 View figure.
View figure.This chapter defines the basic syntax of SQL and language elements that are common to many SQL statements.
The basic symbols of keywords and operators in the SQL language as supported by this product are single-byte EBCDIC characters. Characters of the language are classified as letters, digits, or special characters.
A letter is any one of the uppercase characters A through Z, the lowercase letters a through z, plus the three characters reserved as alphabetic extenders for national languages (for example, in code page 37, $ is at 5B, # is at 7B, @ is at 7C).
A digit is any of the characters 0 through 9.
A special character is one of the characters listed below:
| space | / | slash | |
| " | quote or double-quote | : | colon |
| % | percent | ; | semi-colon |
| & | ampersand | < | less than |
| ' | apostrophe or single quote | = | equals |
| ( | left parenthesis | > | greater than |
| ) | right parenthesis | ? | question mark |
| * | asterisk | _ | underscore |
| + | plus sign | ¬ | logical NOT * |
| , | comma | ^ | caret * |
| - | minus sign | | | vertical bar * |
| . | period | ! | exclamation point * |
* Not supported in IBM-SQL. For portability of programs, consider alternative characters.
A character set composed of characters not found in the default U.S. English EBCDIC character set can be created (thus, for instance, expanding the set of characters defined as letters). Such a character set could be useful in folding, which converts lowercase characters of a character string into uppercase. For information on how to create these characters, refer to the section on defining your own character set in the DB2 Server for VM System Administration or DB2 Server for VSE System Administration manual. Also, see SYS CHARSETS.
The basic syntactic units of the language are called tokens. A token consists of one or more characters, excluding the blank character, and excluding characters within a string constant (for example 'string') or delimited identifier (for example "field1"). These terms are defined later.
Tokens are classified as ordinary or delimiter tokens:
Examples:
1 .1 +2 3 :SALARY E SELECT
Examples:
'string' "field1" = , .
A space is a sequence of one or more blank characters. Tokens, other than string constants and delimited identifiers, must not include a space. Any token can be followed by a space. Every ordinary token must be followed by a delimiter token or a space. If the syntax does not allow an ordinary token to be followed by a delimiter token, that ordinary token must be followed by a space.
Static SQL statements may include host language comments or SQL comments. Either type of comment may be specified wherever a space may be specified, except within a delimiter token or between the keywords EXEC and SQL. SQL comments are introduced by two consecutive hyphens (--) and terminated by the end of the line. For more information, see SQL Comments.
Letters used in an ordinary token other than a C variable must be uppercase letters. Thus, lowercase letters can only be used in string constants, delimited identifiers, and C language host variables. In all other tokens, the lowercase letters will be folded to uppercase.
An identifier is a token used to form a name. An identifier in an SQL statement is either an SQL identifier or a host identifier.
There are two types of SQL identifiers: ordinary identifiers and delimited identifiers.
Most ordinary identifiers may include DBCS characters if the following support is true:
| Note: | The ordinary identifiers that cannot include DBCS characters are identified in Naming Conventions. |
See SYS OPTIONS for more information on the DBCS and CHARNAME options.
Examples:
WKLYSAL WKLY_SAL "WKLY_SAL" "UNION" "wkly sal" "wkly_sal" "Dave's Table" Note that "Dave"s Table" is incorrect.
SQL identifiers are also classified according to their maximum length. A long identifier has a maximum length of 18 bytes. A short identifier has a maximum length of 8 bytes. The length of either a long or short identifier does not include quotation marks around delimited identifiers.
A host_identifier is a name declared in a host program. The rules for forming a host_identifier are the rules of the host language. In addition, a host_identifier:
The rules for forming a name depend on the type of the object designated by the name. Though names may include any character, it is not advisable to use special characters, such as #, @, or $, with the DRDA protocol. Special characters may not be supported by all code pages (see Character Conversion for more information on code pages).
The syntax diagrams use the metavariables in the following list to represent actual object names and values. The list does not include all metavariables used; there are also metavariables whose scope is limited to a particular diagram and these are defined locally.
.-,---------------.
V |
>>----host_variable---+----------------------------------------><
In this context, a host_variable can also reference a host structure. See Host Structures and Indicator Arrays for more information on host structures.
>>-+---------------------+---+-package_id------+--------------->< +-collection_id--.----+ '-host_identifier-' '-host_identifier--.--'
If a host_identifier is used it must be CHAR(8) and, if the name in the host_identifier is less than 8 characters, it must be padded to the right with blanks.
In C, the host variable must have a datatype of C NUL-terminated and a length of 9.
An authorization ID is a character string that is obtained by the database manager when a connection is established between the database manager and either an application process or a program preparation process. It designates a set of privileges. It may also designate a user or a group of users, but this property is not controlled by the database manager.
Authorization IDs are used by the database manager to provide:
An authorization ID applies to every SQL statement. The authorization ID that applies to a static SQL statement is the authorization ID that is used during program preparation. The authorization ID that applies to a dynamic SQL statement is the authorization ID that was obtained by the database manager when a connection was established between the database manager and the process. This is called the run-time authorization ID.
An authorization-name specified in an SQL statement should not be confused with the authorization ID of the statement. An authorization-name is an identifier that is used in GRANT and REVOKE statements to designate a target of the grant or revoke. It cannot be identical to the authorization ID of the GRANT or REVOKE statement. Note that the premise of a grant of privileges to X is that X will subsequently be the authorization ID of statements which require those privileges.
Examples:
Assume SMITH is your user ID and the authorization ID that the database manager obtained when the connection was established with the application process. You process the following statement interactively:
GRANT SELECT ON TDEPT TO KEENE
SMITH is the authorization ID of the statement. Thus, the authority to process the statement is checked against SMITH and SMITH is the implicit qualifier of TDEPT.
KEENE is an authorization-name specified in the statement. KEENE is given the SELECT privilege on SMITH.TDEPT.
Assume SMITH has administrative authority and is the authorization ID of the following statements:
DROP TABLE TDEPT
Removes the SMITH.TDEPT table.
DROP TABLE SMITH.TDEPT
Removes the SMITH.TDEPT table.
DROP TABLE KEENE.TDEPT
Removes the KEENE.TDEPT table.
For information about specifying the data types of columns, see CREATE TABLE.
The smallest unit of data that can be manipulated in SQL is called a value. How values are interpreted depends on the data type of their source. The sources of values are:
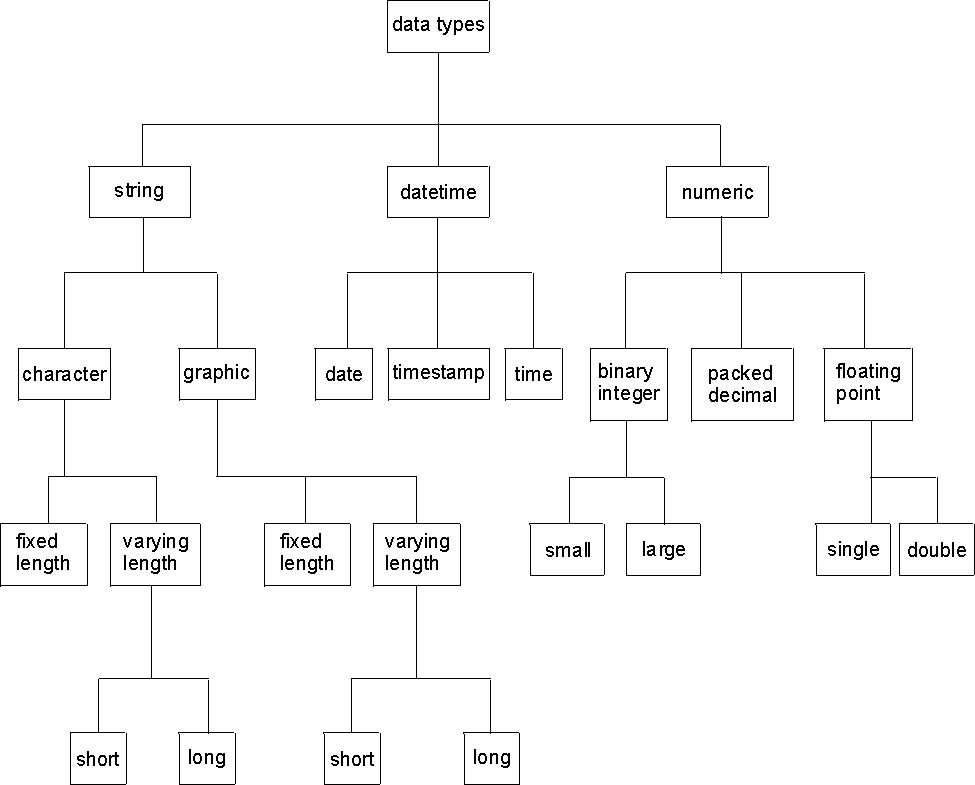
Figure 6 illustrates the various data types supported by the database manager.
Figure 6. Data Types Supported by the Database Manager
View figure.
|This data type is used to identify host variables that are used by the DB2 |Server for VSE & VM requester to uniquely indicate a query result set |returned by a stored procedure. These host variables are called result |set locator variables. They are only supported in client applications |written in Assembler, C, COBOL, and PL/I. These variables should be |included in the SQL DECLARE section and cannot be array variables.
|The syntax used to declare a result set locator variable for each language |follows:
|
RESULT SET LOCATOR
|--+-| Assembler |-+--------------------------------------------|
+-| C |---------+
+-| COBOL |-----+
'-| PL/I |------'
Assembler
|---variable-name----+-DC-+--F----------------------------------|
'-DS-'
C
|---+---------+---+----------+---------------------------------->
+-auto----+ +-const----+
+-extern--+ '-volatile-'
+-static--+
'-_Packed-'
.-,---------------------------------.
V |
>-----SQL TYPE IS RESULT_SET_LOCATOR VARYING-----variable-name--+--------------+--+---;->
'-= init-value-'
>---------------------------------------------------------------|
COBOL
|---01--variable-name--SQL TYPE IS RESULT-SET-LOCATOR VARYING--.-->
>---------------------------------------------------------------|
PL/I
|---+-DECLARE-+---+-variable-name----------------+-------------->
'-DCL-----' | .-,----------------. |
| V | |
'-(-----variable-name---+---)--'
>----SQL TYPE IS RESULT_SET_LOCATOR VARYING--+---------------------------------------+---;->
'-Alignment and/or Scope and/or Storage-'
>---------------------------------------------------------------|
All data types include the null value. The null value is a special value that is distinct from all non-null values; it denotes an unknown value. Although all data types include the null value, columns defined as NOT NULL cannot contain null values.
