DB2 Server for VSE & VM: SQL Reference
SQL is a standardized language for defining and manipulating data in a
relational database. In accordance with the relational model of data,
the database is perceived as a set of tables, relationships are represented by
values in tables, and data is retrieved by specifying a result table that can
be derived from one or more base tables.
SQL statements are processed by a database manager. One of the
functions of the database manager is to transform the specification of a
result table into a sequence of internal operations that optimize data
retrieval. This transformation occurs when the SQL statement is
prepared.
Statement preparation is also known as binding.
All executable SQL statements must be prepared before they can be
processed. The result of preparation is the executable or operational
form of the statement. The method of preparing an SQL statement and the
persistence of its operational form distinguish static SQL from dynamic
SQL.
The source form of a static SQL statement is embedded within an
application program written in a host language such as COBOL. The
statement is prepared before the program is run and the operational form of
the statement persists beyond the execution of the program.
A source program containing static SQL statements must be processed by an
SQL preprocessor before it is compiled. The preprocessor checks the
syntax of the SQL statements, turns them into host language comments, and
generates host language statements to invoke the database manager.
The preparation of an SQL application program includes parsing and
validation, the binding of its SQL statements, and the compilation of the
modified source program.
A dynamic SQL statement is prepared during the execution of an
SQL application and the operational form of the statement does not persist
beyond the unit of work. The source form of the statement is a
character string that is passed to the database manager by the program using
the static SQL statement PREPARE or EXECUTE IMMEDIATE.
SQL statements embedded in a REXX application are
dynamic SQL statements.
1
SQL statements
submitted to an interactive SQL facility are also dynamic SQL
statements.
An interactive SQL facility is associated with the database manager.
Essentially, every interactive SQL facility is an SQL application program that
reads statements from a terminal, prepares and processes them dynamically, and
displays the results to the user. Such SQL statements are said to be
issued interactively. The DB2 Server
for VSE & VM Interactive SQL Guide and Reference manual discusses interactive SQL in greater detail. An associated
product, Query Management Facility (QMF), also uses DB2 Server for VSE &
VM interactively.
Extended dynamic statements support direct creation and maintenance
of packages for DB2 Server for VSE & VM data and provide a function
similar to that provided by the DB2 Server for VSE & VM
preprocessors. These functions are particularly useful where:
- The current preprocessors do not support the language of the application
or support program that is needed.
- SQL statements are conceived and built dynamically, but are processed
repetitively (in a different logical unit of work). In this case it is
a performance benefit to avoid having to repeat the preprocessing of
statements each time they are processed, as would be required for normal
dynamic statements.
- It is desirable to build and maintain an application package of SQL
statements to be shared by a group of users.
Individual SQL statements can be added or deleted without affecting or
repeating the preprocessing of other SQL statements in the group (a group can
be stored in one package).
By using the extended dynamic statements, development programmers can write
their own preprocessors or database interface routines
that support preplanned access to the database manager. Preplanned
access means that access paths to data are optimized once when the statement
is prepared. They need not be prepared again for each execution.
Extended dynamic SQL statements may be used only in Assembler and REXX
programs.
A relational database is a database that can be perceived as a
set of tables and manipulated in accordance with the relational model of
data.
Tables are logical structures maintained by the database manager.
Tables are made up of columns and rows. A column is the
vertical component of a table.
It has a name and a defined data type (for example, character, decimal, or
integer). A row is the horizontal component of a
table. At the intersection of every column and row is a specific data
item called a value.
A row contains a sequence of values such that the nth value is a
value of the nth column of the table. There is no inherent
order of the rows within a table but there is a defined order of columns for a
table.
A base table
is created with the CREATE TABLE statement and holds persistent user
data. A result table or
an active set is a set of rows that the database manager selects
or generates from one or more base tables.
A key is one or more columns identified as such in the
description of a table, an index, or a referential constraint. The same
column can be part of more than one key. A key composed of more than
one column is called a composite key.
A composite key is an ordered set of columns of the same
table. The ordering of the columns is not constrained by their ordering
within the table. The term value when used with respect to a
composite key denotes a composite value. Thus, a rule such as "the
value of the foreign key must be equal to the value of the primary key"
means that each component of the value of the foreign key must be equal to the
corresponding component of the value of the primary key.
A unique key is a key that is constrained so that no two of its
values are equal. The constraint is enforced by the database manager
during the execution of INSERT and UPDATE statements. The mechanism
used to enforce the constraint is called a unique index. Thus, every
unique key is a key of a unique index.
A primary key is a unique key that is part of the definition of
a table. A table can have at most one primary key, and the columns of a
primary key cannot contain null values. Primary keys are optional and
can be defined in CREATE TABLE statements or ALTER TABLE statements.
The unique index on a primary key is called the primary
index.
When a primary key is defined in a CREATE TABLE statement, the primary index
is automatically created by the database manager.
When a primary key is defined in an ALTER TABLE statement, a primary index
is automatically created by the database manager even if a unique index exists
on the same columns of that primary key.
Integrity refers to the accuracy of data in the
database. Integrity is maintained in the following ways:
- An entire group of related changes is either made to the database, or the
entire operation is canceled. For example, when money is transferred
from one bank account to another, the database manager ensures that both the
deduction from the one account and the deposit to the other account complete
successfully or none of the changes are made. This is called
atomic integrity;
it protects other users and programs from using inconsistent data.
- Duplicate rows of information for the same entity can be avoided.
For example, an EMPLOYEE table consisting of employee number, employee name,
and department number can be defined so that values are unique for an employee
number and name, eliminating duplicate rows for any employee. This is
called entity integrity.
- Integrity of data in related tables can be ensured. For example, a
DEPARTMENT table may contain department numbers and other information related
to the EMPLOYEE table. A relation can be defined so that only valid and
existing department numbers as specified in the DEPARTMENT table can appear in
the EMPLOYEE table. Changes to the DEPARTMENT table can be
automatically reflected in the EMPLOYEE table. This is called
referential integrity.
Rules or referential constraints can be defined by users to ensure
referential integrity between tables.
The database manager protects other users and programs from using
inconsistent or wrong data by preventing more than one user or application
from simultaneously updating data; by allowing the user to rollback
uncommitted changes; and by using entity integrity and referential
integrity.
