority.
>>-COMMENT ON PROCEDURE--procedure_name----+------------------+->
'-AUTHID--authid---'
>----IS--string_constant---------------------------------------><
|
Description
Examples
Insert a comment for the STORPRC1 stored procedure into the catalog.
COMMENT ON PROCEDURE STORPRC1
IS 'Calculates project cost for the current month in person-hours'
Insert a comment for the STORPRC2 stored procedure with AUTHID USER1 into the catalog.
COMMENT ON PROCEDURE STORPRC2 USERID USER1
IS 'Calculates average turn-around time for service calls for the current week'
The COMMIT statement terminates the current logical
unit of work and commits the application server changes that were made by that logical unit of work.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that cannot be dynamically prepared.
Authorization
None required.
Syntax
.-WORK-.
>>-COMMIT--+------+--+---------+-------------------------------><
'-RELEASE-'
|
Description
For VM users, when the next SQL statement is entered, you are automatically connected with your logon user ID
to the default application server. This eliminates the need to enter a CONNECT statement to return to the system default user ID after being connected to an application server as another user ID.
For VSE interactive users, when the next SQL statement is entered, you are automatically connected to the CICS default user ID on the same application server. For VSE interactive users connected to a remote DRDA application server, when the next SQL statement is entered, you are automatically connected with your CICS signon user ID to the same application server.
For VSE batch applications, an explicit CONNECT with a user ID and password is necessary after a COMMIT RELEASE to establish an SQL user ID.
In any case, if you are connected to an application server with a user ID other than the default user ID and you enter a COMMIT without specifying RELEASE, you will remain connected to the application server under that user ID.
The COMMIT statement terminates the logical unit of work in which it is processed and initiates a new logical unit of work. All changes that were made by any of the following statements during the logical unit of work are committed:
All locks acquired by the logical unit of work are released.
All cursors that were opened during the logical unit of work are closed. All statements that were prepared during the logical unit of work using the non-extended form of the PREPARE statement are destroyed. Any cursors associated with a prepared statement that is destroyed cannot be opened until the statement is prepared again.
Notes
If a COMMIT or ROLLBACK does not immediately precede the termination of an application process, the database manager attempts to commit the work. If there are errors during the commit process, it may not be successful. It is strongly recommended that each application process explicitly ends its logical unit of work before terminating.
|The logical unit of work must be completed by using the COMMIT or |ROLLBACK statements before the CONNECT statement can be used to switch to |another user ID or application server.
|TCP/IP does not perform any security checking during a physical |connect. The Batch application requester will use the DRDA security |handshaking flows during the logical connect to perform user ID and password |verification. The physical TCP/IP connection will be deallocated and |reallocated whenever the application switches to a different user ID or server |name (using the CONNECT statement), and DRDA security handshaking flows will |be used again during the logical connect. Either of these switches will |not require the application to issue a COMMIT RELEASE or ROLLBACK |RELEASE. The Batch Resource Adapter will retain and use the current |user ID, password, and server name (unless different ones are specified with a |new CONNECT statement) after the new TCP/IP physical connection is |established. If a COMMIT RELEASE or ROLLBACK RELEASE was issued prior |to a CONNECT statement, then all user ID, password and server name information |is lost and must be supplied with the next CONNECT.
In a PL/I program, transfer a certain amount of commission (COMM) from one employee (EMPNO) to another in the EMPLOYEE table. Subtract the amount from one row and add it to the other. Use the COMMIT statement to ensure that no permanent changes are made to the database until both operations are completed successfully.
XFRCOMM: PROC OPTIONS(MAIN);
EXEC SQL BEGIN DECLARE SECTION;
DCL AMOUNT FIXED DECIMAL(5,2);
DCL FROM_EMPNO CHAR(6);
DCL TO_EMPNO CHAR(6);
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
EXEC SQL WHENEVER SQLERROR GOTO SQLERR;
EXEC SQL CONNECT TO TOROLAB3;
GET LIST (AMOUNT, FROM_EMPNO, TO_EMPNO);
EXEC SQL UPDATE EMPLOYEE
SET COMM = COMM - :AMOUNT
WHERE EMPNO = :FROM_EMPNO;
EXEC SQL UPDATE EMPLOYEE
SET COMM = COMM + :AMOUNT
WHERE EMPNO = :TO_EMPNO;
EXEC SQL COMMIT WORK;
RETURN;
SQLERR:
DISPLAY ('Unexpected Error -changes will be backed out');
PUT SKIP LIST (SQLCA);
EXEC SQL WHENEVER SQLERROR CONTINUE; /* continue if error on rollback */
EXEC SQL ROLLBACK WORK;
RETURN;
END; /* XFRCOMM */
Overall Notes
The CONNECT statement connects an application process or a user, or both, to an application server.
Invocation
This statement can only be embedded within an application program. It is an executable statement that cannot be dynamically prepared. It should be noted, however, that interactive SQL facilities, such as ISQL, provide an interface that gives the appearance of interactive execution.
Authorization
The privileges held by the authorization ID of the statement or, when specified, the authorization_name in the statement must include authorization to connect to the identified application server. If an authorization_name is specified in the statement, the appropriate password must also be specified.
>>-CONNECT------------------------------------------------------>
>-----+-------------------------------------------------------------+>
'--+-authorization_name-+---IDENTIFIED BY--+-password------+--'
'-host_variable------' '-host_variable-'
>-----+-----------------------+--------------------------------><
'-TO-+-server_name---+--'
'-host_variable-'
|
Description
An application process can only be connected to one application server at a time. This is called the current server. A default application server is established when the application requester is initialized. When an application process is started, it is implicitly connected to the default application server. The application process can explicitly connect to a different application server by issuing a CONNECT statement with the TO clause. There is no default connection for CONNECT with no options. A connection lasts until one of the following occurs:
If a host_variable is specified, it must be a character string variable with a length attribute that is not greater than 18, and an indicator variable may not be specified. (For programs written in C, if the host variable is declared as a NUL-terminated string, it must have a length attribute that is between 2 and 19.) The server_name that is contained within the host_variable must be left-justified and must not be delimited by quotation marks; if a fixed-length, it must be padded on the right with blanks if its length is less than that of the host variable.
The default is the currently active application server. If no application server is currently active, the default is the application server established by SQLINIT. (See the DB2 Server for VSE & VM Database Administration for information on SQLINIT.)
When the CONNECT statement is processed, the server_name must identify an application server described in the local directory (see the DB2 Server for VM System Administration manual) and the application process must be in the connectable state. (See Notes for information about connection states.)
If the CONNECT statement is successful:
For example, if the application server is Version 7 Release 1 of the DB2 Server for VSE & VM, the value of SQLERRP is 'ARI06010'.
When using the SQLDS protocol, SQLERRP is set to 'ARI '.
For more information on the DRDA protocol and the SQLDS protocol, see Distributed Relational Database.
If the CONNECT statement is unsuccessful because the application process is not in the connectable state or the server_name is not listed in the local directory, the connection state of the application process is unchanged. If the CONNECT statement is unsuccessful for any other reason, the application process remains in the connectable state.
This form of the CONNECT statement returns information about the current authorization ID and application server. The information is returned in the SQLERRP and SQLERRMC fields of the SQLCA as described above. This form of CONNECT:
It is a good practice for the first SQL statement processed by an application process to be the CONNECT statement.
The various clauses may be specified in the following combinations:
This returns information about the currently connected authorization ID and application server.
This switches to a new authorization ID on the currently established application server.
This switches the currently established authorization ID to a new application server.
This switches to both a new authorization ID and application server.
Only variations 1 and 2 are available in single user mode.
Table 8. CONNECT Variations Supported by Communication Protocols
| Variation | SQLDS Protocol | DRDA Protocol | Single User Mode | Multiple User Mode |
|---|---|---|---|---|
| Variation 1 | Yes | Yes | Yes | Yes |
| Variation 2 | Yes | No | Yes | Yes |
| Variation 3 | Yes | Yes | No | Yes |
| Variation 4 | Yes | No | No | Yes |
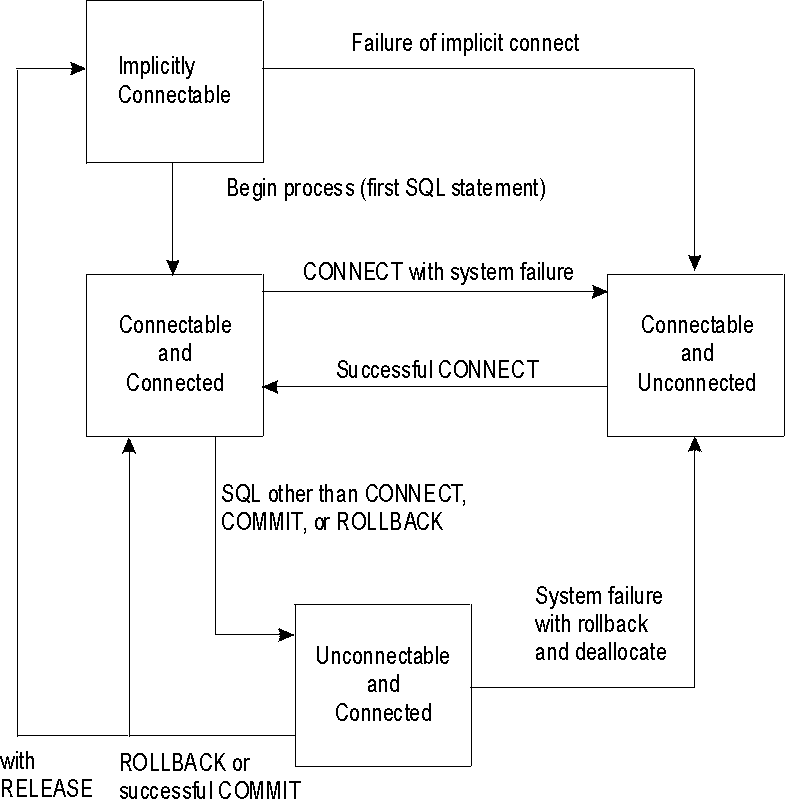
An application process is in one of four states at any time:
An application process is initially in the implicitly connectable state.
The connectable and connected state: An application process is connected to an application server and CONNECT statements can be processed. The process enters this state when it completes a rollback or successful commit from the unconnectable and connected state, or a CONNECT statement is successfully processed from the connectable and unconnected state.
The unconnectable and connected state: An application process is connected to an application server, but a CONNECT statement cannot be successfully processed to change application servers or to change authorization IDs. The process enters this state from the connectable and connected state when it processes any SQL statement other than CONNECT, COMMIT or ROLLBACK.
The connectable and unconnected state: An application process is not connected to an application server. The only SQL statement that can be processed is CONNECT. The process enters this state when an SQL statement is unsuccessful because of a failure that causes a rollback operation at the application server and the loss of the connection. The process can also enter this state if it processes a CONNECT statement unsuccessfully.
The implicitly connectable state: An application process is not connected to an application server and CONNECT statements can be processed. The process enters this state when it completes a rollback or successful commit with the release option from the unconnectable and connected state.
The following diagram shows the state transitions:
Figure 7. VM Connection State Transitions
| View figure. |
It is not an error to process consecutive CONNECT statements because CONNECT itself does not remove the application process from the connectable state. It is an error to process any SQL statement other than CONNECT, COMMIT, or ROLLBACK, and then process CONNECT with any options. To avoid the error, process a commit or rollback operation before processing the CONNECT.
A CONNECT to the current application server is treated like any other CONNECT. Such a CONNECT can cause the redundant deallocation and allocation of a conversation.
Notes
A VM user ID may be transformed when using DRDA protocol. See the DB2 Server for VM System Administration manual for more information on the CMS communications directory which may cause this transformation.
The old connection will not be disconnected until the new connection is made successfully. Two connections are therefore held for a short interval. If there are many applications running concurrently that switch application servers, this may cause a wait for sessions. If experiencing delays, use COMMIT RELEASE which will disconnect explicitly.
Examples
In a PL/I program, connect to the application server TOROLAB3.
EXEC SQL CONNECT TO TOROLAB3;
In a PL/I program, switch to a different application server called TOROLAB4. Assume your user ID on TOROLAB4 is different than the one you are currently using.
EXEC SQL BEGIN DECLARE SECTION;
DCL USERID CHAR(8);
DCL PASWRD CHAR(8);
EXEC SQL END DECLARE SECTION;
EXEC SQL CONNECT :USERID IDENTIFIED BY :PASWRD
TO TOROLAB4;
In a PL/I program, connect to an application server whose name is stored in the host variable APP_SERVER (varchar(18)). Following a successful connection, copy the 3 character product identifier of the application server to the host variable PRODUCT (char(3)).
EXEC SQL CONNECT TO :APP_SERVER; IF SQLSTATE = '00000' THEN PRODUCT = SUBSTR(SQLERRP,1,3);
Overall Notes
The CONNECT statement connects an application
process or a user, or both, to an application server.
Invocation
This statement can only be embedded within an application program. It is an executable statement that cannot be dynamically prepared. It should be noted, however, that interactive SQL facilities, such as ISQL, provide an interface that gives the appearance of interactive execution.
Authorization
The privileges held by the authorization ID of the statement or, when specified, the authorization_name in the statement must include authorization to connect to the identified application server. If an authorization_name is specified in the statement, the appropriate password must also be specified.
Description
An application process can only be connected to one application server at a time. This is called the current server. A default application server is established when the application requester is initialized. When an application process is started and a CONNECT statement is issued, the application is connected to the default application server. The application process can explicitly connect to a different application server by issuing a CONNECT statement with the TO clause. There is no default connection for CONNECT with no options. A connection lasts until one of the following occurs:
| Note: | An implicit connect is not allowed by a Batch application requester. Therefore, the user ID and password must be supplied on the CONNECT statement used for Batch application requester processing. |
If a host_variable is specified, it must be a character string variable with a length attribute that is not greater than 18, and an indicator variable may not be specified. (For programs written in C, if the host variable is declared as a NUL-terminated string, it must have a length attribute that is between 2 and 19.) The server_name that is contained within the host_variable must be left-justified and must not be delimited by quotation marks; if a fixed-length, it must be padded on the right with blanks if its length is less than that of the host variable.
The default is the application server as defined in the DBNAME directory. |If a batch application attempts the connect, then the |server_name must be one that exists in the DBNAME directory. |If it is a remote server, it must be identitified as using TCP/IP |communication. Otherwise, an SQL error will be returned to the batch |application. (See the DB2 Server for VSE System Administration manual for information on the DBNAME directory.)
When the CONNECT statement is processed, the server_name must identify an application server described in the DBNAME directory (see the DB2 Server for VSE System Administration manual) and the application process must be in the connectable state. (See Notes for information about connection states.)
If the CONNECT statement is successful:
If you are connected |using SQLDS protocol, the SQLERRP field in the SQLCA is set to 'ARI '. If you are connected using DRDA protocol, the format of SQLERRP will be pppvvrrm, where:
If the CONNECT statement is unsuccessful because the application process is not in the connectable state or the server_name is not listed in the DBNAME directory, the connection state of the application process is unchanged. If the CONNECT statement is unsuccessful for any other reason, the application process remains in the connectable state.
This form of the CONNECT statement returns information about the current authorization ID and application server. The information is returned in the SQLERRP and SQLERRMC fields of the SQLCA as described above. This form of CONNECT:
In a batch program, either
must be the first SQL statement processed by the program. If a CONNECT TO server_name statement is processed first, it must be followed by one of the other three CONNECT statements above.
|If a CONNECT with no options is processed first, the SQLERRMT fields |will be set to a blank user ID and blank server name. In this case, |there is no default application server. If the new target server is |remote, then a new DRDA connection to that remote server will be allocated and |DRDA security handshaking will be performed. If the new target server |is local, DRDA flows are not possible and an XPCC connection will be |used. A CONNECT statement with no parameters specified returns current |connection information in the SQLERRP field of SQLCA.
|If a DRDA connection exists when a CONNECT with no options is |specified, the current connection information is returned in the SQLERRP field |of the SQLCA.
One of the remaining forms from the list above is required to establish the proper identification of the user on the application server.
If a CONNECT TO server_name is processed first, the server name is placed in the CURRENT SERVER register. Also, the SQLERRMC field in the SQLCA is set with eight blanks and the server_name separated by X'FF'. However, a CONNECT authorization_name IDENTIFIED BY password must be processed to complete the connection and establish the user identification before any other SQL statements are processed.
If the TO clause is not specified, the application is connected to the default application server. |The server_name must be one that exists in the DBNAME |directory. If it is a remote server, it must be identitified as using |TCP/IP communication. Otherwise, an SQL error will be returned to the |batch application.
|TCP/IP does not perform any security checking during a physical |connect. The Batch application requester will use the DRDA security |handshaking flows during the logical connect to perform user ID and password |verification. The physical TCP/IP connection will be deallocated and |reallocated whenever the application switches to a different user ID or server |name (using the CONNECT statement), and DRDA security handshaking flows will |be used again during the logical connect. Either of these switches will |not require the application to issue a COMMIT RELEASE or ROLLBACK |RELEASE. The Batch Resource Adapter will retain and use the current |user ID, password, and server name (unless different ones are specified with a |new CONNECT statement) after the new TCP/IP physical connection is |established. If a COMMIT RELEASE or ROLLBACK RELEASE was issued prior |to a CONNECT statement, then all user ID, password and server name information |is lost and must be supplied with the next CONNECT.
If a Logical Unit of Work is ended by a COMMIT, and a CONNECT TO server_name is the next SQL statement processed, a new connection is made to the application server specified, with the user ID and password being the same as in the previous connection.
If a Logical Unit of Work is ended with a COMMIT RELEASE, the next SQL statement must be either:
to re-establish the proper user ID.
The various clauses may be specified in the following combinations:
This returns information about the currently connected authorization ID and application server.
This switches to a new authorization ID on the currently established application server.
This switches the currently established authorization ID to a new application server.
This switches to both a new authorization ID and application server.
An application process is in one of three states at any time:
An application process is connected to an application server and CONNECT statements can be processed. The process enters this state when it completes a rollback or successful commit from the unconnectable and connected state, or a CONNECT statement is successfully processed from the connectable and unconnected state.
An application process is connected to an application server, but a CONNECT statement cannot be successfully processed to change application servers or to change authorization IDs. The process enters this state from the connectable and connected state when it processes any SQL statement other than CONNECT, COMMIT or ROLLBACK.
An application process is not connected to an application server. The only SQL statement that can be processed is CONNECT. The process is initially in this state or enters this state when an SQL statement is unsuccessful because of a failure that causes a rollback operation at the application server and the loss of the connection. The process can also enter this state if it successfully completes a commit or rollback with the release option from the unconnectable and connected state or it processes a CONNECT statement unsuccessfully.
The following diagram shows the state transitions:
Figure 8. VSE Connection State Transitions
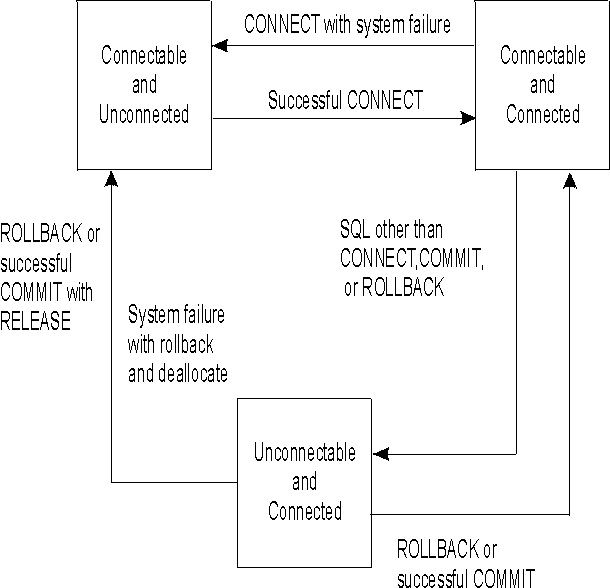 View figure. View figure. |
It is not an error to process consecutive CONNECT statements because CONNECT itself does not remove the application process from the connectable state. It is an error to process any SQL statement other than CONNECT, COMMIT, or ROLLBACK, and then process CONNECT with any options. To avoid the error, process a commit or rollback operation before processing the CONNECT.
Notes
If a program is connectable and connected, a CONNECT TO server_name results in the old connection being disconnected before the new connection is attempted. If the new connection fails, the program's state is connectable and unconnected.
A CONNECT to the same application server without changing the authorization ID is treated as a no-operation; the connection is not disconnected and reconnected.
Examples
In a PL/I program, connect to the application server TOROLAB3.
EXEC SQL CONNECT TO TOROLAB3;
In a PL/I program, switch to a different application server called TOROLAB4. Assume your user ID on TOROLAB4 is different than the one you are currently using.
EXEC SQL BEGIN DECLARE SECTION;
DCL USERID CHAR(8);
DCL PASWRD CHAR(8);
EXEC SQL END DECLARE SECTION;
EXEC SQL CONNECT :USERID IDENTIFIED BY :PASWRD
TO TOROLAB4;
In a PL/I program, connect to an application server whose name is stored in the host variable APP_SERVER (varchar(18)).