A character string is a sequence of bytes. The length of the string is the number of bytes in the sequence. If the length is zero, the value is called the empty string.
The empty string should not be confused with the null value.
All values of a fixed-length string column have the same length, which is determined by the length attribute of the column.
The length attribute must be between 1 and 254 inclusive. Therefore, every fixed-length string column is a short string column.
The values of a varying-length string column can have different lengths. The maximum length is determined by the length attribute of the column. The length attribute must be between 1 and |32,767.
A varying-length character string column with a length attribute greater than 254 is a long string column;
otherwise it is a short string column. A derived character string with a maximum length greater than 254 is a long string; otherwise it is a short string. Long strings and long string columns cannot be referenced in:
The SUBSTR function can be used to convert portions of long strings to short strings. A further restriction on long strings is that, although the argument of the SUBSTR function may be a long string, the result cannot be a long string.
Note also that blocking is turned off for any
cursor operation involving a long string.
Fixed-length string variables can be used in all host languages except REXX. Varying-length string variables can be used in all host languages except FORTRAN.
Varying-length string variables in Assembler, C, and COBOL are simulated. In C, varying-length string variables can also be represented by NUL-terminated strings. String variables with values longer than 254 bytes are subject to the same restrictions as long string columns.
Each character string is further defined as having one of the following subtypes:
Each database has a default character subtype, either SBCS or mixed. Host variables assume the default character subtype value. This default subtype can be overridden on a per package basis. Different rules for truncation, padding, and concatenation apply to character subtypes.
If mixed data values are used then the following rules apply to ensure proper formation.
'xy<(AABB)' '(AABB)<xy'
'xy<' '<'
'xy<(AABB)<(CC)' '(GG)> abc>de' '><(AA)' '>' '>xyz'
'xy<(AABBC)>'
'<><(BB)>' '<(AA)><(BB)>' 'xy<>z' '<>xyz<><>'
Generally, redundant pairs will not affect "character sensitive" facilities. For example, in the case of the LIKE predicate, specifying:
WHERE COL1 LIKE '%A<>'
is identical to
COL1 LIKE '%A'
| Note: | The basic equal predicate is not "character sensitive." For
example, specifying:
WHERE COL1 = 'A<>' would not find a match on the column value 'A' |
In order for the database manager to recognize double-byte characters in a mixed data string, two conditions must be present:
The pairing is detected as the string is read from left to right. The code X'0E' is interpreted as a shift-out character if X'0F' occurs later; otherwise it is incorrect. The first X'0F' following the X'0E' is the paired shift-in character.
There must be an even number of bytes between the paired characters, and each pair of bytes is considered to be a double-byte character. There can be more than one set of paired shift-out and shift-in characters in the string.
The length of a mixed data string is its total number of bytes, counting two bytes for each double-byte character and one byte for each shift-out or shift-in character.
The method of representing DBCS characters within a mixed data string differs between ASCII and EBCDIC.
When defining mixed data, the integer specified in
CHAR(integer)
indicates the number of bytes to be used for the column. One effect of this is that more double-byte characters can be stored in a mixed ASCII column than in a mixed EBCDIC column.
Examples:
Because of these differences, mixed data is not transparently portable between DB2 for OS/2 and DB2 Server for VSE & VM. To minimize the effects of these differences, use varying-length strings in applications that require mixed data and operate on both ASCII and EBCDIC systems. In the previous example, this would mean defining the columns as VARCHAR(10).
Extended UNIX Code (EUC) also allows for a form of ASCII mixed data. It is an encoding scheme supported by UNIX in far eastern countries which allows for MBCS characters. Each EUC codepage is made up of three character sets, or planes, denoted by G0, G1, and G2 or four character sets, denoted by G0, G1, G2 and G3. The group in which the data belongs is determined by the range of its first and second bytes. G0 is comprised of single-byte characters and is the ASCII invariant coded character set. G1 characters are double-byte characters within another range. G2 and G3 characters are triple-byte characters, distinguished by the first byte and the range of the last three bytes.
A graphic string is any sequence of double-byte characters (and does not include shift-out or shift-in characters). The length of the string is the number of its characters. Like character strings, graphic strings can be empty. There is no subtype associated with graphic strings.
Every graphic string has a CCSID that identifies a double-byte coded character set. If necessary, a graphic string is converted before it is used in an operation with a graphic string that has a different CCSID.
All values of a fixed-length graphic column have the same length, given by the length attribute of the column. The length attribute cannot be greater than 127. Therefore, every fixed-length graphic string column is a short string column.
The values of a varying-length graphic string column can have different lengths. The maximum length is determined by the length attribute of the column. The length attribute must be between 1 and 16383.
A varying-length graphic string column with a length attribute greater than 127 is a long string column; otherwise it is a short string column. A derived graphic string with a maximum length greater than 127 is a long string; otherwise it is a short string. Long graphic strings are subject to the same limitations that apply to long character strings.
Graphic variables can be used in COBOL, PL/I, and REXX.
All numbers have a sign and a precision.
The precision of binary integers and decimal numbers is the total number of binary or decimal digits excluding the sign. The precision of floating-point numbers is either single or double, referring to the number of hexadecimal digits in the fraction. If a column value is zero, the sign is positive.
A small integer is a System/390* binary integer with a precision of 15 bits. The range of small integers is -32768 to 32767.
A large integer is a System/390 binary integer with a precision of 31 bits. The range of large integers is -2,147,483,648 to +2,147,483,647.
A single precision floating-point number is a System/390 short (32 bits) floating-point number.
The range of magnitude is approximately -7.2E75 to -5.4E-79, 0, +5.4E-79 to 7.2E+75.
A double precision floating-point number is a |System/390 long (64 bits) floating-point number. The range of magnitude is approximately -7.2E75 to -5.4E-79, 0, +5.4E-79 to 7.2E+75.
A decimal value is a packed decimal number with an implicit decimal point. The position of the decimal point is determined by the precision and the scale of the number.
The scale, which is the number of digits in the fractional part of the number, can be neither negative nor greater than the precision. The maximum precision is 31 digits.
All values of a decimal column have the same precision and scale. The range of a decimal variable or the numbers in a decimal column is -n to +n, where the absolute value of n is the largest number that can be represented with the applicable precision and scale. The maximum range is from 1.0E-31 up to but not including 1.0E+32.
| Note: | The precision always remains equal to the attribute that defined the precision. For example, a decimal data type defined with a 6,2 attribute cannot have a 7,2 value stored in it. |
Binary integer variables can be used in all host languages. Floating-point variables can be used in all host languages. Decimal variables can be used in all host languages except C and FORTRAN.
Although datetime values can be used in certain arithmetic and string operations and are compatible with certain strings, they are neither strings nor numbers. However, strings can represent datetime values; see String Representations of Datetime Values.
A date is a three-part value (year, month, and day) designating a point in time under the Gregorian calendar, which is assumed to have been in effect from the year 1 A.D. The range of the year part is 0001 to 9999. The range of the month part is 1 to 12. The range of the day part is 1 to x, where x is 28, 29, 30, or 31, depending on the month.
| Note: | Historical dates do not always follow the Gregorian calendar. For example, dates between 1582-10-04 and 1582-10-15 are accepted as valid dates although they never existed in the Gregorian calendar. |
The internal representation of a date is a string of
4 bytes in packed decimal notation. Each byte consists of two decimal digits. The first 2 bytes represent the year, the third byte the month, and the last byte the day.
The length of a DATE column as described in the catalog is four bytes, representing the internal length. The length of a DATE column as described in the SQLDA is ten bytes, unless your site specified a date installation exit when the database manager was installed. In the latter case, the string format of a date may be up to 254 bytes in length.
A time is a three-part value (hour, minute, and second) designating a time of day using a 24-hour clock. The range of the hour part is 0 to 24, while the range of the minute and second parts is 0 to 59. If the hour is 24, the minute and second specifications are both zero.
The internal representation of a time is a string of 3 bytes. Each byte consists of two digits in packed decimal notation. The first byte represents the hour, the second byte the minute, and the last byte the second.
The length of a TIME column as described in the catalog is 3
bytes, representing the internal length. The length of a TIME column as described in the SQLDA is 8 bytes, unless your site specified a time installation exit when the database manager was installed. In the latter case, the string format may be up to 254 bytes in length.
A timestamp is a seven-part value (year, month, day, hour, minute, second, and microsecond) that designates a date and time as defined previously, except that the time includes a specification of microseconds. The range of the microsecond part is 000000 to 999999. If the hour is 24, the microsecond value is 000000.
The internal representation of a timestamp is a string of 10 bytes
in packed decimal notation. Each byte consists of two decimal digits. The first 4 bytes represent the date, the next 3 bytes the time, and the last 3 bytes the microseconds.
The length of a TIMESTAMP column as described in the catalog is 10 bytes, representing the internal length. The length of a TIMESTAMP column as described in the SQLDA is 26 bytes.
Values whose data types are DATE, TIME, or TIMESTAMP are represented in an internal form that is transparent to the user of SQL. Dates, times, and timestamps, however, can also be represented by character strings. These representations directly concern the user of SQL because there are no constants or variables whose data types are DATE, TIME, or TIMESTAMP. Thus, to be retrieved, a datetime value must be assigned to a character string variable. The format of the resulting string will depend on how you defined datetime formats using the DATE and TIME preprocessor options, or how your site chose to represent datetime values at the time the database manager was installed.
When a valid string representation of a datetime value is used in an operation with an internal datetime value, the string representation is converted to the internal form of the date, time, or timestamp before the operation is performed. If the CCSID of the string is not the same as the default CCSID,
the string is first converted to the coded character set identified by the default CCSID before the string is converted to the internal form of the datetime value.
The following sections define the valid string representations of datetime values.
A string representation of a date is a character string that starts with a digit and has a length of at least 8 characters. An input string representation of a date or time value with LOCAL specified can be any short character string. Trailing blanks can be included. Leading zeros can be omitted from the month and day portions.
Valid string formats for dates are listed in Table 1. Each format is identified by name and includes an associated abbreviation (for use by the CHAR function) and an example of its use. For a site-defined date string format, the format and length must have been specified when the database manager was installed.