Entity integrity may be maintained in two ways: by defining a primary
key
on a table or placing a unique constraint on a column.
You define a primary key on a table to ensure that duplicate rows do not
occur.
The database manager enforces the uniqueness of the primary key by
automatically creating a unique index on its columns. A primary key is
a part of the table definition and is defined when the table is created or
altered. Primary keys are also used in defining referential
integrity.
Columns that are not used to define a primary key can be defined to have
unique values. Define a unique constraint on a column
when you wish the database manager not to accept a row of data if a unique
column already contains the same value in another row.
Referential integrity allows the definition of relationships
between tables such that the existence of values in one table depends on the
existence of the same values in another table. The database manager
supports referential integrity by providing for the definition of primary
keys, foreign keys, and through a set of rules defining the relationships
among the tables. Together, these are known as referential
constraints.
The relationship defined by a referential constraint is a set of
connections between the rows of two or more tables. The tables are
related through matching column values in the tables.
A table is considered a parent table if its primary key is referenced in a
referential constraint, or a dependent table if it has a foreign key and is
related to a parent table through a referential constraint. A table can
be both a parent and a dependent table, depending on its relationship to other
tables.
The relationship is defined using the CREATE TABLE statement for new tables
and the ALTER TABLE statement for existing tables. When you use these
statements, you specify the rules that must be followed in both parent and
dependent tables when rows are deleted.
The following relationships may occur:
- A parent table has a primary key and is a parent in at least
one relationship.
- A dependent table has at least one foreign key (defined below)
and is a dependent in at least one relationship. A table can be a
dependent in any number of relationships.
- A table can be both a dependent table and a parent table, but not of
itself.
- A table is a descendent of table T
if it is a dependent of T or it is a dependent of a descendent of T.
- An independent table is neither a parent nor a
dependent.
A foreign key consists of one or more columns in the
dependent table
that together must either take on a value that exists in the primary key of
the parent table, or be a null foreign key.
When a row is updated or inserted into a dependent table, each non-null
foreign key insert or update value must match a value of the corresponding
primary key in the parent table. There can be multiple foreign keys
defined on a dependent table
referencing the same or different parent tables. The columns in the
key may be nullable. If any of the columns contain a null value, the
foreign key value is considered null. If the foreign key value is not
null, then it must match an existing primary key value in the referencing
parent table.
A referential constraint consists of a foreign key, the identification of a
table containing a primary key, a constraint name and rules that govern
changes. A referential constraint requires that a value can exist in
one table (the dependent table) only if it also exists in another table (the
parent table). After referential constraints have been defined, the
enforcement of the referential constraint is immediate and the insert, update
and delete rules are enforced when the INSERT (or PUT), UPDATE, and DELETE
statements are issued. See ALTER TABLE and CREATE TABLE for information on how to declare
referential constraints.
Referential constraints can be specified when tables are defined, or they
can be added later. If they are added later, the database manager
checks the references in the existing data. You can either drop or
deactivate referential constraints
to load large volumes of data, for example. After you load your data,
you must recreate or reactivate your referential constraints.
See Activating and Deactivating Keys for more information.
In order to maintain referential integrity, delete rules are imposed on
all
relationships. Every relationship includes a delete rule that was
implicitly or explicitly specified when the referential constraint was
declared by creating a foreign key. The options are:
- RESTRICT
The deletion of a parent row is restricted. No deletions are allowed
on a parent row until it has no dependent rows. This is the default
action if no option is specified when the foreign key is created.
- CASCADE
The deletion of a row in the parent table will cause the deletion of any
dependent rows in a dependent table. When a dependent row is deleted,
if the dependent table is also a parent table, then the delete rule of the
referential constraint applies in turn. Each referential constraint in
which a table is a parent has its own delete rule, and all applicable delete
rules determine the result of the delete operation. Consequently a row
in the parent table cannot be deleted if the deletion cascades to any of its
descendents that has a dependent row in a referential constraint with a delete
rule of RESTRICT.
- SET NULL
The deletion of a row in a parent table causes the corresponding values of
the foreign key in any dependent rows to be set to null. Only nullable
columns of the foreign key are set to null.
You may delete rows from a dependent table at any time, without taking any
action on the parent table.
The following terminology applies to the delete rules.
- A table T2 is delete-connected
to another table T1 if a delete of rows in table T1 can involve table
T2. The following conditions determine whether tables are considered to
be delete-connected:
- Dependent tables are always delete-connected to their parents irrespective
of the delete rule.
- A table T2 is delete-connected to another table T1 if a delete of rows in
table T1 can cause a delete of rows in T2's parent table(s).
IBM-SQL
2
allows the concept of a self-referencing
table, one that is delete-connected to itself. Note that DB2 Server for
VSE & VM does not directly support a self-referencing table.
In the relationship below, T2 and TX are both delete-connected to
T1.
 View figure.
View figure.
- A table T2 is delete-connected through multiple paths
to table T1 if there is more than one relationship by which T2 is
delete-connected to T1.
In the diagram below, T2 is delete-connected to T1 with a delete rule of
RESTRICT through two paths, one through T3 and a second by direct path.
Note that T2 is not delete-connected to T1 along the path through T4 because a
delete of rows in T1 will not cause a delete of rows in T4, which is T2's
parent table along this path.
View figure.
- A referential cycle
is a set of referential constraints for two or more tables such that each
table in the set is a descendent of itself.
- A self-referencing table
is a table that is a parent and dependent in the same referential
constraint. The constraint is called a self-referencing
constraint.
These relationships are depicted in the following example.
View figure.
Table T3, T4 and T5 are dependents of table T2 which is a dependent of
table T1. Since T1 is a parent table, the delete rule of referential
constraint applies when a row of T1 is deleted. Specifically, deletion
of a row in table T1 will cause all dependent rows in table T2 to be
deleted. Since T2 is also a parent table, the delete rule of
referential constraint also applies when a row of T2 is deleted.
Specifically, the DELETE RESTRICT rule in table T3, the DELETE SET NULL rule
in table T4 and the DELETE CASCADE rule in table T5 will apply. Note
that if a row in T2 is to be deleted because its parent row in T1 is to be
deleted, and this row has a dependent row in T3, then the entire delete
operation will fail and will be rolled back.