EXEC SQL CONNECT TO :APP_SERVER;
|If the CICS/VSE transaction issues an SQL CONNECT statement with the |"TO server name" clause, the server name is established explicitly for the |transaction and the Online Resource Adapter uses the DBNAME Directory to |resolve the server name to the target database.
|If the CICS/VSE transaction did not issue an SQL CONNECT statement with |the"TO server name" clause, the Online Resource Adapter attempts |to connect to the default application server, as defined in the DBNAME |Directory.
|If the target database is a Remote server and the communications protocol |to be used is SNA, the application requester issues a GDS ALLOCATE command to |acquire a session for the remote system where the server runs. The |SYSID used in this ALLOCATE command is the SYSID value from the DBNAME |Directory entry (and the SYSID must match a CEDA DEF CONNECTION |definition). Then the application requester issues a GDS CONNECT |PROCESS command to initiate an APPC basic conversation with the Remote |server. The PROCNAME used by this CONNECT PROCESS command is the REMTPN |value from the DBNAME Directory entry.
|If the target database is a Remote server and the communications protocol |to be used is TCP/IP, the application requester issues a CONNECT to the TCP/IP |listener port number that is specified by the TCPPORT value from the DBNAME |Directory entry. The target database is identified by the IPADDR or |TCPHOST values from the DBNAME Directory entry.
|If the target database is a Local or Host VM (guest sharing) server, normal |communications occurs using XPCC.
|The default application server is determined when the CIRB transaction is |invoked and can be changed subsequently by a CIRC transaction. For more |information on establishing a default application server, see DB2 Server for VSE & VM Database Administration.
|Batch applications access the Remote server in the same way as CICS |Transactions, but SNA communications protocol is not supported, only |TCP/IP. In addition, the Batch application must issue an SQL CONNECT |statement as the first SQL statement because an implicit connect is not |allowed for Batch applications.
|The communications method used to access a Remote server by CICS |applications is specified by the Communications Protocol setting in the |SQLGLOB file, which can be either SNA or TCP/IP. The remote server to |be accessed must be connected by the desired protocol. The default |protocol in the SQLGLOB Default User entry is SNA, but this can be |changed. The protocol option can be specified for each user ID in the |SQLGLOB file. For more information about the SQLGLOB file, see DB2 Server for VSE & VM Database Administration.
|The communications method used to access a remote server by Batch |applications can only be TCP/IP; SNA is not supported for Batch |applications.
|If a server is identified in the DBNAME Directory as a Remote server, it |must contain information that identifies which communications protocols can be |used to access the Remote server. Either SNA or TCP/IP information (or |both) can be specified in the DBNAME Directory. For more information |about the DBNAME Directory, see DB2 Server for VSE & |VM Database Administration.
The CREATE INDEX statement creates an index on a table.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
If the index name includes a qualifier that is not the same as the authorization ID of the statement, the privileges held by the authorization ID of the statement must include DBA authority.
>>-CREATE--+--------+--INDEX--index_name-----------------------><
'-UNIQUE-'
.-,-----------------------.
V .-ASC--. |
>>-ON--table_name--(-------column_name--+------+--+--)---------><
'-DESC-'
.-PCTFREE = 10------. >>-+-------------------+--------------------------------------->< '-PCTFREE = integer-' |
Description
The constraint is also checked during the execution of the CREATE INDEX statement. If the table already contains rows with duplicate key values, the index is not created.
When UNIQUE is used, null values are treated as any other values. For example, if the key is a single column that can contain null values, that column can contain no more than one null value. Unique indexes will not allow values which differ only by the number of trailing blanks.
If the index name is qualified, the qualifier is the owner of the index. Otherwise, the authorization ID of the statement is the owner of the index. The owner has the privilege of dropping the index.
Each column_name must be an unqualified name that identifies a column of the table. Up to 16 unique columns may be specified. Indexes cannot be created for views or for columns containing long strings.
Notes
If the named table already contains data, CREATE INDEX creates the index entries for it. If the table does not yet contain data, CREATE INDEX creates a description of the index; the index entries are created when data is inserted into the table.
The sum of the length attributes of the indexed columns, plus approximately 25% of the length attributes of any indexed columns of varying-length character type, must not exceed 255 bytes. If you are creating the index after data has been loaded into the table, a sort is invoked during the preprocessing of the CREATE INDEX command. If duplicate keys are allowed in the index, then the sort will require 4 bytes to be added to the encoded key. These four bytes are part of the 255 total bytes.
At preprocessing time, the database manager optimizer chooses which index, if any, is to be used in processing a given query or data manipulation statement. The index provides a fast means to access the table directly by the indexed columns. However, there is a slight increase in the time required to update the indexed columns because the database manager must also update the index. It is good practice to create indexes before preprocessing programs that might take advantage of them. When you create a new index, existing packages are not marked incorrect because they can still use their original access path. However, an existing program may run more efficiently by taking advantage of the new index. If this is the case, you should preprocess the program again. A new package is then created for the program, possibly using the new index.
An index is maintained by the database manager until it is explicitly dropped using a DROP INDEX statement, or until its table or dbspace is dropped.
Recovery of a CREATE INDEX statement could result in the index being marked as invalid. The database manager will end if an attempt is made to mark an index as not valid if the system limit of not valid indexes has been reached. The database manager will not allow a CREATE INDEX statement to proceed if the number of currently not valid indexes plus the number of potentially not valid indexes (currently executing CREATE INDEX statements plus DBSU REORGANIZE INDEX commands) has reached the limit.
If doing many updates to an indexed column or inserting many rows into an indexed table (as the Database Services utility does), it is often best to drop the index before doing the updates and then re-create it after the updates are complete. Because the index is not being updated while the table is being updated, this can be a significant performance improvement.
For information on how to calculate the length of an encoded key refer to the DB2 Server for VSE & VM Database Administration manual.
Examples
Create an index named UNIQUE_NAM on the PROJECT table. The purpose of the index is to ensure that there are not two entries in the table with the same value for project name (PROJNAME). The index entries are to be in ascending order.
CREATE UNIQUE INDEX UNIQUE_NAM
ON PROJECT(PROJNAME)
See example 4 in ALTER TABLE for an alternate method of ensuring unique project names.
Create an index named JOB_BY_DEPT on the EMPLOYEE table. Arrange the index entries in ascending order by job title (JOB) within each department (WORKDEPT). Leave 33 percent of the space in the index free for later insertions.
CREATE INDEX JOB_BY_DEPT
ON EMPLOYEE (WORKDEPT, JOB)
PCTFREE = 33
The CREATE PACKAGE statement creates a package.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
None required. However, a DBA authority is required to create a package that is to be owned by someone else.
Description
If the package_spec is identical to the name of an existing package and the REPLACE option is specified, the existing package is implicitly dropped and replaced with a new package.
This option can only be used when connected to a DB2 Server for VM or DB2 Server for VSE application server.
This option can only be used when connected to a DB2 Server for VM or DB2 Server for VSE application server.
This option can only be used when connected to a DB2 Server for VM or DB2 Server for VSE application server.
This option can only be used when connected to a DB2 Server for VM or DB2 Server for VSE application server.
If using DRDA protocol, ISO is the default format.
|The DATE LOCAL option is not supported for non-modifiable packages |created by using extended dynamic statements with DRDA protocol. If |specified, an error will occur indicating an incorrect parameter.
In a VM environment, RS is not directly supported by the application server. In a VSE environment, RS is not supported at all. In both VM and VSE, isolation level RS is upgraded to level RR.
(See the IBM SQL Reference manual for details on RS.)
|The ISOLATION USER option is not supported for non-modifiable |packages created by using extended dynamic statements with DRDA |protocol. If specified, USER will be overridden with CS.
KEEP causes these grants of the EXECUTE privilege to remain in effect when the new package is created. KEEP is the default.
If the REVOKE option is specified, or if the owner of the package is not entitled to grant all privileges embodied in the program, the preprocessor revokes all existing grants of the EXECUTE privilege.
If the BLocK option is specified, all eligible query cursors return results in groups of rows. All eligible insert cursors process inserts in groups of rows.
If NOBLocK is specified, rows are not grouped. This is the default.
SBLocK is primarily for use with application servers that support the FOR FETCH ONLY clause on the DECLARE CURSOR statement. The DB2 Server for VSE & VM application servers do not support this clause, but the DB2 Server for VM application requester can connect to application servers that do support FOR FETCH ONLY.
If DESCRIBE is specified, Extended DESCRIBE statements can be processed.
If NODESCRIBE is specified, these Extended DESCRIBE statements cannot be processed. This is the default. NODESCRIBE is not supported with DRDA protocol and will be changed to DESCRIBE.
If NOEXIST is specified, a warning is returned to the program if object and authorization existence is not found. This will not affect the creation of the package (for instance, if NOCHECK is in effect and everything else is valid, then the package will be created). NOEXIST is the default.
If EXIST is specified, an error is returned to the program if an object does not exist or if the authorization ID of an Extended PREPARE statement does not have the appropriate privileges on an object. In such a case, the package is not created, even if ERROR is specified. For modifiable packages, ERROR and EXIST may not be specified together.
Sections in packages created with the MODIFY option can also be processed or dropped before committing the logical unit of work in which they were prepared.
The MODIFY option should not be used if the entire package will be replaced using the REPLACE option. Once a package has been created with the MODIFY option specified, it can be changed but not replaced by subsequent CREATE PACKAGE statements. To replace a package created with the MODIFY option, it is necessary to enter a DROP PACKAGE statement and then enter a CREATE PACKAGE.
NOMODIFY is supported with DRDA protocol; however, there are some restrictions (see Appendix G, DRDA Considerations). MODIFY is not supported with DRDA protocol and will be changed to NOMODIFY. NOMODIFY is the default.
For DB2 Server for VSE & VM application servers, the authorization_name must be the same as the binder's authorization ID at the application server.
For DB2 Server for VSE & VM application servers, the collection-id must be the same as the binder's authorization ID at the application server.
If COMMIT is specified, the resources are released when a logical unit of work (LUW) is committed or rolled back. This is the default.
If DEALLOCATE is specified, the resources are released when the application process terminates.
For DB2 Server for VSE & VM application servers, the only acceptable option is RELEASE(COMMIT).
If NEW is specified, an error results if a package already exists with the same name.
If REPLACE is specified and no previous package exists with the same name, no error or warning is given. If NEW is specified along with KEEP or REVOKE, an error results.
If using DRDA protocol, ISO is the default format.
|The TIME LOCAL option is not supported for non-modifiable packages |created by using extended dynamic statements with DRDA protocol. If |specified, an error will occur indicating an incorrect parameter.
Notes
The package is stored in the database when a COMMIT is issued.
When the logical unit of work, in which the CREATE PACKAGE statement is entered, is committed (using COMMIT), a new package is created. ROLLBACK prevents the storage of the new package. A package created with the MODIFY option can be committed even if it contains no statements. Only one package may be created or modified within a logical unit of work.
Before SQL/DS Version 3 Release 1, the values for the ISOLATION, DATE, and TIME bind options were derived from the corresponding options with which the application was preprocessed. With SQL/DS Version 3 Release 1, these options became pure bind options, meaning that their values are to be based only on their specification in the CREATE PACKAGE statement. This change will only take effect after the application issuing the CREATE PACKAGE statement has been repreprocessed, reassembled, and relinked.
| Note: | For DB2 Server for VSE, if a combination of the NOBIND, BIND, or the
PACKAGE, NOPACKAGE or the CHECK, NOCHECK and ERROR was specified, the
preprocessor will generate an error message. For example, if PACKAGE,
NOPACKAGE, NOBIND, BIND were all specified, the preprocessor will display the
following error messages:
ARI0583E - Keywords PACKAGE and NOPACKAGE were both found.
- Specify only one.
ARI0583E - Keywords NOBIND and BIND were both found.
- Specify only one.
ARI0586I - Preprocessing ended with 2 errors and
- 0 warnings.
For DB2 Server for VSE, if NOBIND, NOCHECK and NOPACKAGE are all specified, no action would be taken for this preprocessing. This is considered an error and the following error messages will be displayed: ARI5411E - Keywords NOBIND, NOCHECK and NOPACKAGE are
- specified. No preprocess will be done for this
- operation.
ARI0586I - Preprocessing ended with 1 errors and
- 0 warnings.
|
|The restriction for non-modifiable packages created by using |extended dynamic statements with DRDA protocol are as follows: |
Examples
CREATE PACKAGE JERRY.MUSICIANS USING OPTIONS DESCRIBE NEW BLOCK
The CREATE PROCEDURE statement inserts the definition of a stored procedure and the parameters it requires into SYSTEM.SYSROUTINES and SYSTEM.SYSPARMS, and into the cache.
Invocation
This statement can be issued from an application program or interactively. It is an executable statement that can be dynamically prepared.
Authorization
The issuer of the CREATE PROCEDURE must have DBA authority.
Syntax
>>-CREATE PROCEDURE---procedure-name----+-----------------+--(-->
'-AUTHID--authid--'
>-----+----------------+--)------------------------------------->
'-| parameters |-'
.-,------------------------------------------------------.
| (1) |
V .-FENCED------------------------------------. | (8)
>---------+-+-------------------------------------------+-+----+----->
| +-LANGUAGE-+-ASSEMBLE-+---------------------+ |
| | +-C--------+ | |
| | +-COBOL----+ | |
| | '-PLI------' | |
| +-EXTERNAL-+------------------------------+-+ |
| | '-NAME--external-program-name--' | |
| +-SERVER GROUP--+-------------------+-------+ |
| | '-server-group-name-' | |
| | .-DEFAULT SERVER GROUP YES--. | |
| +-+---------------------------+-------------+ |
| | '-DEFAULT SERVER GROUP NO---' | |
| '-+------------------------------+----------' |
| +-PARAMETER STYLE--------------+ |
| | (3) | |
| | .-GENERAL WITH NULLS-------. | |
| |-| (2) | | |
| '-+-GENERAL------------------+-' |
| .-STAY RESIDENT NO--. |
+-+-------------------+-------------------------+
| '-STAY RESIDENT YES-' |
| .-PROGRAM TYPE MAIN-----. |
+-+-----------------------+---------------------+
| | (4) | |
| '-PROGRAM TYPE SUB------' |
+-+--------------------------------+------------+
| '-RUN OPTIONS--run-time-options--' |
| .-RESULT SET 0-------------. |
+-+--------------------------+------------------+
| '-RESULT-+-SET--+--integer-' |
| '-SETS-' |
| .-COMMIT ON RETURN NO--. |
+-+----------------------+----------------------+
| '-COMMIT ON RETURN YES-' |
| (5) |
| .-NOT DETERMINISTIC-------. |
+-+-------------------------+-------------------+
| | (6) | |
| '-DETERMINISTIC-----------' |
| (7) |
| .-CONTAINS SQL-----------. |
+-+------------------------+--------------------+
| | (7) | |
| +-NO SQL-----------------+ |
| | (7) | |
| +-READS SQL DATA---------+ |
| | (7) | |
| '-MODIFIES SQL DATA------' |
| (7) |
| .-NO COLLID-------------------. |
+-+-----------------------------+---------------+
| | (7) | |
| '-COLLID--collection-id-------' |
+-+-----------------------------------+---------+
| | (7) | |
| +-WLM ENVIRONMENT------+-name-----+-+ |
| | '-(name,*)-' | |
| | (7) | |
| '-NO WLM ENVIRONMENT----------------' |
| (7) |
| .-ASUTIME NO LIMIT-------------. |
+-+------------------------------+--------------+
| | (7) | |
| '-ASUTIME LIMIT--integer-------' |
| (7) |
| .-EXTERNAL SECURITY DB2--------------. |
+-+------------------------------------+--------+
| | (7) | |
| '-EXTERNAL SECURITY------+-USER----+-' |
| '-DEFINER-' |
| (7) |
| .-NO DBINFO-------. |
'-+-----------------+---------------------------'
| (7) |
'-DBINFO----------'
>--------------------------------------------------------------><
Notes:
Description
Only the parameters that are meaningful to DB2 Server for VSE & VM are described.
Note that the LANGUAGE clause must be specified on the CREATE PROCEDURE statement.
If external-program-name is not specified, the name of the load module or phase is assumed to be the same as the name of the stored procedure. In this case, the name of the stored procedure must be 8 characters or less. Note that the EXTERNAL clause must be specified on the CREATE PROCEDURE statement.
If SERVER GROUP is specified without server-group-name, the stored procedure must be able to run in the default server group. Note that the SERVER GROUP clause must be specified on the CREATE PROCEDURE statement.
Note that DB2 Server for VSE & VM does not support the parameter style DB2SQL.
The COMMIT operation includes the work performed by the calling application as well as the stored procedure. Any cursors that are open when the COMMIT occurs will be closed during COMMIT processing.
parameters
.-,-------------------------------------------------------------------.
V .-IN----. |
|-----+-------+---+----------------+--| data-type |-+-----------------+--+->
+-OUT---+ '-parameter-name-' | (1) |
'-INOUT-' '-AS LOCATOR------'
>---------------------------------------------------------------|
data-type
|---+-INT---------------------------------------------------------+->
+-INTEGER-----------------------------------------------------+
+-SMALLINT----------------------------------------------------+
+-REAL--------------------------------------------------------+
+-FLOAT-------------------------------------------------------+
+-DOUBLE------------------------------------------------------+
+-DOUBLE PRECISION--------------------------------------------+
+--+-DECIMAL-+---+-------------------------------+------------+
| '-DEC-----' '-(--integer--+----------+---)--' |
| '-,integer-' |
+--+-CHARACTER-+---+-----------+---+------------------------+-+
| '-CHAR------' '-(integer)-' '-FOR--+-SBCS--+---DATA--' |
| +-MIXED-+ |
| '-BIT---' |
+-VARCHAR(integer)---+------------------------+---------------+
| '-FOR--+-SBCS--+---DATA--' |
| +-MIXED-+ |
| '-BIT---' |
+-GRAPHIC(integer)--------------------------------------------+
'-VARGRAPHIC(integer)-----------------------------------------'
>---------------------------------------------------------------|
Notes:
|
The fields of the parameters syntax diagram are:
As an example, in the following parameters string:
PARM1 CHAR(10) IN, PARM2 INTEGER INOUT, PARM3 INT OUT
PARM1, PARM2, and PARM3 are identifiers for error messages. You can specify any name you want. The stored procedure associated with the PARMLIST string would expect three parameters:
Notes
Examples
CREATE PROCEDURE MYPROC (IN INT, IN PARM2 CHAR(10), OUT CHAR(20))
EXTERNAL NAME MYMOD,
LANGUAGE COBOL,
PARAMETER STYLE GENERAL
CREATE PROCEDURE MYPROC2 (IN INT, IN CHAR(10), OUT CHAR(20))
EXTERNAL NAME MYMOD2,
LANGUAGE COBOL,
PARAMETER STYLE GENERAL WITH NULLS,
RUN OPTIONS 'HEAP(,,ANY),BELOW(4K,,),ALL31(ON),STACK,(,,ANY,)'
The CREATE PSERVER statement inserts the definition of a stored procedure server into SYSTEM.SYSPSERVERS and puts the new definition into the cache.
Invocation
This statement can be issued from an application program or interactively. It is an executable statement that can be dynamically prepared.
Authorization
The issuer of the CREATE PSERVER statement must have DBA authority.
Syntax
.-,-------------------------------.
V |
>>-CREATE PSERVER--procedure-server-----+---------------------------+--+->
| (1) |
+---------------------------+
+-GROUP--group-name---------+
| .-AUTOSTART NO--. |
+-+---------------+---------+
| '-AUTOSTART YES-' |
'-DESCRIPTION--description--'
>--------------------------------------------------------------><
Notes:
|
Description
Examples
CREATE PSERVER SRV1 GROUP GRP1, AUTOSTART YES CREATE PSERVER SRV2 GROUP GRP2, AUTOSTART YES
The CREATE SYNONYM statement defines an alternative name for a table or view. This lets you refer to a table or view owned by another user without having to enter the qualified name. You may also define a synonym for a table or view that you own.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
None required.
>>-CREATE SYNONYM--synonym--FOR----+-qualified_table_name-+----><
'-qualified_view_name--'
|
Description
The synonym is defined only for your authorization ID, that is, the authorization ID of the statement. If many users want to have the same synonym, each user must enter a CREATE SYNONYM statement.
A synonym cannot be used with the table or view it represents in the same statement.
Examples
Define an alternative name, PARTS, for TRUDEAU.INVENTORY.
CREATE SYNONYM PARTS
FOR TRUDEAU.INVENTORY
The CREATE TABLE statement defines a table. You provide the name of the table and the names and attributes of its columns. Moreover, you may specify the dbspace where the table is to be created.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
The privileges held by the authorization ID of the statement must include at least one of the following:
If the table name is qualified by an identifier other than your authorization ID, you must have DBA authority.
See the description of the IN clause for further information on authorization.
Syntax
Description
If the table name is qualified, the qualifier is the owner of the table. Otherwise, the authorization ID of the statement is the owner of the table. The owner has all privileges on the table. The privileges can be granted by the owner and cannot be revoked from the owner.
If user SCOTT preprocesses a program that creates a table named SUMMARY, and user JONES runs the program, the owner of the SUMMARY table is SCOTT. Note that JONES must be a DBA to run the program. Any program preprocessed by SCOTT can refer to the SUMMARY table simply by the name SUMMARY. When another authorization ID preprocesses a program that refers to the SUMMARY table, the program must use SCOTT as a prefix to the table_name, SCOTT.SUMMARY.
In place of FLOAT(integer) you may specify either:
DECIMAL(p) can be used for DECIMAL(p,0), and DECIMAL can be used for DECIMAL(5,0).
A LONG VARCHAR column is always a long string column (even if its actual length is 254 or less).
Depending on the specification of subtypes and CCSIDs, the database manager assigns different values:
The choice of CCSID, including allowing it to default, may significantly affect performance. For performance implications related to CCSID, consult the DB2 Server for VSE & VM Performance Tuning Handbook manual.
Defining a primary key on a table sets up the table to be referenced by another table's foreign key to establish a referential constraint.
The following restriction for ON DELETE is checked when a table is created.
A newly created table is placed in one of the existing dbspaces of the database according to the following rules:
CREATE TABLE ... IN SCOTT.DSP3
The database manager places the table into any private dbspace owned by the specified authorization ID. If there is no such dbspace, an error condition results.
Table 9 summarizes where a table is placed depending on what is
specified. X represents the user ID of the person who preprocessed the
program. X is denoted as optional below because if no user ID is
specified, the creator always defaults to the user ID of the person who
preprocessed the program (X). Y represents some other user ID.