Table 1. Formats for String Representations of Dates
| Format Name | Abbreviation | Date Format | Example |
|---|---|---|---|
| International Organization for Standardization | ISO | yyyy-mm-dd | 1987-10-12 |
| IBM USA standard | USA | mm/dd/yyyy | 10/12/1987 |
| IBM European standard | EUR | dd.mm.yyyy | 12.10.1987 |
| Japanese industrial standard Christian era | JIS | yyyy-mm-dd | 1987-10-12 |
| Site-defined (see "Defining Your Own Datetime Format" in the DB2 Server for VM System Administration or DB2 Server for VSE System Administration manual) | LOCAL | Any site-defined form | -- |
A string representation of a time is a character string that starts with a digit and has a length of at least 4 characters. An input string representation of a date or time value with LOCAL specified can be any short character string. Trailing blanks can be included; a leading zero can be omitted from the hour part of the time and seconds can be omitted entirely. If you choose to omit seconds, an implicit specification of 0 seconds is assumed. Thus 13.30 is equivalent to 13.30.00.
Valid string formats for times are listed in Table 2. Each format is identified by name and includes an
associated abbreviation (for use by the CHAR function) and an example of its
use. In the case of a site-defined time string format, the format and
length must have been specified when the database manager was
installed.
Table 2. Formats for String Representations of Times
In the USA time format, the hour must not be greater than 12 and cannot be
0 except for the special case of 00:00 AM. Using the ISO format
of the 24-hour clock, the correspondence between the USA format and the
24-hour clock is as follows:
| USA Format | 24 Hour Clock |
|---|---|
| 12:01 AM through 12:59 AM | 00.01.00 through 00.59.00 |
| 01:00 AM through 11:59 AM | 01.00.00 through 11.59.00 |
| 12:00 PM (noon) through 11:59 PM | 12.00.00 through 23.59.00 |
| 12:00 AM (midnight) | 24.00.00 |
| 00:00 AM (midnight) | 00.00.00 |
A string representation of a timestamp is a character string that starts with a digit and has a length of at least 16 characters. The complete string representation of a timestamp has the form yyyy-xx-dd-hh.mm.ss.zzzzzz. Trailing blanks can be included. Leading zeros can be omitted from the month, day, and hour part of the timestamp, and trailing zeros can be truncated or omitted entirely from microseconds. If you choose to omit any digit of the microseconds portion, an implicit specification of 0 is assumed. Thus, 1990-3-2-8.30.00.10 is equivalent to 1990-03-02-08.30.00.100000.
Null is a special value used to represent "not applicable" or "undefined". For example:
Null is not the same as blank, an empty string, or zero. Columns can be defined to allow or disallow null values. In an application, a null value can be represented in a host variable by assigning a negative value to that host variable's associated indicator variable.
WHERE MGRNO IS NOT NULLOn the other hand, the predicate:
WHERE NOT MGRNO = :HV:INDwill never return any rows if IND has a negative value. In order to search for a null value among other values, the null value must be specified in a separate predicate. For example:
WHERE NOT MGRNO < 1000 OR MGRNO IS NULLRows for which MGRNO is null will not satisfy the predicate:
WHERE NOT MGRNO < 1000
Assignment operations are performed during the execution of FETCH, INSERT, PUT, SELECT INTO, and UPDATE statements. Comparison operations are performed during the execution of statements that include predicates and other language elements such as MAX, MIN, DISTINCT, GROUP BY, and ORDER BY.
The basic rule for both operations is that the data type of the operands
involved must be compatible. The compatibility rule also applies to
UNION, concatenation, and the VALUE scalar function. The compatibility
matrix is as follows:
| Operand | Binary Integer | Decimal Number | Floating Point | Character String | Graphic String | Date | Time | Time- stamp | ||
| Binary Integer | Yes | Yes | Yes | No | No | No | No | No | ||
| Decimal Number | Yes | Yes | Yes | No | No | No | No | No | ||
| Floating Point | Yes | Yes | Yes | No | No | No | No | No | ||
| Character String | No | No | No | Yes | No | * | * | * | ||
| Graphic String | No | No | No | No | Yes | No | No | No | ||
| Date | No | No | No | * | No | Yes | No | No | ||
| Time | No | No | No | * | No | No | Yes | No | ||
| Time- stamp | No | No | No | * | No | No | No | Yes | ||
| ||||||||||
A basic rule for assignment operations is that a null value cannot be assigned to a column that cannot contain null values, nor to a host variable that does not have an associated indicator variable. (See References to Host Variables for a discussion of indicator variables.)
The basic rule for numeric assignments is that the whole part of a decimal or integer number cannot be truncated. If necessary, the fractional part of a decimal number is truncated.
Floating-point numbers are approximations of real numbers. Hence, when a decimal or integer number is assigned to a floating-point column or variable, the result may not be identical to the original number.
Because of the added length of double precision floating-point numbers (64 bits rather than the 32 bits of a single precision value), the approximation is more accurate if the receiving column or variable is defined as double precision rather than single precision. Accuracy is lost if the precision of the target is less than that of the assigned value, as would be the case if a number greater than 16,777,216 were assigned to a single precision floating-point column.
When a floating-point or decimal number is assigned to an integer column or variable, the fractional part of the number is lost.
When a decimal number is assigned to a decimal column or variable, the number is converted, if necessary, to the precision and the scale of the target. The necessary number of leading zeros is appended or eliminated, and, in the fractional part of the number, the necessary number of trailing zeros is appended, or the necessary number of trailing digits is eliminated.
When an integer is assigned to a decimal column or variable, the number is converted first to a temporary decimal number and then, if necessary, to the precision and scale of the target. The precision and scale of the temporary decimal number is 5,0 for a small integer or 11,0 for a large integer.
When a single precision floating-point number is assigned to a double precision floating-point column or variable, the single precision data is padded with eight hex zeros.
When a double precision floating-point number is assigned to a single precision floating-point column or variable, the double precision data is converted and rounded up on the seventh hex digit.
When a single precision floating-point number is converted to decimal, the number is first converted to a temporary decimal number of precision 6 by rounding on the seventh decimal digit. Nine zeros are then appended to the number to bring the precision to 15. Because of the rounding involved, a number less than 0.5*10-6 is reduced to 0.
When a double precision floating-point number is converted to decimal, the number is first converted to a temporary decimal number of precision 15. Then, if necessary, the number is truncated to the precision and scale of the target. In this conversion, the number is rounded (using floating-point arithmetic) to a precision of 15 decimal digits. As a result, a number less than 0.5*10-15 is reduced to 0. The scale is given the largest possible value that allows the whole part of the number to be represented without loss of significance.
The floating-point number .123456789098765E-05
in decimal notation is: .00000123456789098765
+5
Rounding adds 5 ---------------------
in the 16th position .00000123456789148765
and truncates the result to: .000001234567891
Assignments to COBOL integer variables use the full size of the integer. Thus, the value placed in the COBOL data item may be out of the range of values.
In COBOL, for example, if COL1 contains a value of 12345, the COBOL statements:
01 A PIC S9999 BINARY.
EXEC SQL SELECT COL1
INTO :A
FROM TABLEX
END-EXEC.
result in the value 12345 being placed in A, even though A has been defined with only 4 digits.
Notice that the following COBOL statement:
MOVE 12345 TO A.
results in 2345 being placed in A.
The general rule for string assignments is that the length of a string assigned to a column must not be greater than the length attribute of the column. (Trailing blanks are included in the length of the string.)
Following are exceptions to this rule:
When a string is assigned to a fixed-length string column or host variable and the length of the string is less than the length attribute of the target, the string is padded on the right with the necessary number of blanks (SBCS blanks for character strings of all subtypes, DBCS blanks for graphic strings).
For example, the mixed value 'ab <(CC)>' padded to a length of 8 becomes 'ab<(CC)> '.
Bit data is padded with blanks, not with X'00''s.
When a string of length n is assigned to a varying-length string variable with a maximum length greater than n, the characters after the nth character of the variable are undefined and might or might not be set to blanks.
When a string is assigned to a variable and the string is longer than the length attribute of the variable, the string is truncated on the right by the necessary number of characters. When this occurs, the value 'W' is assigned to the SQLWARN1 field of the SQLCA. Furthermore, if an indicator variable is provided, it is set to the original length of the string.
The truncation rules for character strings are based on the subtype of the target. The rules are as follows:
CHAR(8) MIXED DATA:
the character string
'abc <(DDEE)>fg'
becomes
'abc <(DD)> '
If truncation is to occur on mixed character data but the data does not follow the proper rules regarding mixed data, then the data will be truncated as SBCS and SQLWARN1 will be set to 'Z'.
For a description of the SQLCA, see SQL Communication Area (SQLCA).
The above rules apply when both the source and the target are strings. When a datetime data type is involved, see Datetime Assignments.
A string assigned to a column or host variable is first converted, if necessary, to the coded character set of the target. Character conversion is necessary only if all of the following are true:
The database manager returns an error for any of the following conditions;
The database manager returns a warning for any of the following conditions:
A value assigned to a DATE column must be a date or a valid string representation of a date. A date can only be assigned to a DATE column, a character string column, or a character string variable. A value assigned to a TIME column must be a time or a valid string representation of a time. A time can only be assigned to a TIME column, a character string column, or a character string variable. A value assigned to a TIMESTAMP column must be a timestamp or a valid string representation of a timestamp. A timestamp can only be assigned to a TIMESTAMP column, a character string column, or a character string variable.
When a datetime value is assigned to a character string variable or column, it is converted to a string representation. Leading zeros are not omitted from any part of the date, time, or timestamp. The required length of the target varies depending on the format of the string representation. If the length of the target is greater than required, it is padded on the right with blanks. If the length of the target is less than required, the result depends on the type of datetime value involved, and on the type of target.
If the target is a column, truncation is not allowed. The length must be at least 10 for a date, 8 for a time, and 26 for a timestamp.
When the target is a host variable, the following rules for DATE, TIME, and TIMESTAMP apply:
For further information on string lengths for datetime values, see Datetime Values.
Numbers are compared algebraically; that is, with regard to sign. For example, -2 is less than +1.
If one number is an integer and the other number is decimal, the comparison is made with a temporary copy of the integer, which has been converted to decimal.
When decimal numbers with different scales are compared, the comparison is made with a temporary copy of one of the numbers that has been extended with trailing zeros so that its fractional part has the same number of digits as the other number.