It is necessary to impose restrictions on referential constraint
relationships to ensure that operations on delete-connected tables return
consistent results with no dependence on a defined order of operations.
The following restrictions are checked whenever a
referential constraint is defined when a table is created or altered.
- If a table has more than one referential constraint referencing the same
parent, all the delete rules on those constraints must be the same and must
not be SET NULL.
- If a table is delete-connected to the same parent through multiple paths,
all of the delete rules on a path, except for the last one, must be
CASCADE. The last delete rule on all paths must be the same, and must
not be SET NULL.
- A referential cycle involving two or more tables must not cause a table to
be delete-connected to itself. In general, for a referential cycle
involving n tables, where n >= 2, there can be at most n - 2
delete rules that are CASCADE. For example, in a referential cycle
involving two tables, neither delete rule can be CASCADE. In a
referential cycle involving four tables, at most two delete rules may be
CASCADE.
The following restriction is enforced when a DELETE statement is prepared
or preprocessed with a WHERE clause containing a subquery. If T2 is the
object table of a DELETE statement, and T1 is referenced in a subquery of the
WHERE clause, T1 must not be a table that can be affected by the DELETE on
T2. The following example demonstrates the principle.
DELETE FROM T2 WHERE FIELD2 IN (SELECT FIELD1 FROM T1);
The following rules are enforced on tables T1 and T2.
- T1 and T2 must not be the same table.
- T1 must not be a dependent of T2 in a relationship with a delete rule of
CASCADE or SET NULL.
- T1 must not be a dependent of another table T3 in a relationship with a
delete rule of CASCADE or SET NULL if deletes of T2 cascade to T3.
The database manager checks the implicit insert rules when a row is
inserted into either a parent table or a dependent table in a referential
structure.
When a row is inserted into a parent table, the database manager ensures
that:
- The primary key is unique and does not contain a null value.
When a row is inserted into a dependent table, the database manager
ensures that either:
- The foreign key has a matching primary key in the parent table, or
- The foreign key contains a null value in one or more of its
columns.
When a key value is updated, the database manager checks the implicit
update rules.
When a primary key is updated, the primary key must be unique and not null,
and all dependent rows must be deleted or updated before the parent row can be
updated.
When a foreign key is updated, it must have a matching primary key in the
parent table or be a null key. A foreign key is considered null when
any of its column values becomes null.
After a referential constraint has been defined, referential integrity is
immediately enforced and the primary and foreign keys are active. The
database manager ensures that data integrity is maintained.
You may want to deactivate referential constraints, for example, to improve
performance when loading large volumes of data. You can deactivate a
table's primary key, any of its foreign keys, or a dependent foreign
key. When any of these keys are deactivated, both the parent table and
dependent table become unavailable to all users except
the owner or someone possessing DBA authority.
After loading the data, referential constraints must be activated
again. Activating them causes the database manager to validate the
references in the data.
When the keys are reactivated, the referential constraints are
automatically enforced once again. See ALTER TABLE for more information on activating and deactivating
keys.
An index is an ordered set of pointers to rows of a base
table. Each index is based on the values of data in one or more table
columns. An index is an object that is separate from the data in the
table. When you request an index, the database manager builds this
structure and maintains it automatically.
Indexes are used by the database manager to:
- Improve performance. In most cases, access to data is faster than
without an index.
- Ensure uniqueness. A table with a unique index cannot have rows
with identical keys.
A view provides an alternative way of looking at the data in one
or more tables.
A view is a named specification of a result table. The specification
is a SELECT statement that is effectively processed whenever the view is
referenced in an SQL statement. Thus, a view can be thought of as
having columns and rows just like a base table. For retrieval, all
views can be used just like base tables. Whether a view can be used in
an insert, update, or delete operation depends on its definition as explained
in the description of CREATE VIEW. (See CREATE VIEW for more information.)
An index cannot be created for a view. However, an index created for
a table on which a view is based may improve the performance of operations on
the view.
When the column of a view is directly derived from a column of a base
table, that column inherits any constraints that apply to the column of the
base table. For example, if a view includes a foreign key of its base
table, INSERT and UPDATE operations using that view are subject to the same
referential constraint as the base table. Likewise, if the base table
of a view is a parent table, DELETE
operations using that view are subject to the same rules as DELETE operations
on the base table.
A package is an object that contains control structures (called
sections) used to process SQL statements.
Packages are produced during program preparation. The control
structures can be thought of as the bound or operational form of SQL
statements. All control structures in a package are derived from the
SQL statements embedded in a single source program.
The database manager maintains a set of tables containing information about
the data it controls. These tables are collectively known as the
catalog. The catalog tables contain information
about
objects such as tables, views, and indexes.
Tables in the catalog are like any other database tables. If you
have authorization, you can use SQL statements to look at data in the catalog
tables in the same way that you retrieve data from any other table. The
database manager ensures that the catalog contains accurate descriptions of
the relational database at all times.
All SQL programs run as part of an application
process.
An application process involves the execution of one or more programs, and is
the unit to which the database manager allocates resources and locks.
Different application processes may involve the execution of different
programs, or different executions of the same program.
More than one application process may request access to the same data at
the same time.
Locking is the mechanism used to maintain data integrity under
such
conditions, preventing, for example, two application processes from updating
the same row of data simultaneously.
The database manager acquires locks in order to prevent uncommitted changes
made by one application process from being perceived by any other. The
database manager will release all locks it has acquired on behalf of an
application process when that process ends, but an application process itself
can also explicitly request that locks be released sooner. This
operation is called
commit.
The recovery facilities of the database manager provide a means of
"backing out" uncommitted changes made by an application
process. This might be necessary in the event of an error on the part
of an application process, or in a "deadlock" situation. An
application process itself, however, can explicitly request that its database
changes be backed out. This operation is called
rollback.
A logical unit of work (LUW), also known as
a unit of work, is a recoverable sequence of operations within an
application process. At any time, an application process is a single
unit of work, but during the life of an application process there may be many
recovery operations performed as a result of the commit or rollback
operations.
A unit of work is initiated when an application process is
initiated. A unit of work is also initiated when the previous unit of
work is terminated by something other than the termination of the application
process. A unit of work is terminated by a commit operation, a rollback
operation, or the termination of a process. A commit or rollback
operation affects only the database changes made within the unit of work it
terminates. While these changes remain uncommitted, other application
processes are unable to perceive them and they can be backed out. Once
committed, these database changes are accessible by other application
processes and can no longer be backed out.