Table 9. Default table placement when user X preprocesses the program.
| DBA Authority Needed? | Table Creator | Table Name | DBSPACE Owner | DBSPACE Name | Database Manager Action |
|---|---|---|---|---|---|
| No | X | A | User X creates X.A in a private dbspace owned by X. | ||
| Yes | Y | A | User X creates Y.A in any private dbspace owned by Y. | ||
| No | X | A | X | B | User X creates X.A in X.B1 |
| Yes | A | Y | B | User X creates X.A in Y.B | |
| Yes | Y | A | B | User X creates Y.A in Y.B1 | |
| Yes | Y | A | Z | B | User X creates Y.A in Z.B |
| |||||
Concatenate the desired authorization_names to both the table_name and the dbspace_name to avoid confusion. This concatenation always identifies both the owner of the table and where the table will be placed.
Once a table has been created, the data types of its columns may not be changed, and columns may not be deleted from a table. However, new columns may be added to the table (with the ALTER TABLE statement).
The sum of the byte counts of the columns must not be greater than 4077. The list that follows gives the byte counts of columns by data type for columns that do not allow null values. For a column that allows null values the byte count is one more than shown in the list.
Actual data for a long string column is stored in its own internal table in the dbspace. Thus, each table that contains long string columns uses one of the available 255 tables in the dbspace.
Tables that are part of a referential structure must be defined in DBSPACEs that are in the same type of storage pool. That is, both parent and dependent tables in the same referential structure must be in DBSPACEs that are in either a recoverable storage pool or a nonrecoverable storage pool. If the tables are not in the same type of storage pool, any attempt to define or change a referential constraint will produce an error.
Examples
Given that you have DBA authority, create a table named 'ROSSITER.INVENTORY' with the following columns:
CREATE TABLE ROSSITER.INVENTORY
(PARTNO SMALLINT NOT NULL,
DESCRIPTION VARCHAR(24),
QONHAND INT)
Given that you have DBA authority, create the SITE1_SUPPLIERS table in the PUBLIC dbspace SPACE3 with the following columns and make KRISTEL the owner of the table:
CREATE TABLE KRISTEL.SITE1_SUPPLIERS
(SUPPNO SMALLINT NOT NULL,
NAME CHAR(15),
ADDRESS VARCHAR(15) )
IN "PUBLIC".SPACE3
Create the EQUIPMENT table in one of your private dbspaces with the following columns:
Ensure there is a unique entry in the table for each piece of equipment and order the entries in ascending order by equipment number (EQUIP_NO).
Also define a referential constraint with the table so that the equipment owner (EQUIP_OWNER) must be a department (DEPTNO) that is present in the DEPARTMENT table. If a department is removed from the DEPARTMENT table, the equipment owner values for all equipment owned by that department should become unassigned (that is, set to null). Give the constraint a name of DEPT_EQUIP.
CREATE TABLE EQUIPMENT
(EQUIP_NO INT NOT NULL,
EQUIP_DESC VARCHAR(50),
LOCATION VARCHAR(50),
EQUIP_OWNER CHAR(3),
PRIMARY KEY(EQUIP_NO),
FOREIGN KEY DEPT_EQUIP (EQUIP_OWNER)
REFERENCES DEPARTMENT
ON DELETE SET NULL )
On a DB2 Server for VM or DB2 Server for VSE application server with
mixed data supported and with a default character subtype (that is, CHARSUB)
of mixed, create a table named 'MAPS' in one of your private
dbspaces. This table is designed to be maintained from a DB2 for OS/2
application requester. The table is to have the following columns (all
values must be present):
| Column | Description | Data Stored |
|---|---|---|
| MAP_NUMBER | map number | 7 SBCS characters (to be converted to EBCDIC) |
| LAST_UPD | last update | date |
| DESC | description | up to 40 ASCII mixed (to be converted to EBCDIC) |
| MAP | the map | up to 4000 bytes (not to be converted to EBCDIC) |
CREATE TABLE MAPS
(MAP_NUMBER CHAR(7) FOR SBCS DATA NOT NULL,
LAST_UPD DATE NOT NULL,
DESC VARCHAR(40) NOT NULL,
MAP VARCHAR(4000) FOR BIT DATA NOT NULL)
Similar to example 4, except that the default character subtype in the system is SBCS.
CREATE TABLE MAPS
(MAP_NUMBER CHAR(7) NOT NULL,
LAST_UPD DATE NOT NULL,
DESC VARCHAR(40) FOR MIXED DATA NOT NULL,
MAP VARCHAR(4000) FOR BIT DATA NOT NULL)
Similar to example 5, except that not only is the default character subtype SBCS but the default CCSIDs for both SBCS and mixed are not those required in the table (the table requires an SBCS CCSID of 290 and a mixed CCSID of 5026).
CREATE TABLE MAPS
(MAP_NUMBER CHAR(7) CCSID 290 NOT NULL,
LAST_UPD DATE NOT NULL,
DESC VARCHAR(40) CCSID 5026 NOT NULL,
MAP VARCHAR(4000) FOR BIT DATA NOT NULL)
Create a table and include the partial before image on UPDATE log records because DataPropagator Capture is not capturing updates for this table:
CREATE TABLE SALARY1 .....
OR
CREATE TABLE SALARY1 .....
DATA CAPTURE NONE
Create a table and include the full before image on UPDATE log records because DataPropagator Capture requires this information for update log records:
CREATE TABLE SALARY2 .....
DATA CAPTURE CHANGES
The CREATE VIEW statement creates a view on one or more tables or views.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
If the specified view name includes a qualifier that is not the same as the authorization ID of the statement, the privileges held by the authorization ID of the statement must include DBA authority. If the view name is qualified by an identifier that is not your authorization ID, you must have DBA authority.
>>-CREATE VIEW--view_name----+----------------------------+----->
| .-,--------------. |
| V | |
'-(-----column_name---+---)--'
>----AS--subselect--+-------------------+----------------------><
'-WITH CHECK OPTION-'
|
Description
The implicit or explicit qualifier of the view_name is the owner of the view. The owner always acquires the SELECT privilege on the view, and the authority to drop the view. The SELECT may be granted to others only if the owner has the authority to grant the SELECT privilege on every table or view identified in the first FROM clause of the subselect.
If the owner has the INSERT, UPDATE, or DELETE privileges on the table or view identified in the first FROM clause of subselect, then the owner also acquires these privileges on the view being created. Only the owner of the table or view identified in the first FROM clause of the subselect can grant the privilege.
You must specify a list of column names if the result table of the subselect has duplicate column names or an unnamed column (a column derived from a constant, function, or expression).
subselect must not reference host variables. For an explanation of subselect, see Chapter 5, Queries.
The search condition of a view is the search condition specified in the first WHERE clause of the subselect used to define the view.
WITH CHECK OPTION must not be specified if the view is read-only or if its search condition includes a subquery. WITH CHECK OPTION is ignored if the view is updateable but does not have a search condition. If WITH CHECK OPTION is specified for an updateable view that does not allow inserts, the constraint only applies to updates.
If WITH CHECK OPTION is omitted, the search condition of the view is not used in the checking of any insert or update operations. The view can then be used to insert a row that does not conform to the search condition of the view and to update a row so that it no longer conforms to the search condition of the view. A row that does not conform to the search condition of a view cannot be retrieved using that view. It is also possible for this situation to exist when WITH CHECK OPTION is specified; this can happen when the view is directly or indirectly dependent on a view that was defined without the constraint.
The WITH CHECK OPTION constraint on view V is inherited by any updateable view that is directly or indirectly dependent on V. Thus, if an updateable view is defined on V, the constraint on V also applies to that view, regardless of whether WITH CHECK OPTION is specified in the definition of that view.
Consider the following updateable views:
When a row of V5 or V4 is inserted or updated, it is checked against the conjunction of the search conditions of V4 and V2. When a row of V3 or V2 is inserted or updated, it is checked against the search condition of V2. When a row of V1 is inserted or updated, it is not checked against any search condition.
FOR UPDATE OF, ORDER BY, and UNION cannot be used in the definition of a view.
A view is read-only if its definition involves any of the following:
A read-only view cannot be the object of an INSERT, UPDATE, or DELETE statement. Note that the fact that a table contains expressions does not make it a read only view. As long as the expressions reference a single base table, such a view can be used to delete rows from the base table or to update columns that are defined without expressions. Rows can also be inserted into such views if the columns defined as expressions are nullable.
If you use a 'SELECT *' clause in the view definition and then you add a column to an underlying table (with the ALTER TABLE statement), the new column will not appear in the view.
There is no specific number for the limit on the number of columns in a view, because it depends on many factors which affect this limit. A view of up to 140 columns should work in most situations.
Examples
Create a view named MA_PROJ upon the PROJECT table that contains only those rows with a project number (PROJNO) starting with the letters 'MA'.
CREATE VIEW MA_PROJ
AS SELECT * FROM PROJECT
WHERE SUBSTR(PROJNO, 1, 2) = 'MA'
Create a view as in example 1, but select only the columns for project number (PROJNO), project name (PROJNAME) and employee in charge of the project (RESPEMP).
CREATE VIEW MA_PROJ
AS SELECT PROJNO, PROJNAME, RESPEMP
FROM PROJECT
WHERE PROJNO LIKE 'MA____'
Create a view as in example 2, but, in the view, call the column for the employee in charge of the project IN_CHARGE.
CREATE VIEW MA_PROJ
(PROJNO, PROJNAME, IN_CHARGE)
AS SELECT PROJNO, PROJNAME, RESPEMP FROM PROJECT
WHERE SUBSTR(PROJNO, 1, 2) = 'MA'
Note: Even though you are changing only one of the column names, the names of all three columns in the view must be listed in the parentheses that follow MA_PROJ.
Create a view named PRJ_LEADER that contains the first four columns (PROJNO, PROJNAME, DEPTNO, RESPEMP) from the PROJECT table together with the last name (LASTNAME) of the person who is responsible for the project (RESPEMP). Obtain the name from the EMPLOYEE table by matching EMPNO in EMPLOYEE to RESEMP in PROJECT.
CREATE VIEW PRJ_LEADER
AS SELECT PROJNO, PROJNAME, DEPTNO, RESPEMP, LASTNAME
FROM PROJECT, EMPLOYEE
WHERE RESPEMP = EMPNO
Create a view as in example 4, but in addition to the columns PROJNO, PROJNAME, DEPTNO, RESEMP and LASTNAME, show the total pay (SALARY + BONUS +COMM) of the employee who is responsible. Also select only those projects with mean staffing (PRSTAFF) greater than one.
CREATE VIEW PRJ_LEADER (PROJNO, PROJNAME, DEPTNO, RESPEMP, LASTNAME, TOTAL_PAY )
AS SELECT PROJNO, PROJNAME, DEPTNO, RESPEMP, LASTNAME, SALARY+BONUS+COMM
FROM PROJECT, EMPLOYEE
WHERE RESPEMP = EMPNO AND PRSTAFF > 1
This example shows something that can happen when a view defined WITH CHECK OPTION depends on a view defined without this option. In this case, a view named VV depends on a view named WW, and WW depends on the EMPLOYEE sample table. The view definitions are as follows:
CREATE VIEW WW
AS SELECT * FROM EMPLOYEE
WHERE SALARY < 35000.00
CREATE VIEW VV
AS SELECT * FROM WW
WHERE SALARY > 30000.00
WITH CHECK OPTION
Assume both views have a single owner, who uses VV in the following UPDATE statement:
UPDATE VV SET SALARY = SALARY + 5000.00
The update applies to every row in which SALARY is greater than 30000 but less than 35000. After the update, all rows that were visible to WW have salaries greater than 35000. Such salaries conform to the search condition of VV but not to that of WW. Even so, because WW is not defined WITH CHECK OPTION, all these rows are updated. As a result, any row in EMPLOYEE that was visible to VV is now invisible to WW and is therefore also invisible to VV.
The DECLARE CURSOR statement defines the cursor through which a user may OPEN, FETCH, PUT, or CLOSE the results of a statement prepared using PREPARE. There are two types of cursor:
Invocation
This statement can only be embedded in an application program. It is not an executable statement.
Authorization
No authorization is required to use this statement except in the case of FORTRAN. Programs in these languages will fail if the authorization ID is not the same as that used to preprocess the program.
To use the OPEN statement for the cursor, the privileges held by the authorization ID of the statement are outlined below.
The cursor must always be linked to a select-statement or an insert-statement. This linked statement may be identified in one of three ways. The authorization required to manipulate the cursor varies accordingly.
Someone with DBA authority may do any of the above.
>>-DECLARE---cursor-name---CURSOR----+----------------+--FOR---->
+-WITH RETURN----+
| (1) |
'-WITH HOLD------'
>-----+-select-statement-+-------------------------------------><
'-statement-name---'
Notes:
|
Description
A cursor in the open state designates an active set (for query cursors this is also known as the cursor's result table)
and a position relative to the rows of that active set. The active set is specified by the SELECT or INSERT statement of the cursor.
A program may contain many DECLARE CURSOR statements that define different cursors and associate them with different queries or inserts. During processing of a program, several of these cursors may be in the open state at one time. The DECLARE CURSOR statement that defines a cursor must occur earlier in the program than any cursor manipulation statement operating on that cursor. The DECLARE CURSOR statement does not result in any actual processing when the program is run (that is, it does not automatically open the cursor).
The DECLARE CURSOR statement must precede all statements that explicitly reference the cursor by name.
Following is a description of each form of DECLARE CURSOR.
The select-statement must not include parameter markers, but can include references to host variables. In host languages, other than assembler and REXX, the declarations of the host variables must precede the DECLARE CURSOR statement in the source program. Host variable declarations can follow the DECLARE CURSOR statement in assembler and host variables are not declared at all in REXX.
The result table is read-only if any of the following are true:
If the select-statement of a cursor contains CURRENT DATE, CURRENT TIME, or CURRENT TIMESTAMP, all references to these special registers will yield the same value on each FETCH. This value is determined when the cursor is opened.
Example 1: In a PL/I program, use the cursor C1 to fetch the values for a given project (PROJNO) from the first four columns of the EMP_ACT table a row at a time and put them into the following host variables: EMP (char(6)), PRJ (char(6)), ACT (smallint), and TIM (dec(5,2)). Obtain the value of the project to search for from the host variable SEARCH_PRJ (char(6)).
EXEC SQL BEGIN DECLARE SECTION;
DCL EMP CHAR(6);
DCL PRJ CHAR(6);
DCL SEARCH_PRJ CHAR(6);
DCL ACT BINARY FIXED(15);
DCL TIM DEC FIXED(5,2);
EXEC SQL END DECLARE SECTION;
.
.
.
EXEC SQL DECLARE C1 CURSOR FOR
SELECT EMPNO, PROJNO, ACTNO, EMPTIME
FROM EMP_ACT
WHERE PROJNO = :SEARCH_PRJ;
EXEC SQL OPEN C1;
EXEC SQL FETCH C1 INTO :EMP, :PRJ, :ACT, :TIM;
IF SQLSTATE = '02000' THEN
CALL DATA_NOT_FOUND;
ELSE
DO WHILE (SUBSTR(SQLSTATE,1,2) = '00' | SUBSTR(SQLSTATE,1,2) = '01');
EXEC SQL FETCH C1 INTO :EMP, :PRJ, :ACT, :TIM;
END;
EXEC SQL CLOSE C1;
.
.
.
Example 2: In a PL/I program, declare a cursor named INCREASE to return from the EMPLOYEE table all the employee numbers (EMPNO), surnames (LASTNAME) and price (SALARY increased by 10 percent) of people who have the job of clerk (JOB). Order the result table in descending order by the increased salary.
EXEC SQL DECLARE INCREASE CURSOR FOR
SELECT EMPNO, LASTNAME, SALARY * 1.1
FROM EMPLOYEE
WHERE JOB = 'CLERK'
ORDER BY 3 DESC;
Example 3: In a PL/I program, declare a cursor named UP_CUR to update all the columns of the DEPARTMENT table.
EXEC SQL DECLARE UP_CUR CURSOR FOR
SELECT *
FROM DEPARTMENT
FOR UPDATE OF DEPTNO, DEPTNAME, MGRNO, ADMRDEPT;
Example 4: In a PL/I program, declare a cursor named DEL_CUR to examine, and potentially delete, rows in the DEPARTMENT table.
EXEC SQL DECLARE DEL_CUR CURSOR FOR
SELECT *
FROM DEPARTMENT;
Once a cursor has been defined and opened, you may insert new rows into the table using the PUT statement.
This example shows portions of a pseudo COBOL program. In this program, use the cursor C2 to insert a row into the DEPARTMENT table based on the values in the host variables DPT_NO (char(3), DPT_NM (varchar(29)), MGR_NO (char(6)), and DPT_AD (char(3)).
* in working storage:
EXEC SQL BEGIN DECLARE SECTION END-EXEC.
77 DPT-NO PIC X(3).
77 MGR-NO PIC X(6).
77 DPT-AD PIC X(3).
01 DPT-NM.
49 DPT-NM-LEN PIC S9(4) COMP VALUE +29.
49 DPT-NM-VAL PIC X(29) VALUE SPACES.
EXEC SQL END DECLARE SECTION END-EXEC.
* at start of processing:
EXEC SQL DECLARE C2 CURSOR FOR
INSERT INTO DEPARTMENT
VALUES (:DPT-NO, :DPT-NM, :MGR-NO, :DPT-AD) END-EXEC.
EXEC SQL OPEN C2 END-EXEC.
* loop as many times as necessary:
* solicit values from screen and assign to DPT-NO, DPT-NM, MGR-NO, DPT-AD
EXEC SQL PUT C2 END-EXEC.
* at end of processing
EXEC SQL CLOSE C2 END-EXEC.
This example is similar to Example 1 under DECLARE CURSOR for SELECT. The difference is that the right hand side of the WHERE clause is to be specified dynamically; thus the entire select-statement is placed into a host variable and dynamically prepared.
EXEC SQL BEGIN DECLARE SECTION;
DCL EMP CHAR(6);
DCL PRJ CHAR(6);
DCL SEARCH_PRJ CHAR(6);
DCL ACT BINARY FIXED(15);
DCL TIM DEC FIXED(5,2);
DCL SELECT_STMT CHAR(200) VARYING;
EXEC SQL END DECLARE SECTION;
SELECT_STMT = 'SELECT EMPNO, PROJNO, ACTNO, EMPTIME ' ||
'FROM EMP_ACT ' ||
'WHERE PROJNO = ?';
.
.
.
EXEC SQL PREPARE SELECT_PRJ FROM :SELECT_STMT;
EXEC SQL DECLARE C1 CURSOR FORSELECT_PRJ;
EXEC SQL OPEN C1 USING :SEARCH_PRJ;
EXEC SQL FETCH C1 INTO :EMP, :PRJT, :ACT, :TIM;
IF SQLSTATE = '02000' THEN
CALL DATA_NOT_FOUND;
ELSE
DO WHILE (SUBSTR(SQLSTATE,1,2) = '00' | SUBSTR(SQLSTATE,1,2) = '01');
EXEC SQL FETCH C1 INTO :EMP, :PRJ, :ACT, :TIM;
END;
EXEC SQL CLOSE C1;
.
.
.
The following statements could be included in a stored procedure. If the cursors are opened and not closed, the result sets are returned to the requester.
EXEC SQL DECLARE CURS1 CURSOR WITH RETURN FOR
SELECT A.X,Y,Z FROM TABLEX A, TABLEY B WHERE A.X = B.X
EXEC SQL DECLARE CURS2 CURSOR WITH RETURN FOR STMT1
Overall Notes
The scope of cursor_name is the source program in which it is defined; that is, the program submitted to the preprocessor. Thus, you can only reference a cursor by statements that are preprocessed with the cursor declaration. For example, a program called from another separately preprocessed program cannot use a cursor that was opened by the calling program.
The NOFOR preprocessor option concerns the use of the UPDATE clause when a cursor is declared for a static (embedded) query. With NOFOR in effect, this clause is optional. When the clause is used, updates are restricted to the columns designated within it. NOFOR is only useful when the UPDATE statements are static. See the DB2 Server for VSE & VM Application Programming manual for more details on the NOFOR preprocessor option.
The Extended DECLARE CURSOR statement defines the cursor through which a user may OPEN, FETCH, PUT, or CLOSE the results of a statement prepared using Extended PREPARE. There are two types of cursor:
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-DECLARE--cursor_variable--CURSOR FOR--section_variable-------> >----IN--package_spec------------------------------------------>< |
Description
Notes
Cursors are associated with a prepared select-statement or insert-statement by the value returned in the section_variable and the package_spec specified in the Extended DECLARE CURSOR statement. Extended DECLARE CURSOR may be used for any select-statement or insert-statement in a package created using the CREATE PACKAGE statement.
A cursor name used in a WHERE CURRENT OF clause of a DELETE statement or an UPDATE statement cannot be specified from a host variable. Therefore, at execution time, the content of cursor_name in the Extended DECLARE CURSOR statement must be the same as the cursor_name hard-coded in the WHERE CURRENT OF clause.
After the Extended DECLARE CURSOR statement is entered, a cursor is established; the cursor can then be opened and used to retrieve or insert rows through the Extended OPEN, FETCH, and PUT statements.
Examples
DECLARE :CURSOR1 CURSOR FOR :STMID IN :USERID.:PACKNAME
The DELETE statement deletes rows from a table or view. Deleting a row from a view deletes the row from the table on which the view is based.
There are two forms of this statement:
Invocation
A Searched DELETE statement can be embedded in an application program or issued interactively. A Positioned DELETE must be embedded in an application program. Both Searched DELETE and Positioned DELETE are executable statements that can be dynamically prepared.