If one number is floating-point and the other number is integer or decimal, the comparison is made with a temporary copy of the integer or decimal number, which has been converted to double precision floating-point. Similarly, if one number is single precision floating-point and one is double precision floating-point, the comparison is made with a temporary copy of the single precision floating-point number that has been converted to double precision.
Two floating-point numbers are equal only if the bit configurations of their normalized forms are identical.
Two strings are compared by comparing the corresponding bytes of each string. If the strings do not have the same length, the comparison is made with a temporary copy of the shorter string that has been padded on the right with blanks so that it has the same length as the other string. All character subtypes use an SBCS blank character for padding. However, when a comparison other than simple equals or not equals occurs between two varying-length string values, the pad character is X'00'.
| Note: | The only place where this will make a difference is when a value being compared contains non-printable characters, that is, characters whose code point is less than X'40'. Examples of places where X'00' is used are: the greater than predicate, sorting in response to an ORDER BY clause, and retrieving ordered data using an index. |
Two strings are equal if they are both empty or if all corresponding bytes are equal. An empty string is equal to a blank string. If two strings are not equal, their relationship is determined by the comparison of the first pair of unequal bytes from the left end of the strings. This comparison is made according to the EBCDIC collating sequence of the CCSID under which they are compared. If a field procedure is defined on a column, the comparison will be made according to the EBCDIC collating sequence of the value encoded by the field procedure, if the encoded value is a string.
When two strings are compared, one of the strings is first converted, if necessary, to the coded character set of the other string. Character conversion is necessary only if all of the following are true:
If one string has an SBCS CCSID and the other has a mixed CCSID, the SBCS
string is converted. Otherwise, the string selected for conversion
depends on the type of each operand. The following table shows which
operand is selected for conversion, given the operand types.
Table 4. Selecting the Operand for Character Conversion
| First Operand | Second Operand | ||||
|---|---|---|---|---|---|
| Column Value | Derived Value | Constant | Special Register | Host Variable | |
| Column Value | second | second | second | second | second |
| Derived Value | first | second | second | second | second |
| Constant | first | first | second | second | second |
| Special Register | first | first | second | second | second |
| Host Variable | first | first | first | first | second |
A host variable containing data in a foreign encoding scheme is always converted to the native form of data before it is used in any operation. The above rules are based on the assumption that this conversion has already occurred.
An error occurs if a character of the string cannot be converted or the CCSID Conversion Selection Table is used but does not contain any information about the pair of CCSIDs. A warning occurs if a character of the string is converted to the substitution character.
A DATE, TIME, or TIMESTAMP value can be compared either with another value of the same data type or with a string representation of that data type. All comparisons are chronological, which means the farther a point in time is from January 1, 0001, the greater the value of that point in time.
Comparisons involving TIME values and string representations of time values always include seconds. If the string representation omits seconds, zero seconds are implied. Therefore the following predicate is true:
TIME('03.42.00') = '03.42'
Note: TIME('00.00.00') does not compare as an equal to TIME('24.00.00').
Comparisons involving TIMESTAMP values are chronological without regard to representations that might be considered equivalent. Thus, the following predicate is true:
TIMESTAMP('1990-02-23-00.00.00')>'1990-02-22-24.00.00'
In comparisons of DATE and TIME, two strings which are not identical are considered to be equal if they represent the same date (that is, '1991-1-1' = '1991-01-01').
A constant (also called a literal) specifies a value. Constants are classified as string constants or numeric constants. Numeric constants are further classified as integer, floating-point, or decimal. String constants are further classified as character or graphic.
All constants have the attribute NOT NULL. A negative sign in a numeric constant with a value of zero is ignored.
An integer constant specifies an integer as a signed or unsigned number with a maximum of 10 digits that does not include a decimal point. The data type of an integer constant is large integer, and its value must be within the range of a large integer.
Examples: 64 -15 +100 32767 720176
In syntax diagrams the term integer is used for an integer constant that must not include a sign.
A floating-point constant specifies a floating-point number as two numbers separated by an E. The first number can include a sign and a decimal point; the second number can include a sign but not a decimal point. The value of the constant is the product of the first number and the power of 10 specified by the second number; it must be within the range of floating-point numbers. The number of characters in the constant must not exceed 30. Excluding leading zeros, the number of digits in the first number must not exceed 17 and the number of digits in the second must not exceed 2. The data type of a floating-point constant is double precision floating-point.
Examples: 15E1 2.E5 2.2E-1 +5.E+2
A decimal constant specifies a decimal number as a signed or unsigned number that includes a decimal point and at most 31 digits. The precision is the total number of digits (including leading and trailing zeros). When precision is greater than 31, and a precision of 31 is possible by eliminating leading zeros, then those zeros are eliminated.
Examples: 25.5 1000. -15. +37589.3333333333
A character string constant specifies a varying-length character string. There are two forms of character string constant:
Examples: 'Peggy' '14.12.1985' '32' 'DON''T CHANGE' ''
Hexadecimal constants, as character string constants, are converted from the CCSID of the application requester to the CCSID of the application server as part of the CCSID conversion of statements. One example of where this may give unexpected results is the following situation. Consider the case of an application requester which uses CCSID=851 (an ASCII CCSID) and a DB2 Server for VSE & VM application server which uses CCSID=500 (an EBCDIC CCSID). The table T1 has a character column defined as FOR BIT DATA. The statement
INSERT INTO T1 VALUES (X'41')
will insert the hexadecimal value X'C1' into the column, because CCSID conversion of the statement happens before the statement is interpreted (note that for CCSID=851, 'A' = X'41' and for CCSID=500, 'A' = X'C1'). To have no conversion occur and have the value X'41' inserted into the column, use a host variable instead of the constant.
Examples: X'FFFF' X'535164A1' X'C5C2C3C4C9C3' X'4153434949'
The subtype is classified as mixed data if it includes a DBCS substring (that is, it contains properly matched shift control characters) and the application server and application requester both support DBCS characters (that is, the CHARNAME is a mixed CHARNAME). In all other cases, a character string constant is classified as SBCS data. For example, X'0E42C142C2' would be interpreted as SBCS data because it contains improperly matched shift control characters.
Examples of mixed character string constants:
'abc<(XXYYZZ)>' '<(XXYYZZ)>' 'a<(XXYYZZ)>b' '<(XX)>ab<(YYZZ)>cd'
Character constants of the bit subtype cannot be defined.
The CCSID assigned to a constant is the appropriate default CCSID of the application server at bind time. Since a character string constant is always part of a statement, it is converted with the statement from the default CCSID of the application requester to the default CCSID of the application server. For example, an ASCII constant might get converted to an EBCDIC representation. A special case is the above example where a hexadecimal constant which is first converted to its character representation before it is converted from the default CCSID of the application requester to the default CCSID of the application server.
A graphic string constant is a short, varying-length string that specifies a graphic string. There are three forms of graphic string constant, two for static SQL statements in PL/I and one for all other contexts. In the following description of these three forms, the string of characters ((XXYYZZ)) is the actual string, consisting of 0 to 127 double-byte characters. The character G (N may be used as a synonym for G) and the string delimiter (here represented by the apostrophe [']) are required in the positions indicated.
The forms of graphic string constants are:
In the first form, ('), is the double-byte string delimiter X'427D' and, in this case, (GG) is the double-byte character X'42C7'. To use that character within the double-byte character sequence, it must be doubled.
See PREPARE for more information on the use of DBCS constants in prepared statements in PL/I Version 2 programs.
Here, ' is the EBCDIC string delimiter, X'7D'. With this form of graphic string constant, the empty string can be denoted by G'<>'. G must be the single-byte character G.
The CCSID assigned to a constant is the appropriate default CCSID of the application server at bind time, assuming that the application server and application requester support DBCS characters (that is, the CHARNAME is a mixed CHARNAME). Since a graphic string constant is always part of a statement, it is converted with the statement from the default CCSID of the application requester to the default CCSID of the application server.
Graphic string constants are only supported in COBOL, PL/I, and REXX.
A special register is a storage area that is defined for an application process by the database manager and stores information that can be referenced in SQL statements. A reference to a special register is a reference to a value provided by the application server. If the value is a string, its CCSID is a default CCSID (based on the default subtype value, CHARSUB) of the application server.
The USER special register specifies a CHAR(8) value that identifies the run-time authorization ID.
The authorization ID is padded on the right with blanks, if necessary, so that the value of USER is always a fixed-length character string of length 8.
Select all notes from the IN_TRAY sample table that the user placed there.
SELECT * FROM IN_TRAY
WHERE SOURCE = USER
The CURRENT DATE special register
specifies a date that is based on a reading of the time-of-day clock when the SQL statement is processed at the application server. The data type is DATE. If this special register is used more than once within a single SQL statement, or used with CURRENT TIME or CURRENT TIMESTAMP within a single statement, all values are based on a single clock reading.
Using the PROJECT table, set the project end date (PRENDATE) of the MA2111 project (PROJNO) to the current date.
UPDATE PROJECT
SET PRENDATE = CURRENT DATE
WHERE PROJNO = 'MA2111'
The CURRENT SERVER special register specifies a CHAR(18) value that identifies the current application server.
The server-name ID is padded on the right with blanks, if necessary, so that the value of CURRENT SERVER is always a fixed-length character string of length 18.
The CURRENT SERVER can be changed by the CONNECT statement.
Set the host variable APPL_SERVE (varchar(18)) to the name of the application server to which the application is connected.
SELECT CURRENT SERVER
INTO :APPL_SERVE
FROM ONE_ROW_TABLE
The CURRENT TIME special register
specifies a time that is based on a reading of the time-of-day clock when the SQL statement is processed at the application server. The data type is TIME. If this special register is used more than once within a single SQL statement, or used with CURRENT DATE or CURRENT TIMESTAMP within a single statement, all values are based on a single clock reading.
The CURRENT TIMESTAMP special register
specifies a timestamp that is based on a reading of the time-of-day clock when the SQL statement is processed at the application server. The data type is TIMESTAMP. If this special register is used more than once within a single SQL statement, or used with CURRENT DATE or CURRENT TIME within a single statement, all values are based on a single clock reading.
The CURRENT TIMEZONE special register
specifies the difference between UTC (Universal Coordinated Time, formerly known as GMT) and local time at the application server. The data type is DECIMAL(6,0). The difference is represented by a time duration (a decimal number in which the first two digits are the number of hours, the next two digits are the number of minutes, and the last two digits are the number of seconds). The number of hours is between -24 and 24 exclusive. Subtracting CURRENT TIMEZONE from a local time converts that local time to UTC.