A lock acquired by the database manager on behalf of an application process
is held until its associated recovery operation has passed.
The initiation and termination of a unit of work define points of
consistency within an application process.
For example, a banking transaction might involve the transfer of funds from
one account to another. Such a transaction would require that these
funds be subtracted from the first account, and added to the second.
Following the subtraction step, the data is inconsistent. Only after
the funds have been added to the second account is consistency
reestablished. When both steps are complete, the commit operation can
be used to terminate the unit of work, thereby making the changes available to
other application processes.
Figure 1. Unit of Work with a Commit Statement
If a problem occurs before the unit of work terminates, the database
manager will back out uncommitted changes in order to restore the consistency
of the data that it assumes existed when the unit of work was
initiated.
Figure 2. Unit of Work with a Rollback Statement
Cursor operations within a single unit of work are not protected from the
result of other operations within the same unit of work. One example is
a DELETE statement that deletes a row selected by a previous OPEN
statement. Another example is two concurrently open cursors (at least
one of which is updateable) operating on some of the same data.
The isolation level associated with an application process
defines the degree of isolation of that application process from other
concurrently executing application processes. The isolation level of an
application process, P, therefore specifies:
- The degree to which rows read and updated by P are available to other
concurrently executing application processes
- The degree to which update activity of other concurrently executing
application processes can affect P.
Isolation level is specified as an attribute of a package and applies to
the application processes that use the package. The database manager
provides a means of specifying an isolation level of a package through the
program preparation process. The isolation levels are supported by
automatically locking the appropriate data. Depending on the type of
lock,
this limits or prevents access to the data by concurrent application
processes. The DB2 Server for VSE & VM database manager supports
three types of locks:
- Share
- Limits concurrent application processes to read-only operations on the
data.
- Update
- Limits concurrent application processes to read-only operations on the
data. This lock expresses an intent to possibly update the data.
If the data is updated, the database manager upgrades the lock to an exclusive
lock.
- Exclusive
- Prevents concurrent application processes from
accessing the data in any way.
The following descriptions of isolation levels refer to locking data in row
units. Data can be locked in larger physical units than base table
rows. However, logically, locking occurs at least at the base table row
level. Similarly, the database manager can escalate a lock to a higher
level.
An application process is guaranteed at least the minimum requested lock
level.
The DB2 Server for VSE & VM database manager supports three isolation
levels. Other database managers support additional levels (see the
IBM SQL Reference for details of these additional levels). Regardless of the
isolation level, it places exclusive locks on every row that is inserted,
updated, or deleted. Thus, all isolation levels ensure that any row
that is changed during a unit of work is not accessed by any other application
(except for those using an isolation level of UR) until the unit of work is
complete. The isolation levels are:
Level RR ensures that:
- Any row that is read during a unit of work is not changed by other
application processes until the unit of work is complete.
- Any row that was changed by another application process cannot be read
until it is committed by that application process.
In addition to any exclusive locks, an application process running at level
RR acquires at least share locks on all the rows it reads. Furthermore,
the locking is performed so that the application process is completely
isolated from the effects of concurrent application processes.
Like level RR, level CS ensures that:
- Any row that was changed by another application process cannot be
read until it is committed by that application process.
Unlike RR:
In addition to any exclusive locks, an application process running at level
CS has at least a share lock for the current row of every cursor.
Unlike CS or RR, level UR allows:
- Any row that is read during a unit of work to be changed by other
application processes.
- Any row that was changed by another application process to be read even if
that change has not been committed by that application process.
Level UR allows an application to access most uncommitted changes of other
applications. However, tables, views and indexes that are being created
or dropped by other applications are not available while the application is
processing. Any other changes by other applications can be read before
they are committed or rolled back.
Non-read-only statements under level UR will behave as if the isolation
level were cursor stability.
Like CS, UR does not completely isolate the application process from the
effects of concurrent application processes. At level UR, application
processes that run the same query more than once might see phantom rows, or
may experience nonrepeatable reads.
For example, a nonrepeatable read can occur in the following
situation:
- Application process P1 reads the row from the database, then goes on to
process other SQL requests.
- Application process P2 either modifies or deletes the row and COMMITs the
change.
- P1 attempts to read the original row again, and either receives the
modified row, or discovers that the original row has been deleted.
An application process running at level UR does not require any share
locks.
Isolation levels, Cursor Stability and Uncommitted Read, only apply to
Public dbspaces with ROW or PAGE level locking. Private dbspaces and
Public dbspaces with DBSPACE level locking always use Repeatable Read
isolation level. Data definition statements, such as CREATE, ACQUIRE or
GRANT, and any statements that access the System Catalogs are always executed
with Repeatable Read, regardless of the isolation level specified.
Another relational database manager may request the DB2 Server for VSE
& VM database manager to perform an operation on a DB2 Server for VSE
& VM database (see Application Requesters and Application Servers). If the request specifies an isolation level
other than one supported by the DB2 Server for VSE & VM database manager,
the level is changed accordingly:
- Read Stability (RS) is changed to level RR
For more information on these isolation levels, see the IBM SQL
Reference. Lock level escalation is discussed in the chapter on preprocessing and
running programs in the DB2 Server for VSE & VM
Application Programming manual.
The DB2 Server for VSE & VM database manager supports a facility that
allows programs to dynamically modify the isolation level. The fact
that a program will use this facility is indicated by the specification of the
value USER instead of a specific isolation level when the program is
prepared. Refer to the DB2 Server for VSE & VM
Application Programming manual for details on how to do this.
Application requesters and application servers work together to provide
data to an application, regardless of where that data is located. The
application requester accepts a database request from an
application and passes it to an application server. In a distributed
relational database, it transforms a database request from the application
into communication protocols suitable for use in a distributed database
network. The application server receives and processes the
requests sent by the application requester.
| Note: | An application requester is sometimes called a user machine in VM and a user
partition in VSE. An application server is sometimes called a database
machine in VM and a database partition in VSE.
|
In this example, an application requester in Rochester is requesting data
from an application server in Toronto.
Figure 3. Requesting and Receiving Data Between an Application Requester and Application Server
View figure.