A Positioned DELETE in FORTRAN, and programs prepared using extended dynamic SQL cannot be used with the DRDA protocol.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
The DELETE privilege on a view is only inherent in DBA authority. Ownership of a view does not necessarily include the DELETE privilege on the view because the privilege may not have been granted when the view was created, or it may have been granted, but subsequently revoked.
If the search-condition includes a subquery, the privileges designated by the authorization ID of the statement must also include the SELECT privilege on every table or view identified in the subquery. The privilege may have been explicitly granted or may be inherent in another privilege. The SELECT privilege on a table or view is inherent in DBA authority and ownership of a table or view.
Description
| Note: | Someone with DBA authority may delete rows from a few of the catalog tables. See Updateable Columns. |
The search_condition is applied to each row of the table or view and the deleted rows are those for which the result of the search_condition is true.
If the search condition contains a subquery, the subquery can be thought of as being processed each time the search condition is applied to a row, and the results used in applying the search condition. In actuality, a subquery with no correlated references is processed once, whereas a subquery with a correlated reference may have to be processed once for each row.
The following restriction is enforced when a DELETE statement is prepared or preprocessed with a WHERE clause containing a subquery. Let T2 denote the object table of a DELETE statement, and let T1 denote a table that is referenced in the FROM clause of a subquery of that statement, T1 must not be a table that can be affected by the DELETE on T2. The following example demonstrates the relationships.
DELETE FROM T2 WHERE FIELD2 IN (SELECT FIELD1 FROM T1);
The following rules apply to the above situation:
The default isolation level of the statement is the isolation level of the package. WITH can only be specified on a SEARCHED delete; it is incompatible with the WHERE CURRENT OF clause.
The table or view specified must also be specified in the FROM clause of the SELECT statement of the cursor, and the result table of the cursor must not be read-only. (For an explanation of read-only result tables, see DECLARE CURSOR.)
When the DELETE statement is processed, the cursor must be positioned on a row; that row is the one deleted. The cursor goes into a between state in which it remains open but has no current row until you reposition it with a FETCH statement. You cannot use the cursor for further deletions or updates while it is in the between state.
To maintain data integrity between tables when data is deleted from a parent table, the database manager checks that delete rules are followed. The delete rule in a referential constraint clause defines what action should be taken by the system when a parent row is deleted. The delete rules are:
Notes
If an error occurs during the execution of any delete operation, no rows are deleted. If an error occurs during the execution of a Positioned DELETE, the position of the cursor is unchanged. However, it is possible for an error to make the position of the cursor incorrect, in which case the cursor is closed. It is also possible for a delete operation to cause a rollback, in which case the cursor is closed.
If an error occurs during the execution of a Searched DELETE, it is necessary to inspect SQLWARN6 to determine the extent of the failure. The following are current settings of SQLWARN6 along with possible responses:
The application can do one of the following:
Unless appropriate locks already exist, one or more exclusive locks are acquired by executing a successful DELETE statement. Until the locks are released, they can prevent other application processes from performing operations on the table. For further information about locking, see the description of the COMMIT WORK, ROLLBACK WORK, LOCK TABLE, and LOCK DBSPACE statements. The isolation level associated with the application process defines the degree to which rows deleted by one process are visible to other concurrent processes.
If an application process deletes a row on which any of its cursors are positioned, those cursors are positioned before the next row of their result table. Let C be a cursor that is positioned before row R (as a result of an OPEN, a DELETE through C, a DELETE through some other cursor, or a searched DELETE). In the presence of INSERT, UPDATE, and DELETE operations that affect the base table from which R is derived, the next FETCH operation referencing C does not necessarily position C on R. For example, the operation can position C on R', where R' is a new row that is now the next row of the result table.
When a DELETE statement is completed, the number of rows deleted is returned in SQLERRD(3) in the SQLCA. The value in SQLERRD(3) does not include the number of rows that were deleted as a result of a CASCADE delete rule.
SQLERRD(5) in the SQLCA shows the number of rows affected by referential constraints. It includes rows that were deleted as a result of a CASCADE delete rule and rows in which foreign keys were set to NULL as the result of a SET NULL delete rule.
If you preprocess your program with the BLOCK option, and you wish to process a Positioned DELETE dynamically, the cursor must be a SELECT...FOR UPDATE statement, even if you do not plan to process any updates with the cursor. The FOR UPDATE clause is needed to tell the database manager that blocking should be overridden when the SELECT statement is prepared. If you do not use the FOR UPDATE clause in this instance, an error will occur on your DELETE statement at execution time.
Examples
Delete department (DEPTNO) 'D11' from the DEPARTMENT table.
DELETE FROM DEPARTMENT
WHERE DEPTNO = 'D11'
Delete all the departments from the DEPARTMENT table (that is, empty the table).
DELETE FROM DEPARTMENT
Use a PL/I program statement to delete all the subprojects (MAJPROJ is NULL) from the PROJECT table for a department (DEPTNO) equal to that in the host variable HOSTDEPT (char(6)).
EXEC SQL DELETE FROM PROJECT
WHERE DEPTNO = :HOSTDEPT AND MAJPROJ IS NULL;
Code a portion of a PL/I program that will be used to display retired employees (JOB) and then, if requested to do so, remove certain employees from the EMPLOYEE table.
EXEC SQL DECLARE C1 CURSOR FOR
SELECT *
FROM EMPLOYEE
WHERE JOB = 'RETIRED';
EXEC SQL OPEN C1;
EXEC SQL FETCH C1 INTO ... ;
PUT ... ;
GET LIST (REMOVE);
IF REMOVE = 'YES' THEN
EXEC SQL DELETE FROM EMPLOYEE
WHERE CURRENT OF C1;
EXEC SQL CLOSE C1;
The DESCRIBE statement obtains information about a prepared statement. It is primarily used for describing a SELECT statement. For an explanation of prepared statements, see PREPARE.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
None required. See PREPARE for the authorization required to create a prepared statement.
>>-DESCRIBE--statement_name--INTO--descriptor_name-------------->
>-----+-------------------+------------------------------------><
| .-NAMES--. |
'-USING--+-ANY----+-'
+-BOTH---+
'-LABELS-'
|
Description
When the DESCRIBE statement is processed, the database manager assigns values to the variables of the SQLDA as follows:
For a non-SELECT statement, 0.
If the value of SQLD is n, where n is greater than 0 but less than or equal to the value of SQLN, values are assigned to the first n occurrences of SQLVAR so that the first occurrence of SQLVAR contains a description of the first column of the result table, the second occurrence of SQLVAR contains a description of the second column of the result table, and so on.
In cases where the USING clause is set to BOTH, the database manager returns twice as many SQLVAR entries as there are columns in the select list. Given that there are n columns, the first n SQLVAR entries are for column names and the second n entries are for column labels.
If no column name is returned, the following rules govern the content and format of the SQLNAME field.
If the select list item involves:
Notes
Before the DESCRIBE statement is processed, the value of SQLN must be set to indicate how many occurrences of SQLVAR are provided in the SQLDA and enough storage must be allocated to contain SQLN occurrences. To obtain the description of the columns of the result table of a prepared SELECT statement, the number of occurrences of SQLVAR must not be less than the number of columns.
Among the possible ways to allocate the SQLDA are the three described below.
Allocate an SQLDA with enough occurrences of SQLVAR to accommodate any select list that the application will have to process. At the extreme, the number of SQLVARs could equal the maximum number of columns allowed in a result table. Having done the allocation, the application can use this SQLDA repeatedly.
This technique uses a large amount of storage that is never deallocated, even when most of this storage is not used for a particular select list.
Repeat the following two steps for every processed select list:
This technique allows better storage management than the first technique, but it doubles the number of DESCRIBE statements.
Allocate an SQLDA that is large enough to handle most, and perhaps all, select lists but is also reasonably small. If an execution of DESCRIBE fails because the SQLDA is too small, allocate a larger SQLDA and process DESCRIBE again. For the new SQLDA, use the value of SQLD returned from the first execution of DESCRIBE for the number of occurrences of SQLVAR.
This technique is a compromise between the first two techniques. Its effectiveness depends on a good choice of size for the original SQLDA.
Examples
In a PL/I program, process a DESCRIBE statement with an SQLDA that has no occurrences of SQLVAR. If SQLD is greater than zero, use the value to allocate an SQLDA with the necessary number of occurrences of SQLVAR and then process a DESCRIBE statement using that SQLDA.
EXEC SQL BEGIN DECLARE SECTION;
DCL STMT1_STR CHAR(200) VARYING;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLDA;
EXEC SQL DECLARE DYN_CURSOR CURSOR FOR STMT1_NAME;
... /* code to prompt user for a query, then to generate */
/* a select-statement in the STMT1_STR */
EXEC SQL PREPARE STMT1_NAME FROM :STMT1_STR;
... /* code to set SQLN to zero and to allocate the SQLDA */
EXEC SQL DESCRIBE STMT1_NAME INTO :SQLDA;
... /* code to check that SQLD is greater than zero, to set */
/* SQLN to SQLD, then to re-allocate the SQLDA */
EXEC SQL DESCRIBE STMT1_NAME INTO :SQLDA;
... /* code to prepare for the use of the SQLDA */
EXEC SQL OPEN DYN_CURSOR;
... /* loop to fetch rows from result table */
EXEC SQL FETCH DYN_CURSOR USING DESCRIPTOR :SQLDA;
.
.
.
The Extended DESCRIBE statement obtains information about a select-statement prepared by an Extended PREPARE statement.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-DESCRIBE--section_variable--IN--package_spec----------------->
>----INTO--descriptor_name--+-------------------+--------------><
| .-NAMES--. |
'-USING--+-ANY----+-'
+-BOTH---+
'-LABELS-'
|
Description
The DESCRIBE option must have been specified on the CREATE PACKAGE statement that was used to create the package.
Examples
DESCRIBE :STMID IN :USERID.:PACKNAME INTO MYSQLDA
|The DESCRIBE CURSOR statement obtains information about the result set that |is associated with the cursor. The information, such as column |information, is put into a descriptor. Use DESCRIBE CURSOR for result |set cursors from stored procedures. The cursor must be defined with the |ALLOCATE CURSOR statement.
|Invocation
|This statement can be embedded in an application program only. It is |an executable statement that cannot be dynamically prepared.
|Authorization
|None required.
|Syntax
|
>>-DESCRIBE CURSOR--+-cursor-name---+---INTO--descriptor-name--><
'-host-variable-'
|Description |
|If a host-variable is specified, the following rules apply: |
| Note: | DB2 Server for VSE & VM does not support CURSOR WITH HOLD. As a result, neither does its requester. If a cursor is opened WITH HOLD by a stored procedure, it will be implicitly closed by the DB2 Server for VSE & VM requester when the unit of work is committed. |
|Notes |
|Examples
|The statements in the following examples are assumed to be in PL/I |programs.
|Place information about the result set associated with cursor C1 into |the descriptor named by :sqlda1:
| EXEC SQL DESCRIBE CURSOR C1 INTO :sqlda1
|Place information about the result set associated with the cursor named |by :hv1 into the descriptor named by :sqlda2:
| EXEC SQL DESCRIBE CURSOR :hv1 INTO :sqlda2
|
|
|The DESCRIBE PROCEDURE statement obtains information about the result sets |returned by a stored procedure. The information, such as the number of |result sets, is put into a descriptor.
|Invocation
|This statement can be embedded in an application program only. It is |an executable statement that cannot be dynamically prepared.
|Authorization
|None required.
|Syntax
|
>>-DESCRIBE PROCEDURE--+-host-variable--+---INTO--descriptor-name-->
'-procedure-name-'
>--------------------------------------------------------------><
|Description |
|If a host-variable is specified, it must be a character-string |variable and it must not include an indicator variable. Note that the |value is not converted to uppercase. |Procedure name must be left-justified.
|If procedure-name is specified, it must be an ordinary identifier, |which implies that it cannot contain blanks or special characters, and the |value is converted to uppercase. Therefore, if it is necessary to use a |lowercase name that contains blanks or special characters, then the name must |be specified in a host variable. The form in which a procedure name |exists varies according to the server where the procedure is stored. |
|In all of these cases the total length of the procedure name including its |implicit or explicit full path must not be longer than 254 bytes.
|When the DESCRIBE PROCEDURE statement is processed, the database manager |assigns values to the variables of the SQLDA as follows: |
|Notes |
|Examples
|The statements in the following examples are assumed to be in PL/I |programs.
|Place information about the result sets returned by stored procedure P1 |into the descriptor named by :sqlda1:
| EXEC SQL DESCRIBE PROCEDURE P1 INTO :sqlda1
|Place information about the result sets returned by stored procedure |named by :hv1 into the descriptor named by :sqlda2:
| EXEC SQL DESCRIBE PROCEDURE :hv1 INTO :sqlda2
|
|
The DROP statement deletes an object. Any objects that are directly or indirectly dependent on that object are also deleted. Whenever an object is deleted, its description is deleted from the catalog and any packages that reference the object are invalidated.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
>>-DROP----+-DBSPACE--dbspace_name-------+---------------------><
+-INDEX--index_name-----------+
| (1) |
+-PACKAGE-------package_spec--+
+-SYNONYM--synonym------------+
+-TABLE--table_name-----------+
'-VIEW--view_name-------------'
Notes:
|
Description
An index created by a primary key cannot be dropped.
DROP PACKAGE cannot support a qualified host structure subfield name in the package_spec. A host structure subfield name may be used here as a normal host_variable but must be unqualified. If being unqualified results in an ambiguous reference, the subfield identifier name cannot be used with DROP PACKAGE.
If the package was created using a host identifier which was not an ordinary identifier (such as a package name beginning with a number), it must be dropped using a host identifier; otherwise an SQL error will result. For example, if a package named 071PACK was created using a host identifier and a
DROP PACKAGE 071PACK
statement is issued, an SQLCODE of -105 (SQLSTATE of 37501) will result.
Dropping a synonym has no effect on the table or view that it references. Dropping a synonym does not affect the packages of existing programs that use the synonym, because in the packages the synonym has already been resolved to a real table name. However, a program containing a dropped synonym cannot be preprocessed successfully, either automatically or by user request.
All existing packages affected by dropping the table are marked unusable. The unusable packages remain in the database until they are explicitly dropped by a DROP PACKAGE statement. When an SQL statement attempts to invoke an unusable package, the database manager tries to dynamically rebind the package. However, if the SQL statement refers to a dropped DBSPACE or table, that SQL statement returns an error code at execution time.
All existing packages that use the dropped view are marked unusable.
Notes
If a DROP statement is issued for an object while some program that depends on the object is running and has a logical unit of work in progress, the DROP statement does not take effect until the end of the running logical unit of work. Meanwhile, the program that has issued the DROP waits.
When dropping a table, the database manager temporarily requires additional space so it can restore the table in case the logical unit of work is not committed. The database manager behaves as though a table approximately doubles in size immediately before it is dropped. The empty pages are taken from the DBSPACE from which the table was dropped. If the number of empty pages is less than approximately double the table size, the database manager will stop processing and will not issue a ROLLBACK. Note that if all rows of a table have previously been deleted, such additional space is not required.
Examples
Drop your table named MY_IN_TRAY.
DROP TABLE MY_IN_TRAY
Drop your view named MA_PROJ.
DROP VIEW MA_PROJ
Drop the package named PACKA.
DROP PACKAGE PACKA
Drop the dbspace named MYSPACE that is owned by MIKE. (Note that the authorization id submitting this statement must have DBA authority.)
DROP DBSPACE MIKE.MYSPACE
The DROP PROCEDURE statement removes the definition of a stored procedure from the database manager, and takes the information for that procedure out of the cache.
The STOP PROC command must be issued with the REJECT option before the DROP PROCEDURE statement will be accepted.
Invocation
This statement can be issued from an application program or interactively. It is an executable statement that can be dynamically prepared.
Authorization
The issuer of the DROP PROCEDURE statement must have DBA authority.
Syntax
>>-DROP PROCEDURE---procedure-name----+-----------------+------->
'-AUTHID--authid--'
>-----+----------+---------------------------------------------><
'-RESTRICT-'
|
Description
Note that DROP PROCEDURE removes the definition of the procedure only; the package associated with the procedure, as well as the load module or phase, is untouched.
Examples
DROP PROCEDURE MYPROC
The DROP PSERVER statement removes the definition of a stored procedure server from the database manager, and takes the information for that server out of the cache.
The STOP PSERVER command must be issued with the NOIMPLICIT option before the DROP PSERVER statement will be accepted.
A stored procedure server cannot be dropped if the following are all true:
| Note: | If the drop fails for this reason, issue the ALTER PROCEDURE statement and use the SERVER GROUP clause to indicate that the procedure is to be moved to a different group, then issue the DROP PSERVER statement again. |
Invocation
This statement can be issued from an application program or interactively. It is an executable statement that can be dynamically prepared.
Authorization
The issuer of the DROP PSERVER statement must have DBA authority.
Syntax
>>-DROP PSERVER---procedure-server----------------------------->< |
Description
Examples
DROP PSERVER SRV1
The DROP STATEMENT statement selectively deletes a statement from a package. DROP STATEMENT applies only to packages created with a CREATE PACKAGE statement with the MODIFY option.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-DROP STATEMENT--section_variable--IN--package_spec---------->< |
Description
Notes
When a statement references an incorrect package, dynamic re-preprocessing will occur to restore the package to a usable state. If the package has any unresolved dependencies, the re-processing will fail and a message will be issued.
Examples
DROP STATEMENT :STMID IN :USERID.:PACKNAME
The END DECLARE SECTION statement marks the end of a host variable declare section.
Invocation
This statement can only be embedded in an application program. It is not an executable statement. It is not supported in REXX.
Authorization
None required.
Syntax
>>-END DECLARE SECTION----------------------------------------->< |
Description
See BEGIN DECLARE SECTION for a description of the END DECLARE SECTION statement.
Example
See BEGIN DECLARE SECTION for examples using the END DECLARE SECTION statement.
The EXECUTE statement processes a prepared SQL statement.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
See PREPARE for the authorization required to create a prepared statement.
>>-EXECUTE--statement_name-------------------------------------->
>-----+------------------------------------+-------------------><
+-USING----host_variable_list--------+
'-USING DESCRIPTOR--descriptor_name--'
|
Description
The total number of host variables and host structure subfields must be the same as the number of parameter markers in the prepared statement. The nth variable or subfield corresponds to the nth parameter marker in the prepared statement.
Before the EXECUTE statement is processed, the user must set the following fields in the SQLDA:
The SQLDA must have enough storage to contain all SQLVAR occurrences. Therefore, the value in SQLDABC must be greater than or equal to 16 + SQLN*(44).
SQLD must be set to a value greater than or equal to zero and less than or equal to SQLN. It must be the same as the number of parameter markers in the prepared statement. The nth variable described by the SQLDA corresponds to the nth parameter marker in the prepared statement. (For a description of an SQLDA, see SQL Descriptor Area (SQLDA).)
Before the prepared statement is processed, each parameter marker in the statement is effectively replaced by its corresponding host variable or host structure subfield. The replacement is an assignment operation in which the source is the value of the host variable or host structure subfield and the target is a variable within the database manager. The assignment rules are those described for assignment to a column in Assignments and Comparisons. The attributes of the target variable depend on the role that the parameter marker plays in its SQL statement. The rules for the various roles are shown below. In those rules, "P" represents the parameter marker in question.
When P is an operand for an infix operator, the other operand cannot also be a parameter marker. The data type, scale, and precision of the target for P are the same as those of the other operand. When P is the operand of unary minus, the data type of the target is double precision floating point.
The Pattern in a LIKE Predicate: With P in this role, the target is a varying length string.
Comparand: In this case, P can be a comparand in a basic predicate (for example, "?>10"), in an IN predicate, or in a BETWEEN predicate. At least one of the comparands in such a predicate must not be a parameter marker.
For a basic predicate, the other comparand cannot be a parameter marker.
When the parameter marker is specified as a comparison operand in the BETWEEN predicate,
When the parameter marker is specified as a comparison operand in the IN predicate,
The attributes of the target for P are the same as those of the other comparand in the predicate, unless the data type of that comparand is DATE, TIME, or TIMESTAMP, in which case the target is effectively CHAR(254).
Assignment Operand: For this case, P must be the value for a column in an INSERT or UPDATE. The attributes of the target are the same as those of the column, with the following exceptions:
If the column has the data type DATE, TIME, or TIMESTAMP, trailing blanks are removed from the resulting string before assignment to the target. This is the one exception to the rule that the target is treated like a column.
General Rules: Let V denote a host variable that corresponds to a parameter marker P. The value of V is assigned to the target variable for P in accordance with the rules for assigning a value to a column:
The following is an exception to the rule:
When the prepared statement is processed, the value used in place of P is the value of the target variable V. For example, if V is CHAR(6) and the target is CHAR(8), the value used in place of P is the value of V padded on the right with two blanks.
Examples
This example of portions of a COBOL program shows how an INSERT statement with parameter markers is prepared and processed.
EXEC SQL BEGIN DECLARE SECTION END-EXEC.
77 EMP PIC X(6).
01 PROJECT.
05 PRJ PIC X(6).
05 ACT PIC S9(4) COMP-4.
05 TIM PIC S9(3)V9(2).
01 HOLDER.
49 HOLDER-LENGTH PIC S9(4) COMP-4.
49 HOLDER-VALUE PIC X(80).
EXEC SQL END DECLARE SECTION END-EXEC.
.
.
.
MOVE 70 TO HOLDER-LENGTH.
MOVE "INSERT INTO EMP_ACT (EMPNO, PROJNO, ACTNO, EMPTIME)
- VALUES (?, ?, ?, ?)" TO HOLDER.
EXEC SQL PREPARE MYINSERT FROM :HOLDER END-EXEC.
IF SQLCODE = 0
PERFORM DO-INSERT THRU END-DO-INSERT
ELSE
PERFORM ERROR-CONDITION.
DO-INSERT.
MOVE "000010" TO EMP.