Using the IN_TRAY table select all the rows from the table and adjust the value from the RECEIVED column to account for timezone.
SELECT RECEIVED - CURRENT TIMEZONE, SOURCE,
SUBJECT, NOTE_TEXT FROM IN_TRAY
The meaning of a column name depends on its context. A column name can be used to:
A qualifier for a column name can be a table name, a view name, a synonym, or a correlation name.
Whether a column name can be qualified depends on its context:
Where a qualifier is optional it can serve two purposes. See Column Name Qualifiers to Avoid Ambiguity and Column Name Qualifiers in Correlated References for details.
A correlation name can be defined in the FROM clause of a query and in the first clause of an UPDATE or DELETE statement. For example, the clause shown below establishes Z as a correlation name for X.MYTABLE.
FROM X.MYTABLE Z
A correlation name is associated with a table or view only within the context in which it is defined. Hence, the same correlation name can be defined for different purposes in different statements, or in different clauses of the same statement.
As a qualifier, a correlation name can be used to avoid ambiguity or to establish a correlated reference. It can also be used merely as a shorter name for a table or view. In the example, Z might have been used merely to avoid having to enter X.MYTABLE more than once.
If a correlation name is specified for a table name or view name, any qualified reference to a column of that instance of the table or view must use the correlation name, rather than the table name or view name. For example, the reference to EMPLOYEE.PROJECT in the following example is incorrect, because a correlation name has been specified for EMPLOYEE:
.-----------.
FROM EMPLOYEE E | INCORRECT |
WHERE EMPLOYEE.PROJECT='ABC' '-----------'
The qualified reference to PROJECT should instead use the correlation name, 'E', as shown below:
FROM EMPLOYEE E
WHERE E.PROJECT='ABC'
Names specified in a FROM clause are either exposed or non-exposed. A correlation name is always an exposed name. All exposed names in the FROM clause must be unique. A table name, view name, or synonym is said to be exposed in that FROM clause if a correlation name is not specified. For example, in the following FROM clause, a correlation name is specified for EMPLOYEE but not for DEPARTMENT, so DEPARTMENT is an exposed name, and EMPLOYEE is not:
FROM EMPLOYEE E, DEPARTMENT
The names are compared after qualifying any unqualified table or view names.
The first two FROM clauses shown below are correct, because each one contains no more than one reference to EMPLOYEE that is exposed:
FROM EMPLOYEE E1, EMPLOYEE
a qualified reference such as EMPLOYEE.PROJECT denotes a column of the second instance of EMPLOYEE in the FROM clause. A qualified reference to the first instance of EMPLOYEE must use the correlation name "E1" (E1.PROJECT).
FROM EMPLOYEE, EMPLOYEE E2
a qualified reference such as EMPLOYEE.PROJECT denotes a column of the first instance of EMPLOYEE in the FROM clause. A qualified reference to the second instance of EMPLOYEE must use the correlation name "E2" (E2.PROJECT).
.------------.
FROM EMPLOYEE, EMPLOYEE | INCORRECT |
'------------'
a reference to either the first or second instance of EMPLOYEE will be incorrect as neither is uniquely identified.
SELECT * .-----------.
FROM EMPLOYEE E1, EMPLOYEE E2 | INCORRECT |
WHERE EMPLOYEE.PROJECT = 'ABC' '-----------'
the qualified reference EMPLOYEE.PROJECT is incorrect, because both instances of EMPLOYEE in the FROM clause have correlation names. Instead, references to PROJECT must be qualified with either correlation name (E1.PROJECT or E2.PROJECT).
FROM EMPLOYEE, X.EMPLOYEE
a reference to a column in the second instance of EMPLOYEE must use X.EMPLOYEE (X.EMPLOYEE.PROJECT). This FROM clause is only valid if the authorization ID of the statement is not X.
A correlation name specified in a FROM clause must not be the same as:
For example, the following FROM clauses are incorrect:
FROM EMPLOYEE E, EMPLOYEE E .-----------. FROM EMPLOYEE DEPARTMENT, DEPARTMENT | INCORRECT | FROM X.T1, EMPLOYEE T1 '-----------'
The following FROM clause is technically correct, though potentially confusing:
FROM EMPLOYEE DEPARTMENT, DEPARTMENT EMPLOYEE
In the context of a function, a GROUP BY clause, ORDER BY clause, an expression, or a search condition, a column name refers to values of a column in some table or view. The tables and views that might contain the column are called the object tables of the context. Two or more object tables might contain columns with the same name. One reason for qualifying a column name is to designate the table from which the column comes.
A qualifier that designates a specific object table is called a table designator. The clause that identifies the object tables also establishes the table designators for them. For example, the object tables of an expression in a SELECT clause are named in the FROM clause that follows it, as in this statement:
SELECT CORZ.COLA, OWNY.MYTABLE.COLA
FROM OWNX.MYTABLE CORZ, OWNY.MYTABLE
This example illustrates how to establish table designators in the FROM clause:
When a column name refers to values of a column, exactly one object table must include a column with that name. The following situations are considered errors:
Avoid ambiguous references by qualifying a column name with a uniquely defined table designator. If the column is contained in several object tables with different names, the table names can be used as designators.
When qualifying a column with the exposed table name form of a table designator, either the qualified or unqualified form of the exposed table name may be used. However, the qualifier used and the table used must be the same after fully qualifying the table name or view name and the table designator.
SELECT CORPDATA.EMPLOYEE.WORKDEPT
FROM EMPLOYEE
is a valid statement.
SELECT CORPDATA.EMPLOYEE.WORKDEPT .-----------.
FROM EMPLOYEE | INCORRECT |
'-----------'
is incorrect, because EMPLOYEE represents the table REGION.EMPLOYEE, but the qualifier for WORKDEPT represents a different table, CORPDATA.EMPLOYEE.
A subselect is a form of a query that can be used as a component of various SQL statements. Refer to Chapter 5, Queries for more information on subselects. A subselect used within a search condition of any statement is called a subquery.
A subquery can include search conditions of its own, and these search conditions can, in turn, include subqueries. Thus an SQL statement can contain a hierarchy of subqueries. Those elements of the hierarchy that contain subqueries are said to be at a higher level than the subqueries they contain.
Every element of the hierarchy has a clause that establishes one or more table designators. This is the FROM clause, except in the highest level of an UPDATE or DELETE statement. A search condition of a subquery can reference not only columns of the tables identified by the FROM clause of its own element of the hierarchy, but also columns of tables identified at any level along the path from its own element to the highest level of the hierarchy. A reference to a column of a table identified at a higher level is called a correlated reference.
A correlated reference to column C of table T can be of the form C, T.C, or Q.C, if Q is a correlation name defined for T. However, a correlated reference in the form of an unqualified column name is not good practice. The following explanation is based on the assumption that a correlated reference is always in the form of a qualified column name and that the qualifier is a correlation name.
A qualified column name, Q.C, is a correlated reference only if these three conditions are met:
Q.C refers to column C of the table or view at the level where Q is used as the table designator of that table or view. Because the same table or view can be identified at many levels, unique correlation names are recommended as table designators. If Q designates a table at more than one level, Q.C refers to the lowest level that contains the subquery that includes Q.C.
In the following statement, Q is used as a correlation name for T1 and T2, but Q.C refers to the correlation name associated with T2, because it is the lowest level that contains the subquery that includes Q.C.
SELECT *
FROM T1 Q
WHERE A < ALL (SELECT B
FROM T2 Q
WHERE B < ANY (SELECT D
FROM T3
WHERE D = Q.C))
A host variable is an Assembler language storage area, C variable, COBOL data item, FORTRAN variable, PL/I variable, or a REXX variable that is referenced in an SQL statement. Host variables are defined by statements of the host language (that is, they are given a name and a data type), as described in the DB2 Server for VSE & VM Application Programming manual. Note that host variables cannot be referenced in dynamic SQL statements; instead, parameter markers must be used (see Parameter markers).
All host variables used in an SQL statement must be declared in an SQL declare section in all host languages other than REXX, where variables do not have to be declared. No variables may be declared outside an SQL declare section with names identical to variables declared inside an SQL declare section. An SQL declare section begins with BEGIN DECLARE SECTION and ends with END DECLARE SECTION.
The metavariable host_variable, as used in the syntax diagrams, is a reference to a host language variable (the main variable) and an optional associated host language variable (the indicator variable). A host_variable in the INTO clause of a FETCH or a SELECT INTO statement is an output variable to which a value is assigned by the database manager. In all other contexts a host_variable is an input variable which provides a value to the database manager.
The general form of a host_variable reference is:
>>-:host_identifier---+----------------------------------+-----><
| .-INDICATOR-. |
'-+-----------+--:host_identifier--'
The first host_identifier designates the main variable. Depending on the operation, it either furnishes a value to the database manager, or is furnished one. An input variable furnishes a value; an output variable is furnished one. For example, an input variable can specify a comparand in a WHERE clause or a replacement for a column value in an UPDATE statement. An output variable can receive a column value when a row is fetched from a table. A given host_variable can serve as both an input and an output variable in the same program.
The second host_identifier designates the associated indicator variable and it must be defined as a half-word integer (corresponding to the data type SMALLINT). The indicator variable does one of the following:
Indicator variables, including indicator variables in predicates, can be used to identify null values on input to the database manager (UPDATE, INSERT, or PUT statements or predicates of SELECT, DELETE and UPDATE), or on output from the database manager (INTO clause of SELECT and FETCH statements).
If the second host_identifier is omitted, the host_variable does not have an indicator variable. The value specified by the host_variable reference :V1 is always the value of V1, and the null value cannot be assigned to the variable. It is always good practice to include an output indicator variable. Thus, this form should not be used in an INTO clause unless the corresponding result column cannot contain null values. If this form is used and the column contains nulls, the database manager will return an error at run-time.
An SQL statement that references host variables must be within the scope of the declaration of those host variables. For host variables referenced in the SELECT statement of a cursor, that rule applies to the OPEN statement rather than to the DECLARE CURSOR statement.
For more information on host variables, see the DB2 Server for VSE & VM Application Programming manual.
Example:
Using the PROJECT table:
Columns PRSTAFF and MAJPROJ may contain null values, so provide indicator variables STAFF_IND (smallint) and MAJPROJ_IND (smallint).