An application process must be connected to the application server facility
of a database manager before SQL statements that reference tables or views can
be processed. A CONNECT statement establishes a connection between an
application process and its server. VM and CICS/VSE applications may
also use an implicit connection, in which case an explicit CONNECT statement
is not necessary. An application process has only one server at any
time, but the server can change when a CONNECT statement is processed.
A distributed relational database consists of a set of tables and other
objects that are spread across different but interconnected computer
systems. Each computer system has a relational database manager to
manage the tables and other objects in its environment. The database
managers communicate and cooperate with each other in a way that allows a
given database manager to process SQL statements on another computer
system.
The following diagram shows how data is requested and transmitted between
two relational database systems participating in a complete Distributed
Relational Database Architecture (DRDA)
relationship. Each of the two systems may request data from the
other.
Figure 4. Requester/Server Data Flow
View figure.
The following diagram shows supported IBM relational database DRDA
connections; AIX connections are the same as those for OS/2.
Incoming arrows indicate application server support; outgoing arrows
indicate application requester support. Note that the relationships
displayed are for unlike IBM systems only. Some of the systems shown
provide other protocols for like-system connections.
Figure 5. IBM Relational Database Connections
View figure.
Distributed relational databases are built on formal requester-server
protocols and functions. Working together, the application requester
and application server handle the communication and location considerations so
that the application is isolated from these considerations and can operate as
if it were accessing a local database. DB2 Server for VM supports
application servers and application requesters for DRDA communication
protocols. DB2 Server for VSE supports application servers and application
requesters for online CICS/VSE application programs for DRDA. |DB2 Server for VSE also provides Remote Unit of Work (RUOW)
|applicaton requester support for batch applications. For more information on DRDA communication protocols, see the
Distributed Relational Database Architecture Reference.
Two communication protocols can be used by the DB2 Server for VSE & VM
database manager. These protocols allow the data to be used within
distributed relational databases or as a non-distributed relational
database. The two protocols are:
- SQLDS
- A protocol for a DB2 Server for VSE & VM database manager to
communicate with other like database managers.
- DRDA
- A protocol for communicating with both like and
unlike database managers.
The following table shows the protocols that are used between DB2 Server
for VSE & VM application requesters and application servers.
| Application Requester
| Communication Protocol
| Application Server
|
| DB2 for VSE
| SQLDS
| DB2 Server for VM
Used for guest sharing.
|
| DB2 for VSE
| SQLDS
| DB2 Server for VSE
|
| DB2 for VSE
| DRDA
| DB2 Server for VSE
|
| DB2 for VSE
| DRDA
| DB2 Server for VM
|
| DB2 for VSE
| DRDA
| DB2 for MVS
|
| DB2 for VSE
| DRDA
| DB2 for OS/400
|
| DB2 for VSE
| DRDA
| DB2 for OS/2
|
| DB2 for VSE
| DRDA
| DB2 for AIX
|
| DB2 for VM
| SQLDS
| DB2 Server for VM
|
| DB2 for VM
| DRDA
| DB2 Server for VM
|
| DB2 for VM
| DRDA
| DB2 Server for VSE
|
| DB2 for VM
| DRDA
| DB2 for MVS
|
| DB2 for VM
| DRDA
| DB2 for OS/400
|
| DB2 for VM
| DRDA
| DB2 for OS/2
|
| DB2 for VM
| DRDA
| DB2 for AIX
|
For more information on the communication protocols, see the DB2 Server for VSE & VM Performance Tuning Handbook.
The application server can be local to or remote from the environment
where the process is initiated. This environment includes a local
directory that describes the application servers that can be identified in a
CONNECT statement. The format and maintenance of this directory are
described in the "Network Information" sections for each SQL product in
the Distributed Relational Database Connectivity Guide manual.
To process a static SQL statement that references tables or views, the
application server uses the bound form of the statement. This bound
statement is taken from a package that the database manager previously created
through a bind operation.
|Data managed by any remote application server that implements the
|DRDA architecture can be accessed and manipulated by VSE Batch application
|programs that have the ability to execute SQL statements.
A remote unit of work (RUOW) is a logical unit of work that allows for the
remote preparation and execution of SQL statements. An application
process at computer system A can connect to an application server at computer
system B and, within one or more logical units of work, process any number of
static or dynamic SQL statements that reference objects at B. After
terminating a unit of work at B, the application process can connect to an
application server at computer system C, and so on.
The DB2 Server for VM requester can remotely prepare and run most SQL
statements given the following conditions:
- All objects referenced in a single SQL statement are managed by the same
application server.
- All of the SQL statements in a unit of work are processed by the same
application server.
The DB2 Server for VSE requester can remotely prepare and run most
SQL statements given the following conditions:
- The Online Resource Adapter must be enabled.
- The remote server must be known to the Online Resource Adapter.
|DB2 Server for VSE also provides DRDA support that consists of
|remote unit of work (RUOW) Application Requester (AR) support for Batch
|applications.
A distributed unit of work (DUOW) is a logical unit of work that allows a
user or application program to read or update data at multiple
locations. An application process at computer system A can connect to
an application server at computer system B, process static or dynamic SQL
statements that reference objects at B, then connect to an application server
at computer system C, and process SQL statements that reference objects at C,
and so on, before terminating the unit of work. Each SQL statement can
access one application server. Commits and rollbacks are coordinated at
all locations so that if a failure occurs anywhere in the system, data
integrity is preserved.
This section will mainly be of interest to people who are writing
applications that are:
- DB2 Server for VSE CICS applications, or are to be run on DB2 Server
for VM application requesters and
- accessing data that is controlled by the application servers of one or
more unlike relational database managers.
The section will also be of interest to people with the opposite
requirement (for instance a DB2 for OS/2 application requester connected to a
DB2 Server for VM or DB2 Server for VSE application server).
The DB2 family's support of SQL is a superset of SQL92 Entry Level
(SQL92E).
3
Not all DB2 family members support all elements of
SQL. For a complete discussion of the individual family members'
support of SQL, please see the IBM SQL Reference, Version 2, Volume
1.
For the most part, an application may use the statements and clauses that
are supported by the database manager of the application server to which it is
currently connected even though that application may be running on the
application requester of a database manager that does not support some of
those statements and clauses.