MOVE "AD3100" TO PRJ.
MOVE 160 TO ACT.
MOVE .50 TO TIM.
EXEC SQL EXECUTE MYINSERT USING :EMP, :PROJECT END-EXEC.
END-DO-INSERT.
.
.
.
The Extended EXECUTE statement processes an SQL statement that was prepared previously using an Extended PREPARE statement.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-EXECUTE--section_variable--IN--package_spec------------------>
>-----+-------------------------------------+------------------->
'-USING DESCRIPTOR--descriptor_name1--'
>-----+--------------------------------------------+-----------><
'-USING OUTPUT DESCRIPTOR--descriptor_name2--'
|
Description
This clause is only valid when using the EXECUTE statement against a section created by the PREPARE SINGLE ROW statement and in such cases the clause is required.
Before the Extended EXECUTE statement is processed, the user must set the fields in the SQLDA described in the "Description" section of EXECUTE and Table 20.
Notes
When the statement is processed, the host variables specified in the SQLDA are substituted, in order, into the statement in place of the parameter markers (?) that were given in the Extended PREPARE statement. Each variable must be of a data type that is compatible with its usage in the "prepared" SQL statement. Extended EXECUTE will fail if the prepared statement was a select-statement (in this case, an Extended DECLARE CURSOR coupled with an Extended OPEN, FETCH, and CLOSE should be used).
Examples
EXECUTE :STMID IN :USERID.:PACKNAME USING DESCRIPTOR INSQLDA USING OUTPUT DESCRIPTOR OUTSQLDA
The EXECUTE IMMEDIATE statement:
EXECUTE IMMEDIATE combines the basic functions of the PREPARE and EXECUTE statements. It may be used to prepare and process SQL statements that contain neither host variables nor parameter markers.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
The authorization rules are those defined for the SQL statement specified by EXECUTE IMMEDIATE. For example, see INSERT Rules for the authorization rules that apply when an INSERT statement is processed using EXECUTE IMMEDIATE. The authorization ID is the run-time authorization ID.
Syntax
>>-EXECUTE IMMEDIATE----+-string_constant-+--------------------><
'-host_variable---'
|
It is advisable to avoid using either delimited identifiers or DBCS strings in statements specified in string constants.
In Assembler, C, COBOL, REXX, the host variable must be a varying-length string variable. In C, it cannot be a NUL-terminated string. In FORTRAN, the host_variable must be a fixed-length string variable. In PL/I, the host variable can either be a fixed-length or varying-length string variable. The host variable must have a maximum length of 8192.
See PREPARE for more information on the use of DBCS constants in prepared statements in PL/I Version 2 programs.
The string_constant or host_variable must contain
one of the following SQL statements:
ACQUIRE DBSPACE
ALTER DBSPACE
ALTER PROCEDURE
ALTER PSERVER
ALTER TABLE
COMMENT ON
CREATE INDEX
CREATE PROCEDURE
CREATE PSERVER
CREATE SYNONYM
CREATE TABLE
CREATE VIEW
DELETE
DROP
DROP PROCEDURE
DROP PSERVER
EXPLAIN
GRANT Package Privileges
GRANT System Authorities
GRANT Table/View Privileges
INSERT
LABEL ON
LOCK DBSPACE
LOCK TABLE
REVOKE Package Privileges
REVOKE System Authorities
REVOKE Table/View Privileges
UPDATE
UPDATE STATISTICS
Furthermore, the statement string must not:
Notes
When an EXECUTE IMMEDIATE statement is processed, the specified statement string is parsed and checked for errors. If the SQL statement is incorrect it is not processed and the error condition that prevents its execution is reported in the SQLCA. If the SQL statement is valid, but an error occurs during its execution, that error condition is reported in the SQLCA.
If the same SQL statement is to be processed more than once, it is more efficient to use the PREPARE and EXECUTE statements rather than the EXECUTE IMMEDIATE statement.
Examples
Use PL/I program statements to move an SQL statement to the host variable QSTRING (char(80)) and prepare and process whatever SQL statement is in the host variable QSTRING.
IF ACCOUNTS = 'BIG' THEN QSTRING = 'INSERT INTO WORK_TABLE SELECT * FROM EMP_ACT WHERE ACTNO <100'; ELSE QSTRING = 'INSERT INTO WORK_TABLE SELECT * FROM EMP_ACT WHERE ACTNO >=100'; . . . EXEC SQL EXECUTE IMMEDIATE :QSTRING;
The EXPLAIN statement places information about the structure and execution performance for a DELETE, INSERT, UPDATE, or SELECT statement into one or more user-supplied tables.
The information applies to the statement for which the EXPLAIN was issued, and for any statements that have been generated internally by the database manager. Internal statements are generated to ensure referential integrity.
The result tables used by the EXPLAIN statement are updated during preprocessing of the containing program.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include both:
Syntax
>>-EXPLAIN----+-ALL-----------------+--------------------------->
| .-,--------------. |
| V | |
'----+-COST------+--+-'
+-PLAN------+
+-REFERENCE-+
'-STRUCTURE-'
>-----+-------------------------+------------------------------->
'-SET QUERYNO =--integer--'
>----FOR--explainable_sql_statement----------------------------><
|
Description
The SET QUERYNO clause is optional. If you omit it, a null value is placed in the fields of the rows inserted by the EXPLAIN statement.
The length of the SQL statement is limited to 8192 characters.
The database manager supplies customizable macros to build a set of EXPLAIN tables for each authorization ID that needs it. For IBM VM systems, the macro file is ARISEXP MACRO; for VSE systems, the macro is an A-type member, ARISEXP. Both macros contain comments describing the required customizing procedure.
EXPLAIN may be invoked either explicitly as an SQL statement or implicitly
with the EXPLAIN(YES) option for CREATE PACKAGE and application program
preprocessing. The following tables describe the columns required in
each table associated with EXPLAIN. |For more information about interpreting the data in these tables,
|see the DB2 Server for VSE & VM Performance Tuning Handbook, GC09-2987.
Table 10. Columns in COST_TABLE
| Column Name | Data Type | Description |
|---|---|---|
| QUERYNO | INTEGER |
Query number is intended to distinguish among queries. QUERYNO is set to the value specified in the SET QUERYNO clause. If the clause is omitted, QUERYNO is set to NULL. For an entry generated by the EXPLAIN(YES) option during program
preprocessing, QUERYNO corresponds to the section number in the package for
the statement being explained.
|
| RINO | SMALLINT NOT NULL |
RINO is set to zero for the user's original statement and will be
automatically incremented by one for each internally-generated statement that
is processed for referential integrity or cascade delete. RINO is
intended to distinguish among queries and internally-generated queries.
If RINO reaches 32,767, the next internally-generated statement will have a
corresponding RINO value of 1, and so on.
|
| QBLOCKNO | SMALLINT NOT NULL |
Query block number, where 1 is the outer-level query block.
Different query blocks (as occur in subqueries) receive different
numbers.
|
| PKGNAME | CHAR(8) NOT NULL | This identifies the name of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| PKGOWNER | CHAR(8) NOT NULL | This identifies the owner of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| COST | FLOAT NOT NULL |
When QBLOCKNO is 1, this is a floating point number that represents the
total estimated cost of executing the statement for which the EXPLAIN is
issued and for any statement internally generated by the database managerto
enforce referential integrity. For other values of QBLOCKNO, this is
the cost of the subquery that has this query block as its root (as opposed to
the cost of the query block alone). To find the cost of the query block
alone, use information from the STRUCTURE_TABLE. The technique for
doing this is described in the DB2 Server for VSE &
VM Database Administration manual.
|
| TIMESTAMP | TIMESTAMP NOT NULL | The time at which the EXPLAIN statement was processed. |
Table 11. Columns in PLAN_TABLE
| Column Name | Data Type | Description |
|---|---|---|
| QUERYNO | INTEGER |
Query number is intended to distinguish among queries. (See
COST_TABLE for a description of QUERYNO.)
|
| RINO | SMALLINT NOT NULL |
RINO is intended to distinguish among queries and internally-generated
queries. (See COST_TABLE for a description of RINO.)
|
| QBLOCKNO | SMALLINT NOT NULL |
Query block number, where 1 is the outer level query block (which may have
subqueries). Different query blocks receive different numbers.
The plans for executing different query blocks do not refer to each
other. However, STRUCTURE_TABLE provides the parent block for each
query block, and indicates when the query block is done. This
information is always implicitly part of the execution plan.
|
| PKGNAME | CHAR(8) NOT NULL | This identifies the name of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| PKGOWNER | CHAR(8) NOT NULL | This identifies the owner of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| PLANNO | SMALLINT NOT NULL |
A number identifying the current step of the plan. PLANNO indicates
the order in which the database managerdoes the actions of the plan for
processing the query block. The PLAN_TABLE row with PLANNO 1
indicates the first action, PLANNO 2 indicates the second action, and so
on. For each query block, each row entered as the result of an
execution of EXPLAIN PLAN has a different PLANNO value.
|
| METHOD | SMALLINT NOT NULL |
METHOD is the action done at this step; it is either 0, 1, 2 or 3. Method is 0 only for the first table accessed (which has PLANNO 1). Because this is the first table, there is not yet a composite. Also, because there is no composite, SORTCOMP (described below) is blank for this row. Methods 1 and 2 correspond to plan steps that are joins, and identify the method by which the join is performed. Method 1 is the nested loop join. That is, for each row of the composite, the database managerfinds and joins matching rows of the new table. Method 2 is the merge scan join. In a merge scan join, the database managerscans the composite and the new table in order according to the join column. It then joins rows with matching join columns. This resembles processes used in merging files, except that one row in the composite may match many rows of the new table, and many rows in the composite may match one row of the new table. Method 3 indicates that the database managermust perform additional sorts at the end of processing the query block. The following sorts are possible:
When METHOD is 3, CREATOR is all blanks, TNAME is the empty string, TABNO
is zero, and SORTNEW is N.
|
| CREATOR | CHAR(8) NOT NULL |
Creator of the new table accessed in this plan step.
|
| TNAME | VARCHAR(18) NOT NULL |
Name of the new table accessed in the plan step.
|
| TABNO | SMALLINT NOT NULL |
Because a table may be joined to itself, there may be several references to
the same table in a query block. TABNO distinguishes the different
references. TABNO, CREATOR, and TNAME correspond to the columns with
the same names in REFERENCE_TABLE. When there is no new table then
these columns have the values specified when METHOD is 3 (see above).
|
| ACCESSTYPE | CHAR(2) NOT NULL |
Indicates how the database manager will access the data. These are the character values that can appear in ACCESSTYPE:
For any type of index access, ACCESSCREATOR and ACCESSNAME identify the
index. ACCESSTYPE is blank for the top block of INSERT statements, as
well as for UPDATE and DELETE statements that use WHERE CURRENT OF CURSOR
clauses. ACCESSCREATOR is blanks and ACCESSNAME is the null value in
that case. (Access for INSERT's is performed using the first index
created; UPDATE and DELETE statements using the CURRENT OF CURSOR clause
access using their cursors.)
|
| MATCHCOLS | SMALLINT NOT NULL | For ACCESSTYPE 'I1', 'I', or 'N', the number of index keys that have key-matching predicates used in an index scan; otherwise, 0. |
| ACCESSCREATOR | CHAR(8) NOT NULL |
For ACCESSTYPE 'I1', 'I', 'N', or 'W',
ACCESSCREATOR contains the owner of the access path (index) that the database
manageruses to access the table. Otherwise, ACCESSCREATOR contains
blanks.
|
| ACCESSNAME | VARCHAR(18) NOT NULL |
For ACCESSTYPE 'I1', 'I', 'N', or 'W',
ACCESSNAME contains the name of the access path (index) that the database
manageruses to access the table. Otherwise, ACCESSNAME contains
blanks.
|
| INDEXONLY | CHAR(1) NOT NULL | Indicates whether an index is sufficient to satisfy the request, and to
what degree.
|
| SORTNEW | CHAR(1) NOT NULL |
To access a table in a particular order, the database manager may sort some fields of some rows of the new table (for example, for merge scan joins). These are the character values that can appear in SORTNEW:
SORTNEW is blank when no sort of the new table is possible, that is, when
METHOD is 3 and there is no new table.
|
| SORTCOMP | CHAR(1) NOT NULL |
To access a composite in a particular order, the database manager may sort some fields of some rows of the composite. These are the character values that can appear in SORTCOMP:
SORTCOMP is blank when no sort of the composite is possible; that is,
when METHOD is 0 and there is no composite yet.
|
| SORTN_UNIQ | CHAR(1) NOT NULL | Whether a sort is performed on the new table to remove duplicate rows. Y = Yes; N = No. |
| SORTN_JOIN | CHAR(1) NOT NULL | Whether a sort is performed on the new table if METHOD is 2. Y = Yes; N = No. |
| SORTN_ORDERBY | CHAR(1) NOT NULL | Whether an ORDER BY clause results in a sort on the new table. Y = Yes; N = No. |
| SORTN_GROUPBY | CHAR(1) NOT NULL | Whether a GROUP BY clause results in a sort on the new table. Y = Yes; N = No. |
| SORTC_UNIQ | CHAR(1) NOT NULL | Whether a sort is performed on the composite table to remove duplicate rows. Y = Yes; N = No. |
| SORTC_JOIN | CHAR(1) NOT NULL | Whether a sort is performed on the composite table if METHOD is 2. Y = Yes; N = No. |
| SORTC_ORDERBY | CHAR(1) NOT NULL | Whether an ORDER BY clause results in a sort on the composite table. Y = Yes; N = No. |
| SORTC_GROUPBY | CHAR(1) NOT NULL | Whether a GROUP BY clause results in a sort on the composite table. Y = Yes; N = No. |
| TIMESTAMP | TIMESTAMP NOT NULL | The time at which the EXPLAIN statement was processed. |
| REMARKS | VARCHAR(254) NOT NULL | A field into which you can insert any character string of 254 or fewer characters. |
Table 12. Columns in REFERENCE_TABLE
| Column Name | Data Type | Description |
|---|---|---|
| QUERYNO | INTEGER |
Query number. QUERYNO is intended for your use to distinguish among
queries. (See COST_TABLE for a description of QUERYNO.)
|
| RINO | SMALLINT NOT NULL | RINO is intended to distinguish among queries and internally generated queries. (See COST_TABLE for a description of RINO.) |
| QBLOCKNO | SMALLINT NOT NULL |
Query block number, where 1 is the top level query block, that may have
subqueries. Different query blocks receive different numbers.
|
| PKGNAME | CHAR(8) NOT NULL | This identifies the name of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| PKGOWNER | CHAR(8) NOT NULL | This identifies the owner of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| REFTYPE | CHAR(6) NOT NULL | An indication of the purpose of the current row in this table.
Rows are inserted for three reasons:
|
| CREATOR | CHAR(8) NOT NULL |
Creator of a table referenced in the query block.
|
| TNAME | VARCHAR(18) NOT NULL |
Name of the table referenced in the query block.
|
| TABNO | SMALLINT NOT NULL |
Because there may be several references to the same table in a query block
(because a table may be joined to itself), TABNO differentiates among the
different references. TABNO may correspond to the order of tables in
the FROM clause of the query.
|
| CNAME | VARCHAR(18) NOT NULL | Name of the column. |
| COLNO | SMALLINT NOT NULL |
Column number of a column in the table identified by CREATOR, TNAME, and
TABNO. EXPLAIN REFERENCE causes at most one new row to be entered in
REFERENCE_TABLE for a particular column (COLNO) of a table (TABNO) in a
query block (QBLOCKNO).
|
| FILTER | FLOAT NOT NULL |
The filter factor associated with the query block's most selective predicate on this column. The selectivity of a predicate is the fraction of the rows of the column's table that is estimated to satisfy the predicate. Not all columns referenced in a statement have filter factors, however. For each reference to a column, the EXPLAIN statement determines a filter factor if the reference to the column meets these qualifications:
For each such column reference, the EXPLAIN statement determines a
"filter factor." The smallest of these filter factors is returned
in FILTER. This value is between 0.0 and 1.0, and will be
1.0 if there are no predicates with filter factors for the
column. Filter factor may be used to estimate the cost of modifying
rows and indexes. Also, a small filter factor is one indicator that an
index on the column might be useful for processing the statement.
|
| DBSSPRED | CHAR(1) NOT NULL | Is there a sargable predicate (predicate applied at the first stage)
associated with this column?
For each reference to a column, the EXPLAIN statement determines sargability if the reference to the column meets these qualifications:
For each such column reference, the EXPLAIN statement determines the sargability of the predicate associated with the column. If a sargable predicate exists, the value is set to 'Y'; otherwise, it is set to 'N'. |
| JOINPRED | CHAR(1) NOT NULL | Is there a sargable equi-join predicate (using equal value in tables to
join) associated with this column? Y = Yes; N = No.
If yes, then DBSSPRED must be Y as well. |
| ORDERCOL | SMALLINT NOT NULL | If this column is referenced in an ORDER BY clause, give its relative position in the ORDER BY clause and sort direction. If the column is not referenced in the ORDER BY clause, ORDERCOL is zero. Sort direction is indicated by a positive number for ascending order and a negative number for descending order. |
| GROUPCOL | SMALLINT NOT NULL | If this column is referenced in a GROUP BY clause, give its relative position in the GROUP BY clause. If the column is not referenced in the GROUP BY clause, GROUPCOL is zero. |
| UPDATECOL | CHAR(1) NOT NULL | If this column is in the SET clause of an UPDATE statement, indicate how
it is updated.
|
| TIMESTAMP | TIMESTAMP NOT NULL | The time at which the EXPLAIN statement was processed. |
Table 13. Columns in STRUCTURE_TABLE
| Column Name | Data Type | Description |
|---|---|---|
| QUERYNO | INTEGER |
Query number. QUERYNO is intended to distinguish among
queries. (See COST_TABLE for a description of QUERYNO.)
|
| RINO | SMALLINT NOT NULL | RINO is intended to distinguish among queries and internally generated queries. (See COST_TABLE for a description of RINO.) |
| QBLOCKNO | SMALLINT NOT NULL |
Query block number, where 1 is the top level query block that may have
subqueries. Different query blocks will receive different
numbers.
|
| PKGNAME | CHAR(8) NOT NULL | This identifies the name of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| PKGOWNER | CHAR(8) NOT NULL | This identifies the owner of the package in which this SQL statement originated. This field is blank for explicit EXPLAIN processing invoked by the EXPLAIN statement. |
| ROWCOUNT | INTEGER NOT NULL |
Estimated number of rows returned for the query or subquery corresponding
to this query block. For queries, this is the estimated size of the
response. For update and delete statements, this is the estimated
number of affected rows. ROWCOUNT can be used in estimating update
costs. For insert statements, the ROWCOUNT for the top level query
block (QBLOCKNO 1) is always 0, but the ROWCOUNT's for other query
blocks, if any, are normal estimates. ROWCOUNT is also 0 for UPDATE and
DELETE statements that use WHERE CURRENT OF CURSOR clauses.
|
| TIMES | FLOAT NOT NULL |
Estimated number of times that "dependent" query blocks of this block
will be processed for each execution of this query block. This field is
no longer in use, but is retained to provide for compatibility with older
versions of the SQL/DS product.
|
| PARENT | SMALLINT NOT NULL |
The query block for which this block is performed. This may be the
query block in whose WHERE clause the current query block appears.
However, some query blocks can be processed earlier, at the opening of a
"parent" query block, because there are no correlations to intermediate
query blocks tables. In this case, PARENT identifies that ancestor,
rather than the parent given by the statement's structure.
|
| ATOPEN | CHAR (1) NOT NULL |
These are the characters that can appear in ATOPEN:
|
| TIMESTAMP | TIMESTAMP NOT NULL | The time at which the EXPLAIN statement was processed. |
Examples
Place information about a SELECT statement that selects all the rows from the EMP_ACT table into your tables named REFERENCES_TABLE and COST_TABLE. Tag the entries that contain this information with the reference number 1500.
EXPLAIN REFERENCE, COST
SET QUERYNO = 1500
FOR SELECT * FROM EMP_ACT
The FETCH statement positions a cursor on the next row of its result table and assigns the values of that row to host variables, host structures, or both.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
See DECLARE CURSOR for an explanation of the authorization required to use a cursor.
>>-FETCH--cursor_name----+-INTO----host_variable_list---------+-><
'-USING DESCRIPTOR--descriptor_name--'
|
Description
If the cursor is currently positioned on or after the last row of the result table:
If the cursor is currently positioned before a row, the cursor is positioned on that row, and the values of that row are assigned to host variables and host structure subfields as specified by INTO or USING.
If the cursor is currently positioned on a row other than the last row, after execution of the FETCH statement the cursor is positioned on the next row. Values of that row are assigned to host variables and host structure subfields as specified by INTO or USING.
The first value in the result row is assigned to the first host variable or host structure subfield in the list, the second value to the second variable or subfield, and so on.
Before the FETCH statement is processed, the user must set some fields in the SQLDA as described in the "Description" section of EXECUTE and Table 20.
The data type of a variable must be compatible with its corresponding value. If the value is numeric, the variable must have the capacity to represent the whole part of the value. For a datetime value, the variable must be a character string variable of a minimum length as defined in String Representations of Datetime Values. If the value is null, an indicator variable must be specified.
Each value with a corresponding variable is assigned to the variable in accordance with the assignment rules described in Chapter 3, "Language Elements". If the number of variables is less than the number of values in the row, the SQLWARN3 field of the SQLCA is set to 'W'. If an assignment error occurs, the value is not assigned to the variable, and no more values are assigned to variables. Any values that have already been assigned to variables remain assigned.
See the DB2 Server for VSE & VM Application Programming manual for a description of the possible errors when FETCH is processed.
Notes
An open cursor has three possible positions:
If a cursor is on a row, that row is called the current row of the cursor. A cursor referenced in an UPDATE or DELETE statement must be positioned on a row. A cursor can only be on a row as a result of a FETCH statement.