SELECT PROJNAME, PRSTAFF, MAJPROJ
INTO :PNAME, :STAFF :STAFF_IND, :MAJPROJ :MAJPROJ_IND
FROM PROJECT
WHERE PROJNO = 'IF1000'
Host structures and indicator arrays can be defined in C, COBOL, and PL/I. Host structures are defined by statements of the host language, as explained in the DB2 Server for VSE & VM Application Programming manual. As used here, the term "host structure" does not include an SQLCA or SQLDA.
The form of a host structure reference is identical to the form of a host_variable reference. The reference :S1:I1 is a host structure reference if S1 names a host structure. I1 must be defined as either an indicator variable or a one-dimensional array of half-word integer variables . S1 is the main structure and I1 is its indicator variable or indicator array.
In the discussion that follows, let S1 be a structure defined with variables V1, V2, and V3. Let I1 be a one-dimensional array of three half-word integers. Each Vn is a subfield of S1 as follows:
S1
V1
V2
V3
I1(3)
A host structure can be used in any context where a host_variable_list can be referenced. A host structure reference is equivalent to a reference to each of the subfields contained within the structure in the order which they are defined in the host language structure declaration. The nth variable of the indicator array is the indicator variable for the nth subfield of the main structure.
Host structures and variable arrays used as indicator arrays must also be declared in an SQL declare section, the same as host_variables.
In PL/I, for example, the statement:
EXEC SQL FETCH CURSOR1 INTO :S1;
is equivalent to:
EXEC SQL FETCH CURSOR1 INTO :V1, :V2, :V3;
If the main structure has m more subfields than the indicator array, the last m subfields of the main structure do not have associated indicator variables. If the main structure has m less subfields than the indicator array, the last m variables of the indicator array are ignored. If an indicator variable (rather than an indicator array) is specified, only the first subfield of the main structure has an indicator variable. If an indicator array is not specified for a host structure, no subfield of the main structure has an indicator variable.
The following restrictions apply to the use of a host structure in place of a list of host_variables. (For language specific information and examples, please refer to the DB2 Server for VSE & VM Application Programming manual.)
For example, the statement:
EXEC SQL FETCH CURSOR2 INTO :V2:I1;
will result in the first element of I1 receiving the indicator value. The second and third elements of I1 are not affected by this statement.
A subfield of a structure, including structures which are not valid as host structures, may also be used as a host variable. The only requirement is that the structure must be declared within an SQL declare section.
See Examples for additional coding examples.
An expression specifies a value.
.-| operator |--------------------------------.
V (1) |
>>----+-----+---+-function-------------+---------+-------------><
+- + -+ +-(expression)---------+
'- - -' +-constant-------------+
+-column_name----------+
+-host_variable--------+
+-special_register-----+
'-| labeled_duration |-'
operator
(2)
|---+-CONCAT------+---------------------------------------------|
+- / ---------+
+- * ---------+
+- + ---------+
'- - ---------'
labeled_duration
|---+-function------+---+-YEAR---------+------------------------|
+-(expression)--+ +-YEARS--------+
+-constant------+ +-MONTH--------+
+-column_name---+ +-MONTHS-------+
'-host_variable-' +-DAY----------+
+-DAYS---------+
+-HOUR---------+
+-HOURS--------+
+-MINUTE-------+
+-MINUTES------+
+-SECOND-------+
+-SECONDS------+
+-MICROSECOND--+
'-MICROSECONDS-'
Notes:
|
If no operators are used, the result of the expression is the specified value.
Examples:
SALARY :SALARY 'SALARY' MAX(SALARY)
The concatenation operator (CONCAT) links two string operands to form a string expression.
The operands of concatenation must be compatible strings. Note that datetime data types (including the CURRENT DATE, CURRENT TIME, and CURRENT TIMESTAMP special registers) can be used as operands in a character string expression because the datetime data types are compatible with the character data type. If both operands are character strings, the sum of their length attributes must not exceed 254; if both are graphic strings, the sum of their length attributes must not exceed 127.
If either operand can be null, the result can be null, and if either is null, the result is the null value. Otherwise, the result consists of the first operand string followed by the second.
With mixed data this result will not have redundant shift codes "at the seam". Thus, if the first operand is a string ending with a "shift-in" character, while the second operand is a character string beginning with a "shift-out" character, these two bytes are eliminated from the result. Note that no check is made for improperly formed mixed data when doing concatenation.
The length of the result is the sum of the lengths of the operands, unless redundant shift codes are eliminated, in which case the length is two less than the lengths of the operands.
If both operands are fixed-length character strings (neither of which is mixed data) the result is a fixed-length character string whose length attribute is the sum of the length of the operands. Otherwise, the result is a varying-length character string whose length attribute is the sum of the length attributes of the operands.
If both operands are fixed-length graphic strings, the result is a fixed-length graphic string whose length attribute is the sum of the length of the operands. Otherwise, the result is a varying-length graphic string whose length attribute is the sum of the length attributes of the operands.
The CCSID of the result is determined by the CCSID of the operands as explained under Conversion Rules for Operations that Combine Strings.
If an operand is a string from a column with a field procedure, the operation applies to the decoded form of the value; the result does not inherit the field procedure.
Example 1: FIRSTNME CONCAT ' ' CONCAT LASTNAME
Example 2: Given:
The value of COLA CONCAT COLB CONCAT COLC CONCAT COLD is:
'AABB CC DDDDD'
Arithmetic operators (+, -, *, /) link two numeric or datetime operands to form a numeric expression.
If arithmetic operators are used, the result of the expression is a number derived from the application of the operators to the values of the operands. If any operand can be null, or the expression is used in an outer SELECT list, the result can be null. If any operand has the null value, the result of the expression is the null value. Arithmetic operators must not be applied to character strings. For example, USER+2 is incorrect.
The prefix operator + (unary plus) does not change its operand. The prefix operator - (unary minus) reverses the sign of a nonzero operand. If the data type of A is small integer, the data type of -A is large integer. If the data type of A is small float, then the data type of -A is large float. The first character of the token following a prefix operator must not be a plus or minus sign.
The infix operators +, -, *, and / specify addition, subtraction, multiplication, and division, respectively. Either an error or a warning results if the second operand of division has a value of zero.
If both operands of an arithmetic operator are integers, the operation is performed in binary and the result is a large integer. Any remainder of division is lost. The result of an integer arithmetic operation (including unary minus) must be within the range of large integers.
If one operand is an integer and the other is decimal, the operation is performed in decimal using a temporary copy of the integer that has been converted to a decimal number with zero scale and precision as defined in the following table:
| Operand | Precision of Decimal Copy |
|---|---|
| Column or variable:large integer | 11 |
| Column or variable:small integer | 5 |
| Constant | Same as the number of digits (including leading zeros) in the constant |
If both operands are decimal, the operation is performed in decimal. The result of any decimal arithmetic operation is a decimal number with a precision and scale that are dependent on the operation and the precision and scale of the operands. If the operation is addition or subtraction and the operands do not have the same scale, the operation is performed with a temporary copy of one of the operands that has been extended with trailing zeros so that its fractional part has the same number of digits as the other operand.
Unless specified otherwise, all functions and operations that accept decimal numbers allow a precision of up to 31 digits.
The result of a decimal operation cannot have a precision greater than 31.
The following formulas define the precision and scale of the result of decimal operations in SQL. The symbols p and s denote the precision and scale of the first operand and the symbols p' and s' denote the precision and scale of the second operand.
The precision of the result of addition and subtraction is min(31, max(p-s, p'-s')+max(s, s')+1) and the scale is max(s, s').
The precision of the result of multiplication is min(31, p+p') and the scale is min(31, s+s').
The precision of the result of division is 31 and the scale is 31-p+s-s'.
If the scale is negative, a negative value is returned in the SQLCODE field of the SQLCA. Precision and scale can be influenced by decimal constants with leading or trailing zeros.
If either operand of an arithmetic operator is floating-point,
the operation is performed in floating-point. If necessary, the operands are first converted to double precision floating-point numbers. Thus, if any element of an expression is a floating-point number, the result of the expression is a double precision floating-point number.
An operation involving a floating-point number and an integer is performed with a temporary copy of the integer that has been converted to double precision floating-point. An operation involving a floating-point number and a decimal number is performed with a temporary copy of the decimal number that has been converted to double precision floating-point. The result of a floating-point operation must be within the range of floating-point numbers.
Datetime values can be incremented, decremented, and subtracted. These operations may involve decimal numbers called durations. Following is a definition of durations and a specification of the rules for datetime arithmetic.
A duration is a number representing an interval of time. There are four types of durations:
The only arithmetic operations that can be performed on datetime values are addition and subtraction. If a datetime value is the operand of addition, the other operand must be a duration. The specific rules governing the use of the addition operator with datetime values follow.
The rules for the use of the subtraction operator on datetime values are not the same as those for addition because a datetime value cannot be subtracted from a duration, and because the operation of subtracting two datetime values is not the same as the operation of subtracting a duration from a datetime value. The specific rules governing the use of the subtraction operator with datetime values follow.
Dates can be subtracted, incremented, or decremented.
The result of subtracting one date (DATE2) from another (DATE1) is a date duration that specifies the number of years, months, and days between the two dates. The data type of the result is DECIMAL(8,0). If DATE1 is greater than or equal to DATE2, DATE2 is subtracted from DATE1. If DATE1 is less than DATE2, however, DATE1 is subtracted from DATE2, and the sign of the result is made negative. The following procedural description clarifies the steps involved in the operation RESULT = DATE1 - DATE2.
If DAY(DATE2) <= DAY(DATE1)
then DAY(RESULT) = DAY(DATE1) - DAY(DATE2).
If DAY(DATE2) > DAY(DATE1)
then DAY(RESULT) = N + DAY(DATE1) - DAY(DATE2)
where N = the last day of MONTH(DATE2).
MONTH(DATE2) is then incremented by 1.
If MONTH(DATE2) <= MONTH(DATE1)
then MONTH(RESULT) = MONTH(DATE1) - MONTH(DATE2).
If MONTH(DATE2) > MONTH(DATE1)
then MONTH(RESULT) = 12 + MONTH(DATE1) - MONTH(DATE2).
YEAR(DATE2) is then incremented by 1.
YEAR(RESULT) = YEAR(DATE1) - YEAR(DATE2).
For example, the result of DATE('3/15/2000') - '12/31/1999' is 215 (or, a duration of 0 years, 2 months, and 15 days).