There are some restrictions that apply. Due to the different
availability dates of the IBM relational database products, it is not possible
to provide a complete list of these. The rest of this section will,
therefore, outline some general guidelines that govern the inter-operability
of statements and provide examples of statements that can and cannot be used
among products.
- All Data Definition and Authorization statements that are supported by an
application server can be issued from any application requester.
Example: A CICS application running as a DB2 Server for VSE application requester connected to a DB2 for MVS
application server may use a CREATE TABLESPACE statement. Similarly, an
application running on a DB2 for MVS application requester connected to a DB2
Server for VM or DB2 Server for VSE application server may use an ACQUIRE
DBSPACE statement.
- Most other statements that do not contain any host variables can be issued
from any application requester.
Example: An application running on a DB2 Server for VM
application requester connected to a DB2 for MVS application server may issue
the following statement even though the DB2 Server for VM database manager
does not support the WITH HOLD clause.
EXEC SQL DECLARE PRIMARY_CURSOR CURSOR WITH HOLD
FOR SELECT_COURSES;
- Some statements without host variables are not sent to the application
server; rather, they are processed completely by the application
requester. Such statements may only be used on application requesters
of products that support statements.
Example 1: An application running on a DB2 Server for VM
application requester cannot issue the DECLARE STATEMENT statement against a
DB2 for MVS application server.
Example 2: An application running on a DB2 Server for VM
application requester cannot issue the DECLARE VARIABLE statement against a
DB2 for OS/400 application server.
- Some statements without host variables are the joint responsibility of the
application requester and application server. Such statements must be
fully understood by the application requester.
Example: An application running on a DB2 Server for VM
application requester connected to a DB2 for OS/400 application server cannot issue the following statement, because
the PRIOR clause is not supported by the DB2 Server for VM database
manager.
EXEC SQL FETCH PRIOR FROM PAGE_CURSOR;
- If a statement or clause contains host variables and an application
requester does not understand that statement or clause, those host variables
are assumed to be input host variables. If this is not a valid
assumption, the application server will reject the statement.
Example 1: An application running on a DB2 Server for VM
application requester could issue the following statement to a DB2 for MVS
application server:
EXEC SQL SET CURRENT SQLID = :CUR_USER;
because :CUR_USER references an input host variable.
Example 2: However, an application running on a DB2 Server
for VM application requester could not issue the following statement to a DB2
for MVS application server:
EXEC SQL SET :TIME_UPDATED = CURRENT TIME;
because :TIME_UPDATED references an output host variable.
- Only DB2 Server for VSE & VM supports Extended Dynamic SQL.
However, an application on a DB2 Server for VM application requester or a DB2 Server for VSE CICS application requester can issue most extended dynamic statements for non-modifiable
packages against unlike application servers. A list of restrictions can
be found in Appendix G, DRDA Considerations.
- Only DB2 Server for VSE & VM supports Insert Cursors. However,
an application on a DB2 Server for VM application requester or a DB2 Server for VSE CICS application requester can declare Insert Cursors and issue PUT statements against unlike
application servers. Note that there is no blocking of input data
because the application requester turns PUT statements into INSERT
statements. The purpose of this support is to allow an application to
run without having to make this change in the source program.
- In IBM-SQL, all objects (that is, tables, views, indexes, and packages)
have a two-part name. DB2 for MVS application servers also support
three-part names for tables, views, and aliases (a non-IBM-SQL
object). The high order part of the name identifies an application
server (also called a location in DB2 for MVS). In addition
to the heterogeneous remote unit of work facility using DRDA protocols among
unlike products, DB2 for MVS supports a homogeneous distributed unit of
work facility using private protocols. This facility makes use of
three-part names in order to allow statements within the same unit of work to
be issued against different application servers as long as data is only
modified at one of those application servers.
For example, an application which is run on a DB2 Server for VM application
requester can issue the following statements in order to read data controlled
by DB2 for MVS application servers at Halifax, Montreal and Toronto and use
the information obtained there to update a DB2 for MVS table at
Halifax.
EXEC SQL CONNECT TO HALIFAX;
EXEC SQL SELECT SUM(WEEKLY_NET) -- processed by DB2 at Halifax
INTO :TOT3
FROM FORCASTING.SALES;
EXEC SQL SELECT SUM(WEEKLY_NET) -- routed by DB2 at Halifax to be
-- processed by DB2 at Montreal
INTO :TOT1
FROM MONTREAL.FORCASTING.SALES;
EXEC SQL SELECT SUM(WEEKLY_NET) -- routed by DB2 at Halifax to be
-- processed by DB2 at Toronto
INTO :TOT2
FROM TORONTO.FORCASTING.SALES;
TOT = TOT1 + TOT2 + TOT3;
EXEC SQL UPDATE FORCASTING.TOTALS -- processed by DB2 at Halifax
SET WEEKLY_NET = :TOT;
DRDA protocols are used in the communications between the application
requester and the application server at Halifax. Private DB2 for MVS
protocols are used in the communications between Halifax and Toronto as well
as the communications between Halifax and Montreal. Three-part names
allow statements within the same unit of work to be issued against different
application servers.
For more information on distributed unit of work, refer to the DB2 for MVS
library.
Different systems represent data in different ways. When data is
moved from one system to another, data conversion
must sometimes be performed. Products supporting DRDA will
automatically perform any necessary conversions at the receiving
system.
With numeric data, the information needed to perform the conversion
is the data type of the data and how that data type is represented by the
sending system. For example, when a floating point variable from an
OS/400 application requester is assigned to a column of a table at a VM
application server, the DB2 Server for VM database manager, knowing the data
type and the sending system, converts the number from IEEE format to |S/390 format.
With character data,
additional information is needed to convert character strings. String
conversion depends on both the coded character set of the data and the
operation that is to be performed with that data. Character conversions
are performed in accordance with the IBM Character Data Representation
Architecture (CDRA). For more information on character conversion,
refer to Character Data Representation Architecture Reference and
Registry.
A string is a sequence of bytes that may represent
characters. Within a string, all the characters are represented by a
common coding representation. In some cases, it might be necessary to
convert these characters to a different coding representation. The
process of conversion is known as character conversion.
Character conversion, when required, is automatic and is transparent to the
application when it is successful. A knowledge of conversion is
therefore unnecessary when all the strings involved in a statement's
execution are represented in the same way. This is frequently the case
for stand-alone installations and for networks within the same
country. Thus, for many readers, character conversion may be
irrelevant.