It is possible for an error to occur that makes the state of the cursor unpredictable.
Examples
There are two tables, FORUM and ARCHIVE, each with the following
columns:
| Name: | FORUM | RECEIVED | SOURCE | TOPIC | ENTRY_TEXT |
|---|---|---|---|---|---|
| Type: |
char(8) not null |
timestamp not null |
char(8) not null |
char(64) not null |
varchar(4000) not null |
| Desc: | Forum name | Date and time entry received | Userid of person appending entry | Topic within the forum | The text appended in this entry |
The FORUM table contains a number of named forums. Each forum contains one or more topics and each topic contains one or more entries. When a topic is no longer current its entries are either deleted or moved to the ARCHIVE table.
The following PL/I program performs maintenance on the forum table. A user can invoke the program with one of three commands. Each command is accompanied by a string of text that can be found within the TOPIC column of the entries for a given topic (this need not be the entire TOPIC value). The three commands are:
CLEANUP: PROC OPTIONS(MAIN);
DCL NOT_END BIT(1);
DCL ACTION BINARY FIXED(15); /* 1=chg-topic 2=archive 3=delete */
EXEC SQL BEGIN DECLARE SECTION;
DCL SRCH_FORUM CHAR(8);
DCL SRCH_TOPIC CHAR(66) VARYING;
DCL NEW_TOPIC CHAR(64) VARYING;
DCL FORUM CHAR(8);
DCL 1 ENTRY,
5 TSTMP CHAR(26),
5 PERSON CHAR(8),
5 TOPIC CHAR(64) VARYING;
DCL TXT CHAR(4000) VARYING;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
EXEC SQL WHENEVER NOT FOUND CONTINUE;
EXEC SQL WHENEVER SQLWARNING CONTINUE;
EXEC SQL WHENEVER SQLERROR GOTO ERRCHK;
EXEC SQL CONNECT TO TOROLAB3;
GET LIST (ACTION, SRCH_FORUM, SRCH_TOPIC, NEW_TOPIC);
SRCH_TOPIC = '%' || SRCH_TOPIC || '%';
EXEC SQL DECLARE CUR CURSOR FOR
SELECT * FROM FORUM
WHERE FORUM = :SRCH_FORUM AND TOPIC LIKE :SRCH_TOPIC
FOR UPDATE OF TOPIC;
EXEC SQL OPEN CUR;
EXEC SQL FETCH CUR INTO :FORUM, :ENTRY, :TXT;
IF SQLSTATE = '02000'
THEN DO;
DISPLAY ('No notes found for requested forum and topic');
GO TO FINISHED;
END;
NOT_END = '1'B;
DO WHILE (NOT_END);
EXEC SQL FETCH CUR INTO :FORUM, :ENTRY, :TXT;
IF SQLSTATE = '02000' THEN
NOT_END = '0'B;
ELSE DO;
SELECT;
WHEN (ACTION = 1) /* change topic value */
EXEC SQL UPDATE FORUM
SET TOPIC = :NEW_TOPIC
WHERE CURRENT OF CUR;
WHEN (ACTION = 2) /* archive entry to another table */
DO;
EXEC SQL INSERT INTO ARCHIVE
VALUES (:FORUM, :TSTMP, :PERSON, :TOPIC, :TXT);
EXEC SQL DELETE FROM FORUM WHERE CURRENT OF CUR;
END;
WHEN (ACTION = 3) /* delete topic */
EXEC SQL DELETE FROM FORUM WHERE CURRENT OF CUR;
END; /* select */
END; /* else do */
END; /* do while */
FINISHED:
EXEC SQL CLOSE CUR;
EXEC SQL COMMIT WORK;
RETURN;
ERRCHK:
DISPLAY ('Unexpected Error -changes will be backed out');
PUT SKIP LIST (SQLCA);
EXEC SQL WHENEVER SQLERROR CONTINUE; /* continue if error on rollback */
EXEC SQL ROLLBACK WORK;
RETURN;
END; /* CLEANUP */
The Extended FETCH statement positions a cursor on the next row of its result table and assigns the values of that row to host variables. The cursor must have been opened using the Extended OPEN statement.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-FETCH--cursor_variable--USING DESCRIPTOR--descriptor_name--->< |
Description
Before the Extended FETCH statement is processed, the user must set some fields in the SQLDA as described in the "Description" section of EXECUTE and Table 20.
The indicated cursor must be declared and opened.
Notes
In most respects, the Extended FETCH statement is identical to the FETCH statement (see FETCH). However, in the Extended FETCH statement, the cursor_name is a host variable, thereby making it possible for a user to provide the cursor name when the program is run and to FETCH in a logical unit of work or program other than the one in which the statement was prepared. Extended DECLARE CURSOR, OPEN, and FETCH must occur in the same logical unit of work.
Examples
FETCH :CURSOR1 USING DESCRIPTOR MYSQLDA
This form of the GRANT statement grants the privilege to process statements in a package.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
To process this statement, the privileges held by the authorization ID of the statement must include the EXECUTE privilege on the package and GRANT authority on that privilege. Someone with DBA authority may grant the EXECUTE privilege on a package owned by another user.
Description
If WITH GRANT OPTION is omitted, the named authorization_names cannot grant the EXECUTE privilege to others unless they have received that authority from some other source.
The GRANT authority cannot be passed to PUBLIC. If you use PUBLIC and WITH GRANT OPTION together, the statement is processed; but a warning is given and the EXECUTE privilege is granted to PUBLIC without GRANT authority.
Notes
Only the authorization ID that preprocesses a package (or an authorization ID with DBA authority) can drop that package from the database. A 'drop' privilege cannot be granted to another authorization ID.
Examples
Grant the ability to process the TIMESHEET package (which is used by the TIMESHEET program) to everyone.
GRANT EXECUTE ON TIMESHEET TO PUBLIC
Grant the ability to process the TABB package (which is used by the TABB program) to KING, BROWN, and BLACK. Allow them to grant this privilege to others.
GRANT EXECUTE ON TABB
TO KING, BROWN, BLACK
WITH GRANT OPTION
This form of the GRANT statement changes passwords and authorities.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
DBA authority is needed to grant authorities and to change others' passwords. DBA authority is not needed for someone to change their own password if they have been granted connect authority explicitly by a DBA. (A user able to access the database only because connect authority has been granted to ALLUSERS cannot use this command to change their own password.)
>>-GRANT-------------------------------------------------------->
>-----+--+-CONNECT--+--TO----| AUTH |--+--------+----------+---><
| +-DBA------+ '-| ID |-' |
| '-RESOURCE-' |
| .-,-----------------------. |
| V | |
+-CONNECT TO----+-authorization_name-+--+------------+
| | (1) | |
| '-ALLUSERS-----------' |
'-SCHEDULE TO--subsystemid--IDENTIFIED BY--password--'
AUTH
.-,---------------------.
V |
|------authorization_name---+-----------------------------------|
ID
.-,-----------.
V |
|---IDENTIFIED BY-----password---+------------------------------|
Notes:
|
Description
| VSE Users |
|---|
|
ALLUSERS is not a valid option since implicit CONNECT authority is not applicable to VSE application servers. |
Examples
Grant DBA authority to THOMPSON and THORN.
GRANT DBA TO THOMPSON, THORN
Grant CONNECT authority to BRIAN (with the password CONCON), ED (with the password NDPNDP), and JOHN (with the password LIBLIB).
GRANT CONNECT TO BRIAN, ED, JOHN
IDENTIFIED BY CONCON, NDPNDP, LIBLIB
This form of the GRANT statement grants privileges on table and views.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include the privilege being granted and GRANT authority on that privilege. Someone with DBA authority may grant table privileges on a table or view owned by another user.
>>-GRANT-------------------------------------------------------->
>-----+-ALL--+------------+------------------------------+------>
| '-PRIVILEGES-' |
| .-,-------------------------------------------. |
| V (1) | |
'----+-ALTER----------------------------------+--+-'
+-DELETE---------------------------------+
| (1) |
+-INDEX----------------------------------+
+-INSERT---------------------------------+
| (1) |
+-REFERENCES-----------------------------+
+-SELECT---------------------------------+
'-UPDATE--+----------------------------+-'
| .-,--------------. |
| V | |
'-(-----column_name---+---)--'
.-,-----------------------.
V |
>----ON--+-table_name-+---TO----+-authorization_name-+--+------->
'-view_name--' '-PUBLIC-------------'
>----+-------------------+-------------------------------------><
'-WITH GRANT OPTION-'
Notes:
|
Description
This privilege is required to reference the parent table when a referential constraint is defined or added by the CREATE TABLE or ALTER TABLE statement respectively.
This privilege is also required on the parent table when the user wants to use the ALTER TABLE statement to drop, activate, or deactivate a foreign key on a dependent table that references the parent table.
You cannot pass the GRANT authority to PUBLIC. If you use PUBLIC and WITH GRANT OPTION together, the statement is processed; but a warning is given and the privileges are granted to PUBLIC without GRANT authority.
Examples
Given that you have DBA authority, and that you have all grant authorities on the table WESTERN_COURSES (owned by KATHLEEN), grant all privileges on the table to PUBLIC.
GRANT ALL ON KATHLEEN.WESTERN_COURSES
TO PUBLIC
Grant the appropriate privileges on your CALENDAR table so that ROANNA and EMMA can read it and insert new entries into it, but do not allow them to change or remove any entries. Do not allow ROANNA or EMMA to grant those privileges to others.
GRANT SELECT, INSERT ON CALENDAR
TO ROANNA, EMMA
Grant the UPDATE privilege on the RATING and CRITIQUE columns from the public table TORONTO_RESTAURANT (owned by ONTARIO) to MARGARET and COMPDEPT. Allow them to grant those privileges to others.
GRANT UPDATE (RATING, CRITIQUE) ON ONTARIO.TORONTO_RESTAURANT TO MARGARET, COMPDEPT WITH GRANT OPTION
The INCLUDE statement inserts declarations, statements, or both, into a source program.
Invocation
This statement can only be embedded in an application program. It is not an executable statement. It is not supported in REXX.
Authorization
None required.
Syntax
>>-INCLUDE----+-SQLCA----------+-------------------------------><
+-SQLDA----------+
'-text_file_name-'
|
Description
The statements contained in the external source specified by text_file_name may be host language statements or SQL statements (except for another INCLUDE statement). INCLUDE text_file_name statements may not be nested, but the external source may contain INCLUDE SQLDA or INCLUDE SQLCA statements. The INCLUDE text_file_name may appear in an SQL DECLARE section or the entire SQL DECLARE section(s) may be placed within an external source file.
Notes
The INCLUDE statement may be used to obtain secondary input from a CMS file in VM or a source member in VSE. If a source program input to a preprocessor uses the INCLUDE facility, any files to be used as secondary input must be accessed by the user. The INCLUDE statement causes input to be read from the specified file name until the end of the file, at which time the SYSIN input in VM or the SYSIPT input in VSE resumes.
The file to be included must have one of the following file types:
The source member must be cataloged as one of the following source types:
For COBOL programs, INCLUDE SQLCA must not be specified in other than the Working Storage Section.
See the DB2 Server for VSE & VM Application Programming manual for more information on using external source files.
Examples
Include an SQL Communications Area into a PL/I program.
EXEC SQL INCLUDE SQLCA;
The INSERT statement inserts rows into a table or view. Inserting a row into a view also inserts the row into the table on which the view is based.
There are two forms of this statement:
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
The INSERT privilege on a view is only inherent in DBA authority. Ownership of a view does not necessarily include the INSERT privilege on the view because the privilege may not have been granted when the view was created, or it may have been granted, but subsequently revoked.
If a subselect is specified, the privileges held by the authorization ID of the statement must also include at least one of the following:
>>-INSERT INTO----+-table_name-+-------------------------------->
'-view_name--'
>-----+----------------------------+---------------------------->
| .-,--------------. |
| V | |
'-(-----column_name---+---)--'
.-,-----------------------.
V |
>-----+-VALUES--(----+-constant-----------+--+---)--+----------><
| +-host_variable_list-+ |
| +-NULL---------------+ |
| '-special_register---' |
'-subselect--+---------------+----------------'
'-WITH--+-RR-+--'
'-CS-'
|
Description
A value cannot be inserted into a view column that is derived from:
If the object of the insert operation is a view with such columns, a list of column names must be specified, and the list must not identify these columns.
Omission of the column list is an implicit specification of a list in which every column of the table or view is identified in left-to-right order. This list is established when the statement is prepared and therefore does not include columns that were added to a table after the statement was prepared.
SQL statements can be implicitly or explicitly rebound (prepared again). The effect of a rebind on INSERT statements that do not include a column list is to re-establish the list. Therefore, the number of columns into which data will be inserted may change.
Each host variable and host structure named must be described in the program in accordance with the rules for declaring host variables and host structures.
The number of values in the VALUES clause must equal the number of names in the column list. The first value is inserted in the first column in the list, the second value in the second column, and so on.
For an explanation of constant and host-variable-list, see Chapter 3, "Language Elements". For a description of special-register, see Special Registers. NULL specifies the null value. A constant or special register cannot be used to specify the insert value for a long string column.
(For an explanation of subselect, see Chapter 5, Queries.)
The base object of the INSERT, and the base object of the subselect, or any subquery of the subselect, must not be the same table.
The number of columns in the result table must equal the number of names in the column list. The value of the first column of the result is inserted in the first column in the list, the second value in the second column, and so on.
A non-null value cannot be inserted into a long string column using a subselect.
The default isolation level of the statement is the isolation level of the package.
Insert values must satisfy the following rules. If they do not, or if any other errors occur during the execution of the INSERT statement, no rows are inserted.
If you name a view whose definition includes WITH CHECK OPTION, each row inserted into the view must conform to the definition of the view. If the view you name is dependent on other views whose definitions include WITH CHECK OPTION, the inserted rows must also conform to the definitions of those views.
If you name a view whose definition does not include WITH CHECK OPTION, rows can be inserted that do not conform to the definition of the view. Those rows cannot appear in the view but are inserted into the base table of the view.
For an explanation of the rules governing these situations, see CREATE VIEW.
If you are inserting rows into a parent table that is part of a referential constraint, the database manager implicitly checks that the primary key remains unique and does not contain null values.
Notes
Rows are inserted in an order determined by the database manager; that is, no facility is provided to specify the position in the table of a newly inserted row.
If an error occurs during the execution of an INSERT, you must inspect SQLWARN6 to determine the extent of the error. The following are current settings for SQLWARN6 when there is an error indication and the possible responses:
The order of rows being inserted is determined by the database manager; no facility is provided to specify the position in the table of a newly inserted row. The SQLERRD(3) portion of the SQLCA indicates the number of rows that were inserted.
Unless appropriate locks already exist, one or more exclusive locks are acquired at the execution of a successful INSERT statement. Until the locks are released, an inserted row can only be accessed by the application process that performed the insert. For further information about locking, see the description of the COMMIT, ROLLBACK, LOCK TABLE, and LOCK DBSPACE statements.
Examples
Insert a new department with the following specifications into the DEPARTMENT table:
INSERT INTO DEPARTMENT
VALUES ('E31', 'ARCHITECTURE', '00390', 'E01')
Insert a new department into the DEPARTMENT table as in example 1, but do not assign a manager to the new department.
INSERT INTO DEPARTMENT (DEPTNO, DEPTNAME, ADMRDEPT)
VALUES ('E31', 'ARCHITECTURE', 'E01')
Create a temporary table MA_EMP_ACT with the same columns as the EMP_ACT table. Load MA_EMP_ACT with the rows from the EMP_ACT table with a project number (PROJNO) starting with the letters 'MA'.
CREATE TABLE MA_EMP_ACT
(EMPNO CHAR(6) NOT NULL,
PROJNO CHAR(6) NOT NULL,
ACTNO SMALLINT NOT NULL,
EMPTIME DEC(5,2),
EMSTDATE DATE,
EMENDATE DATE )
INSERT INTO MA_EMP_ACT
SELECT * FROM EMP_ACT
WHERE SUBSTR(PROJNO, 1, 2) = 'MA'
Use a PL/I program statement to add a skeleton project to the PROJECT table. Obtain the project number (PROJNO), project name (PROJNAME), department number (DEPTNO), and responsible employee (RESPEMP) from host variables and a host structure. Use the current date as the project start date (PRSTDATE). Assign a NULL value to the remaining columns in the table.
.
.
DCL 1 PROJECT,
5 PRJNO CHAR(5),
5 PRJNM CHAR(24) VARYING;
DCL 1 EMPLOYEE,
5 DPTNO CHAR(3),
5 REMP CHAR(6),
5 LNAME CHAR(25);
.
.
.
EXEC SQL INSERT INTO PROJECT ( PROJNO, PROJNAME, DEPTNO, RESPEMP, PRSTDATE)
VALUES (:PROJECT, :EMPLOYEE.DPTNO, :REMP, CURRENT DATE);
The LABEL ON statement adds or replaces labels in the catalog descriptions of tables, views, or columns.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
>>-LABEL ON----------------------------------------------------->
>-----+--| options_a |------------------------IS--string_constant----+>
| .-,-----------------------------------. |
| V | |
'--+-table_name-+---(-----column_name--IS--string_constant---+---)-'
'-view_name--'
>--------------------------------------------------------------><
options_a
|--+-TABLE--+-table_name-+--------------+-----------------------|
| '-view_name--' |
'-COLUMN--+-table_name.column_name-+-'
'-view_name.column_name--'
|
Description
The label is placed in the CLABEL column of the SYSTEM.SYSCOLUMNS catalog table, for the row that describes the column.
The column_name must identify a column of the specified table or view that exists at the application server.
Notes
Unlike synonyms, labels cannot be used as identifiers. Instead, they can be used in displays created by applications that process SQL statements dynamically.
A DESCRIBE statement specified with USING BOTH or USING LABELS can be used to return column labels in an SQLDA. The program can then move the label from the SQLNAME field of the SQLDA into a work area. A column is considered to have no label if either its LABEL column in SYSTEM.SYSCOLUMNS is NULL, or if it has a zero length value. If there is no column label when the program issues a DESCRIBE, the SQLNAME field of the SQLDA is set to length 0, and the field is cleared to 30 blanks. For this reason, the program should move the label into a work area using the length returned in SQLDA only after it makes sure that the length is not zero.
Examples
Insert a label for the EMP_ACT table into the catalog.
LABEL ON TABLE EMP_ACT
IS 'EMPLOYEE ACTIVITY BY PROJECT'
Insert a label for the EMP_VIEW1 view into the catalog.
LABEL ON TABLE EMP_VIEW1
IS 'EMPLOYEE WITHOUT SALARY'
Insert a label for the EDLEVEL column of the EMPLOYEE table into the catalog.
LABEL ON COLUMN EMPLOYEE.EDLEVEL
IS 'HIGHEST GRADE LEVEL'
Insert a label for two different columns of the EMPLOYEE table into the catalog.
LABEL ON EMPLOYEE
(WORKDEPT IS 'DEPTNO IN EMPLOYEE',
EDLEVEL IS 'HIGHEST GRADE LEVEL ')
The LOCK DBSPACE statement either prevents concurrent application processes from changing a dbspace or prevents concurrent application processes from using a dbspace.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
>>-LOCK DBSPACE--dbspace_name--IN----+-SHARE-----+--MODE-------><
'-EXCLUSIVE-'
|
Description
The LOCK statement can be used to lock both private and public dbspaces. If the dbspace_name is unqualified, the database manager will first look for a private dbspace and, if that does not exist, it will look for a public dbspace with the same dbspace name.
Locking prevents concurrent operations. A lock is not necessarily acquired during the execution of LOCK DBSPACE if a suitable lock already exists. The lock that prevents the concurrent operations is held until the termination of the unit of work.
Examples
Obtain a lock on the dbspace named DSP3. Allow others to read from the DSP3 while it is locked.
LOCK DBSPACE DSP3 IN SHARE MODE
The LOCK TABLE statement either prevents concurrent application processes from changing a table or prevents concurrent application processes from using a table.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
Syntax
>>-LOCK TABLE--table_name--IN----+-SHARE-----+--MODE-----------><
'-EXCLUSIVE-'
|
Description
Locking prevents concurrent operations. A lock is not necessarily acquired during the execution of LOCK TABLE if a suitable lock already exists. The lock that prevents the concurrent operations is held until the termination of the unit of work.
The lock is acquired when the LOCK TABLE statement is processed.
Examples
Obtain a lock on the DEPARTMENT table. Do not allow others to either update or read from DEPARTMENT while it is locked.
LOCK TABLE DEPARTMENT IN EXCLUSIVE MODE
The OPEN statement opens a cursor.
Invocation
This statement can be embedded only in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
See DECLARE CURSOR for the authorization required to use a cursor. The authorization for the OPEN statement is checked when the related DECLARE CURSOR statement is prepared.
>>-OPEN--cursor_name----+------------------------------------+-><
+-USING----host_variable_list--------+
'-USING DESCRIPTOR--descriptor_name--'
|
Description
If using an insert-cursor and the program is blocking, this statement tells the application server to prepare to block the rows to be inserted. If not blocking, the application server prepares to insert a single row into the database. Rows are not actually inserted into the database until one or more PUT statements have been processed.
If opening a query-cursor, the result table of the cursor is derived by evaluating that select-statement. The evaluation uses the current values of any special registers specified in the select-statement and the current values of any host variables or host structures specified in it or in the USING clause of the OPEN statement. The rows of the result table may be derived during the execution of the OPEN statement, and a temporary table created to hold them; or they may be derived during the execution of subsequent FETCH statements. In either case, the cursor is placed in the open state and positioned before the first row of its result table. If the table is empty, the position of the cursor is effectively "after the last row."
A USING clause cannot appear in the OPEN statement for an insert-cursor.