The result of adding a duration to a date, or of subtracting a duration from a date, is itself a date. The result must fall between the dates January 1, 0001 and December 31, 9999 inclusive. If a duration of years is added or subtracted, only the year portion of the date is affected. The month is unchanged, as is the day unless the result would be February 29 of a non-leap-year. Here the day portion of the result is set to 28, and the SQLWARN7 condition is set, indicating that an end-of-month adjustment was made to correct an incorrect date.
Similarly, if a duration of months is added or subtracted, only months and, if necessary, years are affected. (For the purposes of the operation, a month is a calendar page. Adding n months to a date, for example, is like turning n pages of a calendar starting with the page on which the date appears.) The day portion of the date is unchanged unless the result would be incorrect (September 31, for example). Here, the day is set to the last day of the month, and the SQLWARN7 field in SQLCA is set indicating the adjustment.
Adding or subtracting a duration of days will, of course, affect the day portion of the date, and potentially the month and year.
Date durations, whether positive or negative, may also be added to and subtracted from dates. As with labeled durations, the result is a valid date and SQLWARN7 is set whenever an end-of-month adjustment is necessary.
When a positive date duration is added to a date, or a negative date duration is subtracted from a date, the date is incremented by the specified number of years, months, and days, in that order. Thus, DATE1 + X, where X is a positive DECIMAL(8,0) number, is equivalent to the expression DATE1 + YEAR(X) YEARS + MONTH(X) MONTHS + DAY(X) DAYS.
When a positive date duration is subtracted from a date, or a negative date duration is added to a date, the date is decremented by the specified number of days, months, and years in that order. Thus, DATE1 - X, where X is a positive DECIMAL(8,0) number, is equivalent to the expression DATE1 - DAY(X) DAYS - MONTH(X) MONTHS - YEAR(X) YEARS.
When adding durations to dates, adding one month to a given date gives the same date one month later unless that date does not exist in the later month. In that case, the date is set to that of the last day of the later month. For example, January 28 plus one month gives February 28; and one month added to January 29, 30, or 31 results in either February 28 or, for a leap year, February 29.
| Note: | If one or more months is added to a given date and then the same number of months is subtracted from the result, the final date is not necessarily the same as the original date. |
Times can be subtracted, incremented, or decremented.
The result of subtracting one time (TIME2) from another (TIME1) is a time duration that specifies the number of hours, minutes, and seconds between the two times. The data type of the result is DECIMAL(6,0). If TIME1 is greater than or equal to TIME2, TIME2 is subtracted from TIME1. If TIME1 is less than TIME2, however, TIME1 is subtracted from TIME2, and the sign of the result is made negative. The following procedural description clarifies the steps involved in the operation RESULT = TIME1 - TIME2.
If SECOND(TIME2) <= SECOND(TIME1)
then SECOND(RESULT) = SECOND(TIME1) - SECOND(TIME2).
If SECOND(TIME2) > SECOND(TIME1)
then SECOND(RESULT) = 60 + SECOND(TIME1) - SECOND(TIME2).
MINUTE(TIME2) is then incremented by 1.
If MINUTE(TIME2) <= MINUTE(TIME1)
then MINUTE(RESULT) = MINUTE(TIME1) - MINUTE(TIME2).
If MINUTE(TIME2) > MINUTE(TIME1)
then MINUTE(RESULT) = 60 + MINUTE(TIME1) - MINUTE(TIME2).
HOUR(TIME2) is then incremented by 1.
HOUR(RESULT) = HOUR(TIME1) - HOUR(TIME2).
For example, the result of TIME('11:02:26') - '00:32:56' is 102930 (a duration of 10 hours, 29 minutes, and 30 seconds).
The result of adding a duration to a time, or of subtracting a duration from a time, is itself a time. Any overflow or underflow of hours is discarded, thereby ensuring that the result is always a time. If a duration of hours is added or subtracted, only the hours portion of the time is affected. The minutes and seconds are unchanged.
Similarly, if a duration of minutes is added or subtracted, only minutes and, if necessary, hours are affected. The seconds portion of the time is unchanged.
Adding or subtracting a duration of seconds will, of course, affect the seconds portion of the time, and potentially the minutes and hours.
Time durations, whether positive or negative, also can be added to and subtracted from times. The result is a time that has been incremented or decremented by the specified number of hours, minutes, and seconds, in that order.
For example, TIME1 + X, where X is a DECIMAL(6,0) number, is equivalent to the expression
TIME1 + HOUR(X) HOURS + MINUTE(X) MINUTES + SECONDS(X) SECONDS
Timestamps can be subtracted, incremented, or decremented.
The result of subtracting one timestamp (TS2) from another (TS1) is a timestamp duration that specifies the number of years, months, days, hours, minutes, seconds, and microseconds between the two timestamps. The data type of the result is DECIMAL(20,6). If TS1 is greater than or equal to TS2, TS2 is subtracted from TS1. If TS1 is less than TS2, however, TS1 is subtracted from TS2 and the sign of the result is made negative. The following procedural description clarifies the steps involved in the operation RESULT = TS1 - TS2.
If MICROSECOND(TS2) <= MICROSECOND(TS1) then
MICROSECOND(RESULT) = MICROSECOND(TS1) -
MICROSECOND(TS2).
If MICROSECOND(TS2) > MICROSECOND(TS1)
then MICROSECOND(RESULT) = 1000000 +
MICROSECOND(TS1) - MICROSECOND(TS2),
and SECOND(TS2) is incremented by 1.
The seconds and minutes part of the timestamps are subtracted as specified in the rules for subtracting times.
If HOUR(TS2) <= HOUR(TS1)
then HOUR(RESULT) = HOUR(TS1) - HOUR(TS2).
If HOUR(TS2) > HOUR(TS1)
then HOUR(RESULT) = 24 + HOUR(TS1) - HOUR(TS2)
and DAY(TS2) is incremented by 1.
The date part of the timestamps is subtracted as specified in the rules for subtracting dates.
The result of adding a duration to a timestamp, or of subtracting a duration from a timestamp, is itself a timestamp. Date and time arithmetic is performed as previously defined, except that an overflow or underflow of hours is carried into the date part of the result, which must be within the range of valid dates. Microseconds overflow into seconds.
Expressions within parentheses are evaluated first. When the order of evaluation is not specified by parentheses, prefix operators are applied before multiplication and division, and multiplication and division are applied before addition and subtraction. Operators at the same precedence level are applied from left to right.
Example:
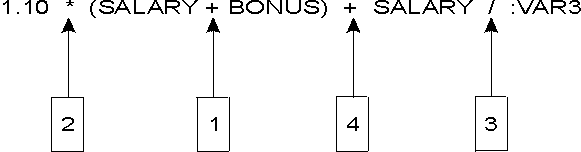 View figure.
View figure.
Concatenation is performed before datetime arithmetic.
A predicate specifies a condition that is true, false, or unknown about a given row or group.
The following rules apply to all types of predicates:
>>-expression----+- = -------+---+-expression--+---------------><
| (1) | '-(subselect)-'
+- <> ------+
+- < -------+
+- > -------+
+- <= ------+
'- >= ------'
Notes:
|
A basic predicate compares two values.
A subselect in a basic predicate must specify a single result column and must not return more than one value.
If the value of either operand is null or the subselect returns no value, the result of the predicate is unknown. Otherwise the result is either true or false.
For values x and y:
Examples:
EMPNO = '528671' PRTSTAFF <> :VAR1 SALARY + BONUS + COMM < 20000 SALARY > (SELECT AVG(SALARY) FROM EMPLOYEE)
>>-expression----+- = -------+---+-SOME-+--(subselect)---------><
| (1) | +-ANY--+
+- <> ------+ '-ALL--'
+- < -------+
+- > -------+
+- <= ------+
'- >= ------'
Notes:
|
A quantified predicate compares a value with a set of values.
The subselect must specify a single result column and can return any number of values, including null values.
A quantified predicate has the same form as a basic predicate except that the second operand is a subselect preceded by SOME, ANY, or ALL.
When ALL is specified, the result of the predicate is:
When SOME or ANY is specified, the result of the predicate is:
Use the information below when referring to the following examples.
TBLA: COLA TBLB: COLB
1 2
2 3
3
4
SELECT * FROM TBLA WHERE COLA = ANY(SELECT COLB FROM TBLB)
Results in 2,3. The subselect returns (2,3). COLA in rows 2 and 3 equals at least one of these values.
SELECT * FROM TBLA WHERE COLA > ANY(SELECT COLB FROM TBLB)
Results in 3,4. The subselect returns (2,3). COLA in rows 3 and 4 is greater than at least one of these values.
SELECT * FROM TBLA WHERE COLA> ALL(SELECT COLB FROM TBLB)
Results in 4. The subselect returns (2,3). COLA in row 4 is the only one that is greater than both these values.
SELECT * FROM TBLA WHERE COLA> ALL(SELECT COLB FROM TBLB WHERE COLB<0)
Results in 1,2,3,4. The subselect returns no values. Thus, the predicate is true for all rows in TBLA.
>>-expression--+-----+--BETWEEN--expression--AND--expression---><
'-NOT-'
|
The BETWEEN predicate compares a value with a range of values. The BETWEEN predicate:
value1 BETWEEN value2 AND value3
is logically equivalent to the search condition:
value1 >= value2 AND value1 <= value3
The BETWEEN predicate:
value1 NOT BETWEEN value2 AND value3
is logically equivalent to the search condition:
NOT(value1 BETWEEN value2 AND value3)
that is:
value1 < value2 OR value1 > value3
If any expression evaluates to a datetime data type, then comparisons will be done with all expressions converted to the appropriate datetime data type.
The values for the expressions in the BETWEEN predicate can have different CCSID values. If a conversion is necessary then it will be based on the above logical equivalence. Conversion is based on the rules for comparisons (see Conversion Rules for String Comparison). If a column's CCSID is chosen as the final CCSID value then both the other values are converted, if necessary, to that CCSID; this need not be true if the value is not a column's CCSID.
EMPLOYEE.SALARY BETWEEN 20000 AND 40000
SALARY NOT BETWEEN 20000 + :HV1 AND 40000
Given the following:
.------------.---------------.-------.
| Expression | Type | CCSID |
+------------+---------------+-------+
| CON_1 | constant | 00001 |
| HV_2 | host variable | 00002 |
| HV_3 | host variable | 00003 |
'------------'---------------'-------'
When evaluating the predicate:
CON_1 BETWEEN :HV_2 AND :HV_3
conversion will be based on considering this to be the same as:
CON_1 >= :HV_2 AND CON_1 <= :HV_3
The values in both HV_2 and HV_3 will be converted to CCSID 00001.