Character conversion can occur when an SQL statement is processed
remotely. Consider, for example, these two cases:
- The values of host variables sent from the application requester to the
application server
- The values of result columns sent from the application server to the
application requester.
In either case, the string could have a different representation at the
sending and receiving systems. Conversion can also occur during string
operations on the same system.
The following list defines some of the terms used when discussing character
conversion.
- character set
- A defined set of characters.
For example, the following character set appears in several code pages:
- 26 non-accented letters A through Z
- 26 non-accented letters a through z
- digits 0 through 9
- . , : ; ? ( ) ' " / - _ & + % * =
< :>
- code page
- A set of assignments of characters to code points.
In EBCDIC, for example, 'A' is assigned code point X'C1'
and 'B' is assigned code point X'C2'. Within a code
page, each code point has only one specific meaning.
- code point
- A unique bit pattern that represents a character.
- coded character set
- A set of unambiguous rules that establish a character set and the
one-to-one relationships between the characters of the set and their coded
representations.
- encoding scheme
- A set of rules used to represent character data.
For example:
- Single-Byte EBCDIC
- Single-Byte ASCII (see Note)
- Double-Byte EBCDIC
- Mixed Single-, Double- and Multi-Byte ASCII.
| Note: | Single-Byte ASCII is an encoding scheme used to represent strings in many
environments, including OS/2. In the OS/2 environment, ASCII refers to
the PC Data encoding scheme.
|
- substitution character
- A unique character that is substituted during character conversion for any
characters in the source coding representation that do not have a match in the
target coding representation.
The following example shows how a typical character set might map to
different code points in two different code pages.
View figure.
Even with the same encoding scheme, there are many different coded
character sets, and the same code point can represent a different character in
different coded character sets. Furthermore, a byte in a character
string does not necessarily represent a character from a single-byte character
set (SBCS). Character strings are also used for mixed and bit
data. Mixed data is a mixture of single-byte characters,
double-byte characters and possibly multi-byte characters. On some
platforms, mixed data may be comprised of 2, 3, 4 or more bytes.
Bit data is not associated with any character set. Note that
this is not the case with graphic strings; the database manager assumes
that every pair of bytes in every graphic string represents a character from a
double-byte character set (DBCS).
For more details on character conversion, see:
IBM's Character Data Representation Architecture (CDRA) deals with
the differences in string representation and encoding. The Coded
Character Set Identifier (CCSID) is a key element of this
architecture.
A CCSID is a 2-byte (unsigned) binary number that uniquely identifies an
encoding scheme and one or more pairs of character sets and code pages.
A CCSID is an attribute of strings, just as a length is an attribute
of strings. In DB2 Server for VSE & VM databases, different
columns can have different CCSID attributes and each string in a column has
the CCSID attribute of that column. Note that not all IBM relational
database managers support the specification of CCSIDs at the column
level.
Character conversion involves the use of a CCSID Conversion Selection
Table.
The Conversion Selection Table, which is stored in the
SYSTEM.SYSSTRINGS catalog table, contains a list of valid source and
target combinations. For each pair of CCSIDs, the Conversion Selection
Table contains information used to perform the conversion from one coded
character set to the other. This information includes an indication of
whether conversion is required. (In some cases, no conversion is
necessary even though the strings involved have different CCSIDs.)
Every application server and application requester has a default
CCSID (or default CCSIDs in installations that support DBCS data). A
list of the CCSIDs supported by the DB2 Server for VSE & VM database
manager can be found in the CCSID column of the SYSTEM.SYSCCSIDS
catalog table.
A default CCSID is the CCSID of the default subtype; for
example, the USER special register could have either an SBCS or mixed subtype,
and its default CCSID would be the subtype's CCSID specified by the
application server. The CCSID of the following types of strings is
determined at the application server:
- String constants
- Special registers with string values (such as USER and CURRENT SERVER)
- The result of the scalar functions CHAR, DIGITS, HEX, and VARGRAPHIC
- String columns defined by CREATE TABLE and ALTER TABLE statements
- The character representation of datetime values.
The default CCSID of strings stored in host variables is determined at the
application requester.
Statements are converted from the default CCSID of the application
requester to the default CCSID of the application server.
When an application server or application requester is initialized with
PROTOCOL=SQLDS (see SQLSTART and SQLINIT in the DB2
Server for VSE & VM Database Administration manual), the default CCSID of the application requester is the same as that
of the application server regardless of the values reported on the application
requester when an SQLINIT QUERY is performed.
When an application requester accesses a local application server,
the default CCSID of the application requester is the same as that of the
application server, regardless of the values reported on the application
requester when a DSQQ transaction is performed.
Users can successfully process SQL statements only if they are authorized
to perform the specified function. To create a table, a user must be
authorized to create tables; to alter a table, a user must be authorized
to alter the table; and so forth.
Two forms of permission exist:
- Authority to
- connect to a specific database manager
- allocate resources such as private dbspaces and public dbspaces
- administer the database manager. This is called DBA
(Database Administrator) authority.
- Privilege to
- access objects in the database
- create indexes on specific tables.
Authorization, then, refers to who is allowed to access what
data, whereas privileges refer to how an authorized user can use
the data. For example, authorized users can create, modify, and delete
tables. These users then have privileges on those tables and can
selectively grant and revoke those privileges to other users.
The person or persons holding DBA authority are charged with the task of
controlling the database manager and are responsible for the safety and
integrity of the data. Those with DBA authority control who will have
access to the database manager and the extent of this access.
Footnotes:
- 1
-
The DB2 REXX SQL feature must be installed.
- 2
-
This is the term used to refer to IBM's SQL as published in the IBM SQL
Reference, Volume 1 (SC26-8416)
- 3
-
SQL92E is the term used to refer to the combination of the following
standards:
- ISO (International Standards Organization) 9075-1992(E)
- ANSI (American National Standard for Information Systems)
X3.135-1992
- FIPS (Federal Information Processing Standards) publication 127-2.
The above documents list more than one level of conformance. The
levels are Entry, Transitional (FIPS only), Intermediate, and Full SQL.
We are concerned with Entry SQL and we designate that with the abbreviation
SQL92E.