The total number of host variables and host structure subfields must be the same as the number of parameter markers in the prepared statement. The nth variable or subfield corresponds to the nth parameter marker in the prepared statement.
Before the OPEN statement is processed, the user must set some fields in the SQLDA as described in the "Description" section of EXECUTE and Table 20.
If the select-statement of the cursor was prepared (rather than declared) and that statement contains parameter markers, when that statement is evaluated each parameter marker in the statement is effectively replaced by its corresponding host variable. With the exception of the LIKE predicate, the replacement of a parameter marker is an assignment operation in which the source is the value of the host variable, and the target is a variable within the database manager. The attributes of the target variable are determined as follows:
If the parameter marker is the pattern in a LIKE predicate, then:
Let V denote a host variable that corresponds to parameter marker P. The value of V is assigned to the target variable for P in accordance with the rules for assigning a value to a column. Thus:
When the SELECT statement of the cursor is evaluated, the value used in place of P is the value of the target variable for P. For example, if V is CHAR(6), and the target is CHAR(8), the value used in place of P is the value of V padded with two blanks.
The USING clause is intended for a prepared SELECT statement that contains parameter markers. However, it can also be used when the SELECT statement of the cursor is part of the DECLARE CURSOR statement. In this case the OPEN statement is processed as if each host variable in the SELECT statement were a parameter marker, except that the attributes of the target variables are the same as the attributes of the host variables in the SELECT statement. The effect is to override the values of the host variables in the SELECT statement of the cursor with the values of the host variables specified in the USING clause.
Notes
All cursors in a program are in the closed state when:
A cursor can also be in the closed state because:
To retrieve rows from the active set of a query-cursor, a FETCH statement must be processed while the cursor is open. To insert rows into the active set of an insert-cursor, a PUT statement must be processed while the cursor is open. The only way to change the state of a cursor from closed state to open is to process an OPEN statement.
If the result table of a query cursor is not read-only, its rows are derived during the execution of subsequent FETCH statements. The same method may be used for a read-only result table. However, if a result table is read-only, the database manager may choose to use the temporary table method instead. With this method the entire result table is inserted into a temporary table during the execution of the OPEN statement. When a temporary table is used, the results of a program can differ in these two ways:
Conversely, if a temporary table is not used, INSERT, UPDATE, and DELETE statements processed while the cursor is open can affect the result table if issued from the same application process. The effect of such operations is not always predictable. For example, if cursor C is positioned on a row of its result table defined as SELECT * FROM T, and you insert a row into T, the effect of that insert on the result table is not predictable because its rows are not ordered. A subsequent FETCH C might or might not retrieve the new row of T.
Examples
Write the embedded statements in a COBOL program that will:
EXEC SQL DECLARE C1 CURSOR FOR
SELECT DEPTNO, DEPTNAME, MGRNO FROM DEPARTMENT
WHERE ADMRDEPT = 'A00' END-EXEC.
EXEC SQL OPEN C1 END-EXEC.
Code an OPEN statement to associate a cursor DYN_CURSOR with a dynamically defined select-statement in a PL/I program. Assume each prepared select-statement always has two parameter markers in its WHERE clause with the first having a data type of integer and the second having a data type of varchar(64). (The related host variable definitions, PREPARE statement and DECLARE CURSOR statement are also shown in the example below.)
EXEC SQL BEGIN DECLARE SECTION;
DCL HV_INT BINARY FIXED(31);
DCL HV_VCHAR64 CHAR(64) VARYING;
DCL STMT1_STR CHAR(200) VARYING;
EXEC SQL END DECLARE SECTION;
EXEC SQL PREPARE STMT1_NAME FROM :STMT1_STR;
EXEC SQL DECLARE DYN_CURSOR CURSOR FOR STMT1_NAME;
EXEC SQL OPEN DYN_CURSOR USING :HV_INT, :HV_VCHAR64;
Code an OPEN statement as in example 2, but in this case the number and data types of the parameter markers in the WHERE clause are not known.
EXEC SQL BEGIN DECLARE SECTION;
DCL STMT1_STR CHAR(200) VARYING;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLDA;
EXEC SQL PREPARE STMT1_NAME FROM :STMT1_STR;
EXEC SQL DECLARE DYN_CURSOR CURSOR FOR STMT1_NAME;
EXEC SQL OPEN DYN_CURSOR USING DESCRIPTOR :SQLDA;
This example shows the SQL statements used with a cursor CURSOR3 in a PL/I program. In this program, CURSOR3 inserts a row into the MA_ACT view (and therefore into the EMP_ACT table, which is the base table for the view) based on the values in the host variables EMNUM (char(6)), PJNUM (char(6)), ACNUM (smallint), EMTIM (dec(5,2)), STDAT (date), and EMDAT (date).
EXEC SQL DECLARE CURSOR3 CURSOR FOR
INSERT INTO MA_ACT
VALUES (:EMNUM, :PJNUM, :ACNUM, :EMTIM, :STDAT, :EMDAT);
EXEC SQL OPEN CURSOR3;
EXEC SQL PUT CURSOR3;
EXEC SQL CLOSE CURSOR3;
The Extended OPEN statement opens a cursor declared using an Extended DECLARE CURSOR statement for a previously prepared statement. The open cursor retrieves the results of a query, or inserts values into the database.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-OPEN--cursor_variable---------------------------------------->
>-----+------------------------------------+-------------------><
'-USING DESCRIPTOR--descriptor_name--'
|
Description
Before the Extended OPEN statement is processed, the user must set the fields in the SQLDA described in the "Description" section of EXECUTE and Table 20.
When the cursor is to be used for inserting data into a table, the USING DESCRIPTOR clause should not be included because the clause must be in the PUT statement.
Notes
In most respects, the Extended OPEN statement is similar to the OPEN statement (see OPEN). However, in the Extended OPEN statement, the cursor_name is a host variable, thereby making it possible for a user to provide the cursor name when the program is run and to open the cursor in a logical unit of work or program other than the one in which the statement was prepared. Extended DECLARE CURSOR and Extended OPEN must occur in the same logical unit of work.
Examples
OPEN :CURSOR1 USING DESCRIPTOR MYSQLDA
The PREPARE statement is used by application programs to dynamically prepare an SQL statement for execution. The PREPARE statement creates an executable SQL statement, called a prepared statement, from a character string form of the statement, called a statement string. The prepared statement is a named object that can be referred to only within the logical unit of work in which it is created.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
The authorization rules are those defined for the SQL statement specified by the PREPARE statement. For example, see Chapter 5, Queries for the authorization rules that apply when a select-statement is prepared. The authorization ID is the run-time authorization ID.
>>-PREPARE--statement_name--FROM----+-string_constant-+--------><
'-host_variable---'
|
Description
You should avoid using either delimited identifiers or DBCS strings in statements specified in string constants because results are unpredictable.
When the string_constant form of the PREPARE statement is used in FORTRAN programs:
In Assembler, C, COBOL, and REXX,
the host variable must be a varying-length string variable. In C, it cannot be a NUL-terminated string. In FORTRAN, the host variable must be a fixed-length string variable. In PL/I, the host variable can either be a fixed-length or varying-length string variable. The host variable must have a maximum length of 8192.
In a PL/I Version 2 program, a prepared statement containing DBCS characters must be coded as a mixed string using the new PL/I Mixed format.
For example:
DYNSTR = 'SELECT COL1 FROM TABLE WHERE COL2 = G'<....>'M; EXEC SQL PREPARE STMT1 FROM :DYNSTR;
The string_constant or host_variable must
contain one of the following SQL statements:
|
ACQUIRE DBSPACE ALLOCATE CURSOR ALTER DBSPACE ALTER TABLE ASSOCIATE LOCATORS COMMENT ON CREATE INDEX CREATE SYNONYM CREATE TABLE CREATE VIEW DELETE DROP EXPLAIN |
GRANT Package Privileges GRANT System Authorities GRANT Table Privileges INSERT LABEL ON LOCK DBSPACE LOCK TABLE REVOKE Package Privileges REVOKE System Authorities REVOKE Table Privileges select-statement UPDATE UPDATE STATISTICS |
Furthermore, the statement string must not:
Although a statement string cannot include references to host variables, it may include parameter markers; those can be replaced by the values of host variables when the prepared statement is processed.
A parameter marker is a question mark (?) that is used where a host variable could be used if the statement string were a static SQL statement. For an explanation of how parameter markers are replaced by values, see OPEN and EXECUTE.
Notes
When a PREPARE statement is processed, the statement string is parsed and checked for errors. If the statement string is incorrect, a prepared statement is not created and the error condition that prevents its creation is reported in the SQLCA.
Prepared statements can be referred to in the following kinds of statements, with the following restrictions shown:
A prepared statement can be processed many times. Indeed, if a prepared statement is not processed more than once and does not contain parameter markers, it is more efficient to use the EXECUTE IMMEDIATE statement rather than the PREPARE and EXECUTE statements.
All prepared statements created in a logical unit of work are destroyed when the logical unit of work is terminated.
Examples
Prepare and process a non-select-statement in a COBOL program. Assume the statement is contained in a host variable HOLDER and that the program will place a statement string into the host variable based on some instructions from the user. The statement to be prepared does not have any parameter markers.
EXEC SQL PREPARE STMT_NAME FROM :HOLDER END-EXEC. EXEC SQL EXECUTE STMT_NAME END-EXEC.
Prepare and process a non-select-statement as in example 1, except code it for a PL/I program. Also assume the statement to be prepared can contain any number of parameter markers.
EXEC SQL PREPARE STMT_NAME FROM :HOLDER; EXEC SQL EXECUTE STMT_NAME USING DESCRIPTOR :INSERT_DA;
Assume that the following statement is to be prepared:
INSERT INTO DEPARTMENT VALUES(?, ?, ?, ?)
To insert department number G01 named COMPLAINTS, which has no manager
and reports to department A00, the structure INSERT_DA should have the
following values before running the EXECUTE statement.
 View figure.
View figure.
The Basic Extended PREPARE and Single Row Extended PREPARE forms of the Extended PREPARE statement permit a statement to be prepared and stored in a package for later execution.
The Empty Extended PREPARE form of the Extended PREPARE statement provides support for dynamic SQL statements in non-modifiable packages. It is used in conjunction with the Temporary Extended PREPARE form of the Extended PREPARE statement.
The Temporary Extended PREPARE form of the Extended PREPARE statement provides support for dynamic SQL statements in non-modifiable packages.
The package you are preparing into must have been created with the CREATE PACKAGE statement.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the first three forms of the Extended PREPARE statement must have at least one of the following:
The authorization ID of the Temporary Extended PREPARE form must have at least one of the following:
Syntax
>>-PREPARE FROM--host_variable--------------------------------->< >>-SETTING--section_variable--IN--package_spec------------------>
>-----+------------------------------------+-------------------><
'-USING DESCRIPTOR--descriptor_name--'
Single Row Extended PREPARE >>-PREPARE SINGLE ROW FROM--host_variable---------------------->< >>-SETTING--section_variable--IN--package_spec------------------>
>-----+------------------------------------+-------------------><
'-USING DESCRIPTOR--descriptor_name--'
Empty Extended PREPARE >>-PREPARE FROM NULL SETTING--section_variable--IN--package_spec--> >-------------------------------------------------------------->< Temporary Extended PREPARE >>-PREPARE FROM--host_variable--FOR--section_variable---------->< >>-IN--package_spec-------------------------------------------->< |
Description
In the Single Row Extended PREPARE statement, the section_variable is set by the database manager to an identifier for the statement that is prepared. It is used in subsequent Extended DESCRIBE, DROP STATEMENT, and Extended EXECUTE (with the OUTPUT Descriptor clause) statements to specify the corresponding prepared statement.
In the Empty Extended PREPARE statement, the section_variable is set by the database manager to an identifier for the indefinite section that is created. It is used in subsequent Temporary Extended PREPARE, Extended DESCRIBE, Extended EXECUTE, DROP STATEMENT and Extended DECLARE CURSOR statements to specify the corresponding section.
USING DESCRIPTOR may be specified for Temporary Extended PREPARE without an error indication, but it is ignored.
Normally if a prepared statement contains parameter markers (?), an SQLDA would be provided at run time by the Extended EXECUTE or Extended OPEN statement that references that prepared statement. However, an SQLDA can be used to improve run-time performance and reduce conversions in those cases where data types and lengths are known at statement preparation time for the parameter markers in the prepared SQL statement. Another reason for providing an SQLDA at statement preparation time is to override the restrictions on the use of parameter markers as outlined under "Rules for parameter markers" under the PREPARE statement. Also, if an SQLDA is not provided at statement preparation time, it is assumed that none of the variables used within predicates are nullable; therefore, an error results if a negative indicator value is provided at execution time.
An input SQLDA may also be specified on a subsequent Extended EXECUTE or Extended OPEN; in such cases, if the information does not match that of the PREPARE SQLDA, errors may result.
The fields described in the SQLDA should match the parameter markers (?) in the statement being prepared. If there are fewer fields specified in the SQLDA, an error will result. If there are more fields specified in the SQLDA, they will be ignored.
Before the Extended PREPARE statement is processed, the user must set the fields in the SQLDA described in the "Description" section of EXECUTE and Table 20.
The Basic Extended PREPARE form of the Extended PREPARE statement adds an SQL statement to an existing package. If the package is new, the Extended PREPARE statement must be preceded by a CREATE PACKAGE statement. Existing packages, created using the MODIFY option of CREATE PACKAGE, can be extended using this format of the PREPARE statement.
The USING DESCRIPTOR clause must be used when preparing a statement that contains parameter markers, if using the DRDA protocol.
The Single Row Extended PREPARE form of the Extended PREPARE statement indicates that the select-statement contained in the host_variable is a single row Select. Select-statements prepared using "PREPARE SINGLE ROW" must be processed using the Extended EXECUTE with OUTPUT DESCRIPTOR command.
The Single Row Extended PREPARE form of the Extended PREPARE statement is not supported with the DRDA protocol.
The Empty Extended PREPARE form of the Extended PREPARE statement allows for the creation of an indefinite section in a program. The section is subsequently used when a statement is dynamically prepared using a Temporary Extended PREPARE statement.
This format of the Extended PREPARE must follow the CREATE PACKAGE...USING NOMODIFY... format of the CREATE PACKAGE statement and must exist in the same logical unit of work as the CREATE PACKAGE statement.
If the above restriction is violated, execution of the statement will be unsuccessful.
The Temporary Extended PREPARE form of the Extended PREPARE statement prepares the statement contained in the created indefinite section. This section must have been created by an Empty Extended PREPARE statement. The section number for this section is contained in the section_variable.
This format of the Extended PREPARE may not be processed in a logical unit of work in which update to the package is already in progress. If the above restriction is violated, execution of the statement will be unsuccessful.
See "Rules for statement strings", "Parameter Markers", and "Rules for parameter markers" on page *** for a list of the SQL statements which may be contained in the host_variable and the rules for using parameter markers in the host_variable.
Notes
The various formats to the Extended PREPARE statement permit statements to be created for different programs in different logical units of work.
Because a DBA can add a statement to a package on behalf of the owner (creator) of the module, where the owner is not authorized for the added function, the DBA should grant the proper authorization to the owner.
Examples
Example of Basic Extended PREPARE
PREPARE FROM :XSTRING SETTING :STMID
IN :USERID.:PACKNAME USING DESCRIPTOR MYSQLDA
Example of Single Row Extended PREPARE
PREPARE SINGLE ROW FROM :XSTRING SETTING :STMID
IN :USERID.:PACKNAME USING DESCRIPTOR MYSQLDA
Example of Empty Extended PREPARE
PREPARE FROM NULL SETTING :STMID
IN :USERID.:PACKNAME
Example of Temporary Extended PREPARE
PREPARE FROM :XSTRING FOR :STMID
IN :USERID.:PACKNAME
The PUT statement inserts a row into a table. It is most often used when blocking is in effect in order to create a block of rows to be inserted into a table at one time and thus improve performance.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
Authorization
For an explanation of the authorization required to use a cursor, see DECLARE CURSOR.
>>-PUT--cursor_name----+------------------------------------+--><
+-FROM----host_variable_list---------+
'-USING DESCRIPTOR--descriptor_name--'
|
Description
Introduces a list of host variables, host structure, or both, whose values are substituted for the parameter markers (question marks) in the dynamically-prepared INSERT statement. (For an explanation of parameter markers, see PREPARE.)
The total number of host variables and host structure subfields must be the same as the number of parameter markers in the prepared statement. The nth variable or subfield corresponds to the nth parameter marker in the prepared statement.
Identifies an input SQLDA structure that provides information concerning input variables that were specified as parameter markers (?) when the INSERT statement was prepared.
Before the PUT statement is processed, the user must set the fields in the SQLDA described in the "Description" section of EXECUTE and Table 20.
Notes
When blocking is used, every time a PUT statement is processed, a single row of data is added to an insert-block. Rows are not inserted into the database until the block is full, or, until a CLOSE statement is processed. The PUT statement can also be processed when blocking is not in effect. In this case, one data row is inserted directly into a table.
Insert blocking is not available with the DRDA protocol.
The database manager does not notify your program of an insert error until the PUT that fills a block is processed. To determine when (or if) rows are actually inserted into the database, your program should examine SQLERRD(3) in the SQLCA when doing PUTs.
For example, suppose that 10 data rows to be inserted fit into one block, and that the data for the fourth insert is in error. PUTs 1 through 9 have successful SQLCA notifications, even though the insert for the fourth PUT has an error. On the tenth PUT, the block is full. The database manager tries to process the block of ten inserts, but encounters the error in the fourth row. It stops processing the block - that is, three rows are inserted successfully. SQLERRD(3) contains the number of rows that were successfully inserted. In this case, it contains a value of 3. If all rows were inserted successfully, it would contain 10. You can use SQLERRD(3) to determine where the error occurred.
Examples
This example of statements from a PL/I program illustrates the use of a PUT statement with a static INSERT statement. The host variables EMPNO, FIRSTNME, MIDINIT, LASTNAME and EDLEVEL are compatible with the columns by the same name in the EMPLOYEE table. In this program, cursor PUTCUR inserts blocks of skeleton rows into the EMPLOYEE table.
EXEC SQL DECLARE PUTCUR CURSOR FOR
INSERT INTO EMPLOYEE (EMPNO, FIRSTNME, MIDINIT, LASTNAME, EDLEVEL)
VALUES (:EMPNO, :FIRSTNME, :MIDINIT, :LASTNAME, :EDLEVEL);
EXEC SQL OPEN PUTCUR;
... /* code to start a loop */
... /* code to pick up values and assign them to host variables */
EXEC SQL PUT PUTCUR;
... /* code to end a loop */
EXEC SQL CLOSE PUTCUR;
Similar to example 1, except that it uses a PUT statement with a dynamic INSERT statement.
EXEC SQL PREPARE INSERT_STMT FROM
'INSERT INTO EMPLOYEE (EMPNO, FIRSTNME, MIDINIT, LASTNAME, EDLEVEL)
VALUES (? ? ? ? ?)';
EXEC SQL DECLARE PUTCUR CURSOR FORINSERT_STMT;
EXEC SQL OPEN PUTCUR;
... /* code to start a loop */
... /* code to pick up values and assign them to host variables */
/* and to the three subfields FIRSTNME, MIDINIT, LASTNAME */
/* of host structure EMPNAME. */
EXEC SQL PUT PUTCUR FROM :EMPNO, :EMPNAME, :EDLEVEL;
... /* code to end a loop */
EXEC SQL CLOSE PUTCUR;
The Extended PUT statement inserts a row into a table. It is most often used when blocking is in effect in order to create a block of rows to be inserted into a table at one time and thus improve performance. The cursor must have been opened with an Extended OPEN.
Invocation
This statement can only be embedded in an application program written in Assembler or REXX.
Authorization
The authorization ID of the statement must have one of the following:
>>-PUT--cursor_variable----------------------------------------->
>-----+------------------------------------+-------------------><
| .-,----------------. |
| V | |
+-FROM-----host_variable---+---------+
'-USING DESCRIPTOR--descriptor_name--'
|
Description
Before the Extended PUT statement is processed, the user must set the fields in the SQLDA described in the "Description" section of EXECUTE and Table 20.
The indicated cursor must be declared and opened.
Notes
In most respects, the Extended PUT statement is identical to the PUT statement (see PUT); however, in the Extended PUT statement, the cursor_variable is a host variable. This feature makes it possible for a user to provide the cursor name when the program is run and to enter a PUT statement in a logical unit of work or program other than the one in which the statement was prepared. Extended DECLARE CURSOR, OPEN, and PUT must occur in the same logical unit of work.
Examples
PUT :CURSOR1 FROM :X, :Y PUT :CURSOR2 USING DESCRIPTOR SQLDA
This form of the REVOKE statement revokes the privilege to process statements in a package.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
This authorization ID must previously have granted the specified privileges to every authorization_name (or PUBLIC) specified in the FROM clause.
Note that someone with DBA authority can indirectly revoke the EXECUTE privilege on a package by obtaining the owner's password from the SYSTEM.SYSUSERAUTH catalog table and then connecting as the owner.
Description
You cannot use the authorization_name of the REVOKE statement itself. (You cannot revoke privileges from yourself.)
Example
All users currently have the right to process the TREMAR package. PAYROLL, HANNA, and TREVOR have explicitly been granted this privilege. The other users have it because a GRANT EXECUTE TO PUBLIC statement was previously processed.
Remove the right to process the package from all users but PAYROLL.
REVOKE EXECUTE ON TREMAR FROM HANNA, PUBLIC, TREVOR
This form of the REVOKE statement allows a user having DBA authority to revoke authorities from other users.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
The authorization ID of the statement must have DBA authority.
>>-REVOKE------------------------------------------------------->
.-,-----------------------.