[ Top of Page | Previous Page | Next Page | Table of Contents | Index ]
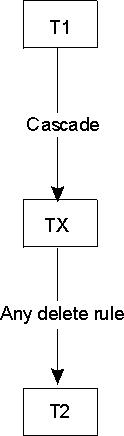 View figure.
View figure.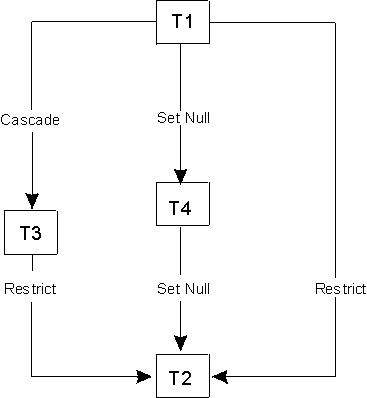 View figure.
View figure.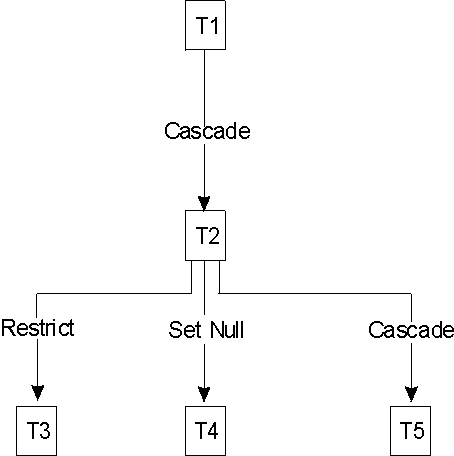 View figure.
View figure.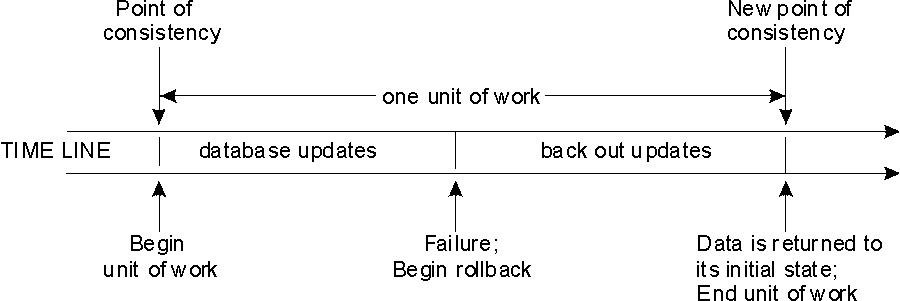 View figure.
View figure.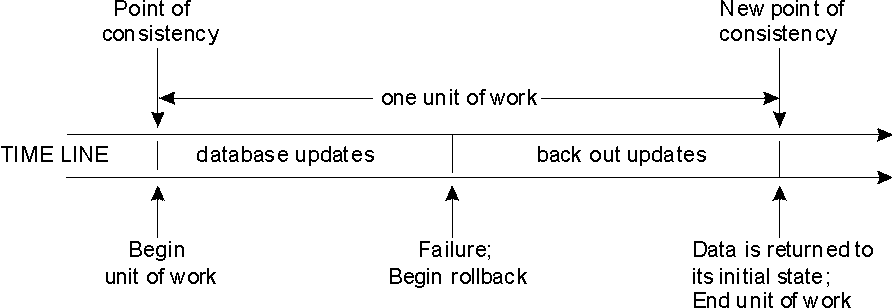 View figure.
View figure.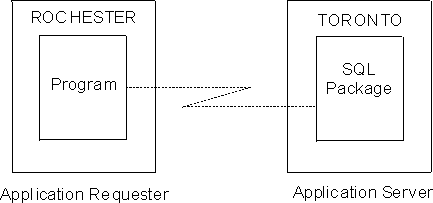 View figure.
View figure.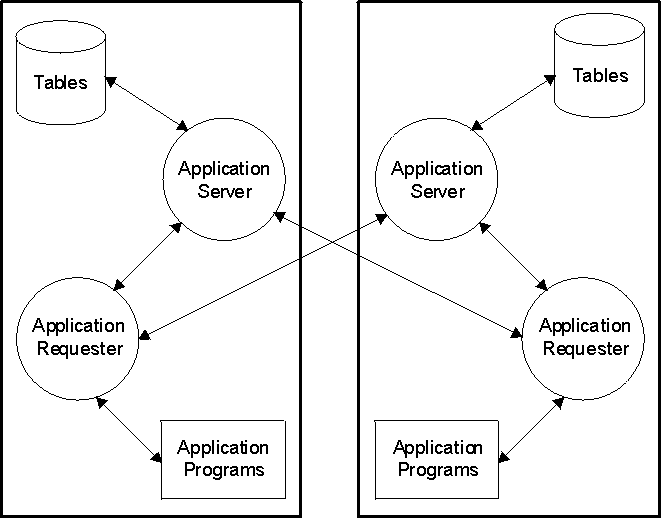 View figure.
View figure.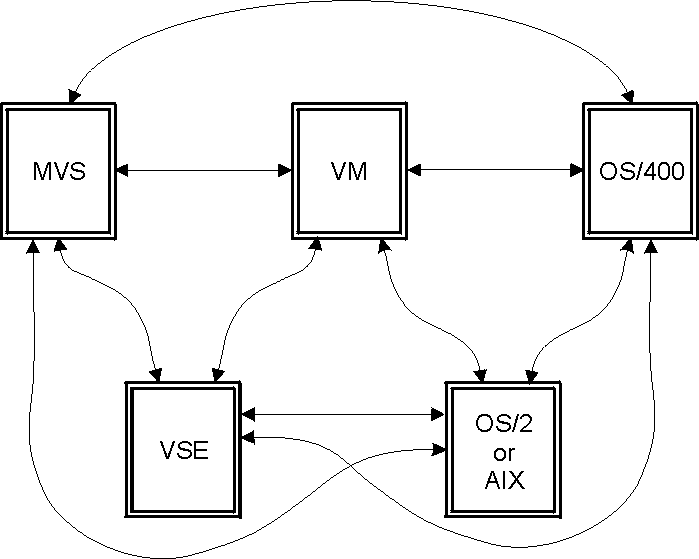 View figure.
View figure. View figure.
View figure.