V |
>-----+-CONNECT FROM----+-authorization_name-+--+-------+------><
| | (1) | |
| '-ALLUSERS-----------' |
| .-,---------------------. |
| V | |
+--+-DBA------+---FROM-----authorization_name---+-+
| '-RESOURCE-' |
'-SCHEDULE FROM--subsystemid----------------------'
Notes:
|
Revoking CONNECT does not cause objects owned by that authorization_name to be dropped. Neither does it cause table privileges for that authorization_name to be revoked. A user with DBA authority can later drop the objects and revoke the privileges.
| VSE Users |
|---|
|
ALLUSERS is not a valid option because implicit CONNECT authority is not applicable to VSE application servers. |
Note
If you enter REVOKE for an authority that the user does not have, the revocation is ignored for that authority.
Examples
Given that VEILLEUX, MARINA, and HEARST have DBA authority, enter the statements necessary to revoke all authority from VEILLEUX. Leave MARINA with only CONNECT authority and leave HEARST with both CONNECT and RESOURCE authority.
REVOKE DBA FROM VEILLEUX, MARINA, HEARST REVOKE CONNECT FROM VEILLEUX GRANT RESOURCE TO HEARST
All users have previously been granted implicit connect authority from their VM user ID. PAYROLL, HANNA, and TREVOR have explicitly been granted this authority. The other users have it because a GRANT CONNECT TO ALLUSERS statement was previously processed.
Remove implicit connect authority from all users but PAYROLL.
REVOKE CONNECT FROM HANNA, TREVOR, ALLUSERS
| VSE Users |
|---|
|
Example 2 does not apply to VSE. |
This form of the REVOKE statement revokes privileges on the table or view.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that can be dynamically prepared.
Authorization
This authorization ID must previously have granted the specified privileges to every authorization_name (or PUBLIC) specified in the FROM clause.
Note that someone with DBA authority can indirectly revoke privileges on a table or view by obtaining the owner's password from the SYSTEM.SYSUSERAUTH catalog table and then connecting as the owner.
Description
You cannot use the authorization_name of the REVOKE statement itself. (You cannot revoke privileges from yourself.)
When a privilege is revoked from a user, every privilege dependent on that privilege is also revoked.
A privilege P2 possessed by user U2 is dependent on privilege P1 possessed by user U1 if all of these are true:
Also, table privilege P2 is dependent on table privilege P1 if P2 was derived from P1 as a result of a CREATE VIEW statement.
Revoking a privilege that was used to create a package invalidates the package.
If you granted the same privilege to the same user more than once, revoking that privilege from that user negates all those grants. It does not negate any grant of that privilege made by others.
If a user has more than one source for a privilege, that privilege is not revoked until it is revoked by all sources (see example 2 below).
The only way to revoke the WITH GRANT OPTION is to revoke the privilege itself and then to grant it again without the WITH GRANT OPTION.
Examples
This example shows the effect of revoking a privilege that has a dependent privilege. To illustrate this process, the diagram that follows shows a sequence of GRANT and REVOKE statements.
*------------------------*
| Database Administrator |
*--------*-------*-------*
1GW 3R
V V
*---------*
| PAULINE |
*----*----*
2G
V
*---------*
| DAVE |
*---------*
The statements illustrated in the above diagram are:
1GW) from DBA: GRANT SELECT ON TBLA TO PAULINE WITH GRANT OPTION 2G) from PAULINE: GRANT SELECT ON TBLA TO DAVE 3R) from DBA: REVOKE SELECT ON TBLA FROM PAULINE
Following this sequence of statements neither PAULINE nor DAVE has the SELECT privilege on TBLA. The explicit revoking of PAULINE's privilege implicitly revokes DAVE's as well.
This extends example 1 in order to show the effect of having received a privilege from more than one source.
*--------------------------------*
| Database Administrator |
*-*-------*----------------*-----*
1GW 7R 2GW
V V V
*------------* *------------*
| PAULINE | | SIMON |
*----------*-* *-*----------*
3GW 5GW
V V
*------------*
| DAVE |
**----------**
4G 6G
V V
*------------* *------------*
| JAY | | RICHARD |
*------------* *------------*
Following this sequence of statements from the users indicated:
1GW) from DBA: GRANT SELECT ON TBLA TO PAULINE WITH GRANT OPTION 2GW) from DBA: GRANT SELECT ON TBLA TO SIMON WITH GRANT OPTION 3GW) from PAULINE GRANT SELECT ON TBLA TO DAVE WITH GRANT OPTION 4G) from DAVE: GRANT SELECT ON TBLA TO JAY 5GW from SIMON: GRANT SELECT ON TBLA TO DAVE WITH GRANT OPTION 6G) from DAVE: GRANT SELECT ON TBLA TO RICHARD 7R) from Admin: REVOKE SELECT ON TBLA FROM PAULINE
PAULINE loses her SELECT privilege on TBLA, but DAVE retains his (having obtained it from SIMON as well).
JAY loses his SELECT privilege because he obtained it from DAVE at a time when DAVE had only obtained the SELECT WITH GRANT privilege from PAULINE.
RICHARD retains his SELECT privilege because he obtained it from DAVE at a time when DAVE had obtained the SELECT WITH GRANT privilege from both PAULINE and SIMON.
This example shows how the revocation of a PUBLIC privilege varies depending on whether: that privilege was granted specifically to that user or that privilege was obtained using a GRANT TO PUBLIC.
*--------------------------------*
| Database Administrator |
*-*------------*---------------*-*
1GW 2GP 4RP
V | |
*---------* | |
| MARY | | |
*-------*-* | |
3G *---------* |
V V V V
*---------* *--------------------------*
| RICHARD | | LOUIS (and other public) |
*---------* *--------------------------*
Following this sequence of statements from the users indicated:
1GW) from DBA: GRANT SELECT ON TBLA TO MARY WITH GRANT OPTION 2GP) from DBA: GRANT SELECT ON TBLA TO PUBLIC 3G) from MARY: GRANT SELECT ON TBLA TO RICHARD 4RP) from DBA: REVOKE SELECT ON TBLA FROM PUBLIC
RICHARD retains the SELECT privilege on TBLA even though he was originally granted it as a member of the public. LOUIS only had the SELECT privilege as a member of the public, so loses that privilege.
The ROLLBACK statement ends a logical unit of work and back out the database changes that were made by that logical unit of work.
Invocation
This statement can be embedded in an application program or issued interactively. It is an executable statement that cannot be dynamically prepared.
Authorization
None required.
.-WORK-.
>>-ROLLBACK--+------+--+---------+-----------------------------><
'-RELEASE-'
|
Description
for a subsequent logical unit of work. If this default user ID had been overridden with an explicit CONNECT, in the terminating logical unit of work that explicitly established user ID is replaced by the default user ID. By not specifying RELEASE, the user ID and database at termination of the logical unit of work are retained for a subsequent logical unit of work. For VSE interactive users connected to a remote DRDA application server, when the next SQL statement is entered, you are automatically connected with your CICS signon user ID to the same application server.
ROLLBACK terminates the logical unit of work in which ROLLBACK is processed. All changes made by the following statements during a logical unit of work, are backed out:
ACQUIRE DBSPACE
ALTER DBSPACE
ALTER PROCEDURE
ALTER PSERVER
ALTER TABLE
COMMENT ON
CREATE INDEX
CREATE PROCEDURE
CREATE PSERVER
CREATE SYNONYM
CREATE TABLE
CREATE VIEW
DELETE
DROP
DROP PROCEDURE
DROP PSERVER
EXPLAIN
GRANT Package Privileges
GRANT System Authorities
GRANT Table/View Privileges
INSERT
LABEL ON
PUT
REVOKE Package Privileges
REVOKE System Authorities
REVOKE Table/View Privileges
UPDATE
UPDATE STATISTICS
All locks acquired by the logical unit of work are released.
All cursors that were opened during the logical unit of work are closed. All statements that were prepared during the logical unit of work are destroyed. Any cursors associated with a prepared statement that is destroyed cannot be opened until the statement is prepared again.
Notes
If a COMMIT or ROLLBACK does not immediately precede the termination of an application process, the database manager attempts to commit the work (it may, however, not always be successful). It is strongly recommended that each application process explicitly ends its logical unit of work before terminating.
ROLLBACK should not be issued after a severe error has occurred (one which sets the SQLWARN0 field in the SQLCA to 'S'). In this situation, the only statement that can be issued is a CONNECT statement to another application server.
|The logical unit of work must be completed by using the COMMIT or |ROLLBACK statements before the CONNECT statement can be used to switch to |another user ID or application server.
|TCP/IP does not perform any security checking during a physical |connect. The Batch application requester will use the DRDA security |handshaking flows during the logical connect to perform user ID and password |verification. The physical TCP/IP connection will be deallocated and |reallocated whenever the application switches to a different user ID or server |name (using the CONNECT statement), and DRDA security handshaking flows will |be used again during the logical connect. Either of these switches will |not require the application to issue a COMMIT RELEASE or ROLLBACK |RELEASE. The Batch Resource Adapter will retain and use the current |user ID, password, and server name (unless different ones are specified with a |new CONNECT statement) after the new TCP/IP physical connection is |established. If a COMMIT RELEASE or ROLLBACK RELEASE was issued prior |to a CONNECT statement, then all user ID, password and server name information |is lost and must be supplied with the next CONNECT.
Examples
The PL/I program in COMMIT illustrates how the ROLLBACK statement is used.
The SELECT INTO statement produces a result table consisting of at most one row, and assigns the values in that row to host variables. If the table is empty, the statement assigns +100 to SQLCODE and '02000' to SQLSTATE and does not assign values to the host variables. If more than one row satisfies the search condition, statement processing is terminated and an error occurs.
Invocation
This statement can only be embedded in an application program. It is an executable statement that cannot be dynamically prepared.
In FORTRAN, REXX, and programs prepared using extended dynamic SQL, SELECT INTO cannot be used with the DRDA protocol.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
>>-select_clause--INTO------host_variable_list------------------>
>----from_clause--+--------------+----+-------------+----------><
'-where_clause-' '-with_clause-'
|
Description
The result table is derived by evaluating the from_clause, where_clause, and select_clause, in this order.
See Chapter 5, Queries for a description of the select_clause, from_clause, and where_clause.
The first value in the result row is assigned to the first host_variable or host structure subfield in the list, the second value to the second variable, and so on. If the number of host variables and host structure subfields is less than the number of select_list values, the value W is assigned to the SQLWARN3 field of the SQLCA. (See SQL Communication Area (SQLCA).) Note that there is no warning if there are more variables than the number of select_list values. For a datetime value, the variable must be a character string variable of a minimum length as defined in Chapter 3, "Language Elements".
If the value is null, an indicator variable must be specified.
Each assignment to a variable is made according to the rules described in Chapter 3, "Language Elements".
>>-WITH----+-RR-+----------------------------------------------><
+-CS-+
'-UR-'
|
If an error occurs, no value is assigned to the host variable or to variables later in the list, though any values that have already been assigned to variables remain assigned.
If an error occurs because the result table has more than one row, values may or may not be assigned to the host variables. If values are assigned to the host variables, the row that is the source of the values is undefined and not predictable.
See the DB2 Server for VSE & VM Application Programming manual for a description of the possible errors when SELECT INTO is processed.
Examples
Using a COBOL program statement, put the maximum salary (SALARY) from the EMPLOYEE table into the host variable MAX-SALARY (dec(9,2)).
EXEC SQL SELECT MAX(SALARY)
INTO :MAX-SALARY
FROM EMPLOYEE
END-EXEC.
Using a PL/I program statement, select the row from the EMPLOYEE table with a employee number (EMPNO) value the same as that stored in the host variable HOST_EMP char(6)). Then put the first name (FIRSTNME) and last name (LASTNAME) into the host structure HOST_NAME, and education level (EDLEVEL) into the host variable HOST_EDUCATE (integer) from that row.
EXEC SQL SELECT FIRSTNME, LASTNAME, EDLEVEL
INTO :HOST_NAME, :HOST_EDUCATE
FROM EMPLOYEE
WHERE EMPNO = :HOST_EMP;
The UPDATE statement updates the values of specified columns in rows of a table or view. Updating a row of a view updates a row of its base table.
There are two forms of this statement:
Invocation
A Searched UPDATE statement can be embedded in an application program or issued interactively. A Positioned UPDATE must be embedded in an application program. Both Searched UPDATE and Positioned UPDATE are executable statements that can be dynamically prepared.
A Positioned UPDATE in FORTRAN, and programs prepared using extended dynamic SQL cannot be used with the DRDA protocol.
Authorization
The privileges held by the authorization ID of the statement must include at least one of the following:
The UPDATE privilege on a view is only inherent in DBA authority. Ownership of a view does not necessarily include the UPDATE privilege on the view because the privilege may not have been granted when the view was created, or it may have been granted, but subsequently revoked.
If the search_condition includes a subquery, the privileges designated by the authorization ID of the statement must also include at least one of the following:
Searched UPDATE: >>-UPDATE----+-table_name-+--+------------------+--------------->
'-view_name--' '-correlation_name-'
.-,----------------------------------.
V |
>-----SET-----column_name-- = --+-expression-+--+--------------->
'-NULL-------'
>-----+--------------------------+---+---------------+---------><
'-WHERE--search_condition--' '-WITH--+-RR-+--'
'-CS-'
Positioned UPDATE: >>-UPDATE----+-table_name-+------------------------------------->
'-view_name--'
.-,----------------------------------.
V |
>-----SET-----column_name-- = --+-expression-+--+--------------->
'-NULL-------'
>----WHERE CURRENT OF--cursor_name-----------------------------><
|
Description
| Note: | Someone with DBA authority may update rows from a few of the catalog tables. See Updateable Columns. |
For a Positioned UPDATE, allowable column names can be further restricted to those in a certain list. This list appears in the UPDATE clause of the select statement for the associated cursor. The column names need not be in the select-list of the select statement for the associated cursor If the select statement is dynamically prepared, the UPDATE clause must always be present. Otherwise, the clause can be omitted under the conditions described in The NOFOR Option.
A view column derived from the same column as another column of the view can be updated, but both columns cannot be updated in the same UPDATE statement.
A column_name in an expression must name a column of the named table or view. For each row that is updated, the value of the column in the expression is the value of the column in the row before the row is updated.
If the column_name on the left hand side of the SET identifies a long string column, the only type of expression allowed is a host-variable.
The search_condition is applied to each row of the table or view and the updated rows are those for which the result of the search_condition is true.
If the search condition contains a subquery, the subquery can be thought of as being processed each time the search condition is applied to a row, and the results used in applying the search condition. In actuality, the subquery is processed for each row only if it contains a correlated reference to a column of the table or view.
The default isolation level of the statement is the isolation level of the package. WITH can only be specified on a SEARCHED update; it is incompatible with the WHERE CURRENT OF clause.
The table or view specified must also be identified in the FROM clause of the select-statement of the cursor, and the result table of the cursor must not be read-only. (For an explanation of read-only result tables, see DECLARE CURSOR.)
When the UPDATE statement is processed, the cursor must be positioned on a row and that row is updated.
Update values must satisfy the following rules. If they do not, or if any other errors occur during the execution of the UPDATE statement, no rows are updated.
Update values are assigned to columns under the assignment rules described in Chapter 3, "Language Elements".
If the identified table, or the base table of the identified view, has one or more unique indexes, each row updated in the table must conform to the constraints imposed by those unique indexes.
In the case of a multiple-row update of a unique key, the uniqueness constraint is effectively checked at the end of the operation.
If a view is used that is defined using the WITH CHECK OPTION, each updated row must conform to the definition of the view. If a view is used that is not defined using WITH CHECK OPTION, rows can be changed so that they no longer conform to the definition of the view. Such rows are updated in the base table of the view and no longer appear in the view.
If a view is used that is dependent on other views whose definitions include WITH CHECK OPTION, the updated rows must also conform to the definition of those views.
The value of the primary key in a parent row must not be changed by a Positioned UPDATE. A primary key value may be changed using a Searched UPDATE if there are no rows that are dependent on the old key value and if the new value of the primary key is unique. A non-null update value of a foreign key must be equal to a value of the primary key of the parent table of the relationship.
When an UPDATE statement completes execution, the value of SQLERRD(3) in the SQLCA is the number of rows updated. (For a description of the SQLCA, see SQL Communication Area (SQLCA).)
Uniqueness is checked after all rows are updated.
When multiple-row updates are performed against a column that has a unique index, the database manager is sensitive to the order (ascending or descending) of the data. Since the database manager automatically creates a unique index on a primary key column, a Searched UPDATE cannot be used to perform multiple-row updates against the primary key column. This is to ensure that updates to the primary key are independent of the order of the data. For the same reason, a Positioned UPDATE cannot be used to update primary key columns.
Unless appropriate locks already exist, one or more exclusive locks are acquired by the execution of a successful UPDATE statement. Until the locks are released, the updated row can only be accessed by the application process that performed the update. For further information on locking, see the descriptions of the COMMIT, ROLLBACK, LOCK TABLE, and LOCK DBSPACE statements.
The blocking options, SBLocK or BLocK, in the SQLPREP command and the CREATE PACKAGE statement improves performance as they insert and retrieve rows in groups. However, if a program was preprocessed with the NOFOR option, query cursors referenced in Positioned UPDATE statements are unavailable for blocking. If a Positioned UPDATE is coded in a program and NOFOR is not in effect, then a FOR UPDATE OF clause must be included in the select-statement. See the DB2 Server for VSE & VM Application Programming manual for more information on blocking when preprocessing and running a program.
It is possible for an error to occur that makes the state of the cursor unpredictable. If an error occurs during the execution of a Positioned UPDATE that makes the position of a cursor unpredictable, the cursor is closed.
If an error occurs during the execution of a Searched UPDATE, you must inspect SQLWARN6 to determine the extent of the error. The following are the current settings of SQLWARN6 along with possible responses:
Examples
Change the job (JOB) of employee number (EMPNO) '000290' in the EMPLOYEE table to 'LABORER'.
UPDATE EMPLOYEE
SET JOB = 'LABORER'
WHERE EMPNO = '000290'
Increase the project staffing (PRSTAFF) by 1.5 for all projects that department (DEPTNO) 'D21' is responsible for in the PROJECT table.
UPDATE PROJECT
SET PRSTAFF = PRSTAFF + 1.5
WHERE DEPTNO = 'D21'
All the employees except the manager of department (WORKDEPT) 'E21' have been temporarily laid off. Indicate this by changing their job (JOB) to NULL and their pay (SALARY, BONUS, COMM) values to zero in the EMPLOYEE table.
UPDATE EMPLOYEE
SET JOB=NULL, SALARY=0, BONUS=0, COMM=0
WHERE DEPTNO = 'E21'
AND JOB <> 'MANAGER'
In a PL/I program display the rows from the EMPLOYEE table and then, if requested to do so, change the job (JOB) of certain employees to the new job keyed in.
EXEC SQL DECLARE C1 CURSOR FOR
SELECT *
FROM EMPLOYEE
FOR UPDATE OF JOB;
EXEC SQL OPEN C1;
EXEC SQL FETCH C1 INTO ... ;
PUT ... ;
GET LIST (CHANGE, NEWJOB);
IF CHANGE = 'YES' THEN
EXEC SQL UPDATE EMPLOYEE
SET JOB = :NEWJOB
WHERE CURRENT OF C1;
EXEC SQL CLOSE C1;
The UPDATE STATISTICS statement causes internal statistics of tables and indexes to be updated with current information.
Invocation
This statement can be embedded in an application program, or it can be issued interactively.
Authorization
The privileges held by the authorization ID of the statement must include CONNECT authority.
>>-UPDATE--+-----+--STATISTICS FOR------------------------------>
'-ALL-'
>-----+-TABLE--table_name------+-------------------------------><
'-DBSPACE--dbspace_name--'
|
Description
Invoking UPDATE STATISTICS can improve performance on statements that access data from tables. These statistics, contained in the catalog tables, include the table size, various index characteristics, and other information.
Examples
This shows the statements that are embedded in a PL/I program in order to add an index on project name (PROJNAME) to the PROJECT table and to update the statistics on that table. This is so that programs using that table that are subsequently reprepared can consider those statistics when determining an access strategy.
EXEC SQL CREATE INDEX PROJNAME
ON PROJECT(PROJNAME);
EXEC SQL UPDATE STATISTICS FOR TABLE PROJECT;
The WHENEVER statement specifies the next host language statement to which execution will be transferred when a specified exception condition occurs.
Invocation
This statement can only be embedded in an application program. It is not an executable statement. It is not supported in REXX.
Authorization
None required.
>>-WHENEVER----------------------------------------------------->
>-----+--+-SQLERROR---+---+-CONTINUE------------------------+-+-><
| '-SQLWARNING-' | (1) | |
| +-STOP----------------------------+ |
| '--+-GOTO--+---+---+--host_label--' |
| '-GO TO-' '-:-' |
'-NOT FOUND--+-CONTINUE------------------------+--------'
'--+-GOTO--+---+---+--host_label--'
'-GO TO-' '-:-'
Notes:
|
Description
The SQLERROR, SQLWARNING or NOT FOUND, clause identifies the type of exception condition.
The CONTINUE, GO TO, or STOP clause specifies the next statement to be processed when the identified type of exception condition exists.
Notes
There are three types of WHENEVER statements:
Every executable SQL statement in a program is within the scope of one implicit or explicit WHENEVER statement of each type. The scope of a WHENEVER statement is related to the listing sequence of the statements in the program, not their execution sequence.
An SQL statement is within the scope of the last WHENEVER statement of each type that is specified before that SQL statement in the source program. If a WHENEVER statement of some type is not specified before an SQL statement, that SQL statement is within the scope of an implicit WHENEVER statement of that type in which CONTINUE is specified.
Examples
Write the statements that need to be embedded in a COBOL program in order to:
EXEC SQL WHENEVER SQLERROR GOTO HANDLER END-EXEC. EXEC SQL WHENEVER NOT FOUND GOTO ENDDATA END-EXEC.