Given the following:
.------------.---------------.-------.
| Expression | Type | CCSID |
+------------+---------------+-------+
| CON_1 | constant | 00001 |
| HV_2 | host variable | 00002 |
| COL_3 | column | 00003 |
'------------'---------------'-------'
When evaluating the predicate:
CON_1 BETWEEN :HV_2 AND COL_3
conversion will be based on considering this to be the same as:
CON_1 >= :HV_2 AND CON_1 <= COL_3
Because the CCSID of the column (that is, 00003) is used as the final CCSID value, the values of CON_1 and HV_2 both will be converted to 00003 before any comparisons are done.
Given the following:
.------------.---------------.-------.
| Expression | Type | CCSID |
+------------+---------------+-------+
| COL_1 | column | 00001 |
| HV_2 | host variable | 00002 |
| CON_3 | constant | 00003 |
'------------'---------------'-------'
When evaluating the predicate:
COL_1 BETWEEN :HV_2 AND CON_3
conversion will be based on considering this to be the same as:
COL_1 >= :HV_2 AND COL_1 <= CON_3
The values in both HV_2 and CON_3 will be converted to CCSID 00001. (Note the difference in this example's conversion when using a column and example 4.)
Given the following:
*------------*-----------------*--------------*
| Expression | Type | Value |
*------------+-----------------+--------------*
| COL_1 | column CHAR(10) | '01/01/1992' |
*------------*-----------------*--------------*
When evaluating the predicate:
COL_1 BETWEEN '07/20/1991' AND '10/22/1992'
the comparison will be done as character strings and the predicate will evaluate to false.
When evaluating the predicate:
COL_1 BETWEEN DATE('7/20/1991') AND '10/22/1992'
the comparison will be done as date types and the predicate will evaluate to true.
>>-+-----+--EXISTS--(subselect)-------------------------------->< '-NOT-' |
The EXISTS predicate tests for the existence of certain rows. The subselect may specify any number of columns, and
The values returned by the subselect are ignored.
Example: EXISTS (SELECT * FROM EMPLOYEE WHERE SALARY > 60000)
>>-expression--+-----+--IN-------------------------------------->
'-NOT-'
>-----+-(subselect)-------------------------+------------------><
| .-,-----------------------. |
| V | |
'-(----+-constant-----------+--+---)--'
+-host_variable_list-+
'-special_register---'
|
The IN predicate compares a value with a set of values.
In the subselect form, the subselect must identify a single result column and may return any number of values, including null values.
An IN predicate of the form:
expression IN (subselect)
is equivalent to a quantified predicate of the form:
expression = ANY (subselect)
An IN predicate of the form:
expression NOT IN (subselect)
is equivalent to a quantified predicate of the form:
expression <> ALL (subselect)
If any value evaluates to a datetime data type, then comparisons will be done with all values converted to the appropriate datetime data type.
In the non-subselect form of the IN predicate, the second operand is a set of one or more values specified by any combination of constants, host variables, host structures, or special registers. This form of the IN predicate is equivalent to the subselect form except that the second operand consists of the specified values rather than the values returned by a subselect.
The values for the expressions in the IN predicate can have different CCSIDs. Conversion occurs where required based on the assumption that:
value1 IN (value2, value3, ...)
is logically equivalent to the clause:
value1 = value2 OR value1 = value3 OR ...
Conversion is based on the rules for comparisons (see Conversion Rules for String Comparison).
Examples
DEPTNO IN ('D01', 'B01', 'C01')
EMPNO IN (SELECT EMPNO FROM EMPLOYEE WHERE WORKDEPT = 'E11')
Given the following:
.------------.---------------.-------.
| Expression | Type | CCSID |
+------------+---------------+-------+
| COL_1 | column | 00001 |
| HV_2 | host variable | 00002 |
| HV_3 | host variable | 00003 |
| CON_4 | constant | 00004 |
'------------'---------------'-------'
When evaluating the predicate:
COL_1 IN (:HV_2, :HV_3, CON_4)
conversion will be based on considering this to be the same as:
COL_1 = :HV_2 OR COL_1 = :HV_3 OR COL_1 = CON_4
The values in HV_2, HV_3, and CON_4 will be converted to CCSID 00001.
Given the following:
.------------.---------------.-------.
| Expression | Type | CCSID |
+------------+---------------+-------+
| HV_1 | host variable | 00001 |
| CON_2 | constant | 00002 |
| CON_3 | constant | 00002 |
| HS_4 | host structure| |
| HV_41 | host variable | 00003 |
| HV_42 | host variable | 00004 |
'------------'---------------'-------'
When evaluating the predicate:
:HV_1 IN ( CON_2, CON_3, :HS_4)
conversion will be based on considering this to be the same as:
:HV_1 = CON_2 OR :HV_1 = CON_3 OR :HV_1 = :HV_41 OR :HV_1 = :HV_42
Thus, the value in HV_1 will be converted to CCSID 00002 before it is compared to CON_2 and CON_3, and the values in HV_41 and HV_42 will be converted to CCSID 00001 before they are compared to HV_1.
>>-column_name--+-----+--LIKE----+-USER------------+------------>
'-NOT-' +-host_variable---+
'-string_constant-'
>-----+------------------------------+-------------------------><
'-ESCAPE--+-host_variable---+--'
'-string_constant-'
|
The LIKE predicate searches for strings that have a certain pattern. The pattern is specified by a string in which the underscore and percent sign have special meanings.
The column_name must identify a string column. If a character string column is identified, the other operands must be character strings. If a graphic string column is identified, the other operands must be graphic strings. With character strings, the terms character, percent sign, and underscore in the following description refer to single-byte characters. With graphic strings, the terms refer to double-byte characters.
Note that trailing blanks in a pattern are usually part of the pattern. The exception to this is that trailing blanks in a pattern that is specified within a fixed-length host variable are ignored when that pattern is compared against a varying-length column.
For character columns, a simple description of the LIKE pattern is as follows:
Let x denote a value of a column and y denote the string specified by the second operand.
The string y is interpreted as a sequence of the minimum number of substring specifiers so each character of y is part of exactly one substring specifier. A substring specifier is an underscore, a percent sign, or any non-empty sequence of characters other than an underscore or a percent sign.
The result of the predicate is unknown if x or y is the null value. Otherwise, the result is either true or false. The result is true if x and y are both empty strings or if there exists a partitioning of x into substrings such that:
It follows that if y is an empty string and x is not an empty string, the result is false.
The predicate x NOT LIKE y is equivalent to the search condition NOT(x LIKE y).
If the CCSID of either the pattern value or the escape value is different than the CCSID of the column, that value is converted to adhere to the CCSID of the column before the predicate is applied.
If the column has a mixed subtype, the pattern can include both SBCS and DBCS characters. The special characters in the pattern are interpreted as follows:
If the column has a field procedure, the procedure is invoked to decode the values of the column, and the comparisons are made with the decoded values.
This clause allows the definition of patterns intended to match values that contain the actual percent and underscore characters. The following rules govern the use of the ESCAPE clause:
For example, if '+' is the escape character, any occurrences of '+' other than '++', '+_', or '+%' in the pattern is an error.
If both the pattern and the escape character are constants, the entire pattern will always be checked for incorrect occurrences of the escape character.
If either the pattern or the escape character is a host_variable, occurrences of the escape character in the pattern will not be validated unless the portion of the pattern proceeding the escape character matches at least one row.
The rules for the LIKE predicate are unchanged with the special register USER. This means that the value of the special register USER is treated as a pattern. USER evaluates to a CHAR(8) string whose value is the user ID of the currently connected user. If the value of USER contains a '_' it will match any character and the result of:
WHERE C1 LIKE USER
would not be the same as the result of:
WHERE C1 = USER
It is recommended that the 'equals' predicate be used where user IDs may contain special characters, and the value of USER is not to be treated as a pattern.
Examples:
Search for the string 'SYSTEMS' appearing anywhere within the PROJNAME column in the PROJECT table.
PROJECT.PROJNAME LIKE '%SYSTEMS%'
Search for a string with a first character of 'J' that is exactly two characters long in the FIRSTNME column of the EMPLOYEE table.
EMPLOYEE.FIRSTNME LIKE 'J_'
In:
C1 LIKE 'AAAA+%BBB%' ESCAPE '+'
'+' is the escape character and indicates that the search is for a string that starts with 'AAAA%BBB'. The '+%' is interpreted as a single occurrence of '%' in the pattern.
both: WHERE COL1 LIKE 'aaa<(AABB)%%(CC)>' and : WHERE COL1 LIKE 'aaa<(AABB)>%<(CC)>' would match the value -->'aaa<(AABBDDZZCC)>' as well as the value -->'aaa<(AABB)>dzx<(CC)>'
WHERE COL1 LIKE 'a%<(CC)>'
would match the values --> 'a<(CC)>' and
'ax<(CC)>' and
'ab<(DDEE)>fg<(CC)>'
WHERE COL1 LIKE 'a_<(CC)>' would match the value --> 'ax<(CC)>' but not the value --> 'a<(XXCC)>'
WHERE COL1 LIKE 'a<__(CC)>' would match the value --> 'a<(XXCC)>' but not the value --> 'ax<(CC)>'
WHERE COL1 LIKE '<>' would match the "empty string" value.
WHERE COL1 LIKE 'ab<(CC)>_'
would match the values --> 'ab<(CC)>d and
'ab<><(CC)>d
>>-column_name--IS--+-----+--NULL------------------------------><
'-NOT-'
|
The NULL predicate tests for null values.
The result of a NULL predicate cannot be unknown. If the value of the column is null, the result is true. If the value is not null, the result is false. If NOT is specified, the result is reversed.
To search for fields that contain null values, the words IS NULL must be used. 'WHERE PAY IS NULL' is correct, but 'WHERE PAY = NULL' is incorrect.
Examples:
EMPLOYEE.PHONE IS NULL SALARY IS NOT NULL
>>-+-----+----+-predicate----------+---------------------------->
'-NOT-' '-(search_condition)-'
.---------------------------------------------------.
V |
>--------+---------------------------------------------+--+----><
'--+-AND-+---+-----+--+-predicate----------+--'
'-OR--' '-NOT-' '-(search_condition)-'
|
A search condition specifies a condition that is true, false, or unknown about a given row or group. When the condition is "true," the row or group qualifies for the results. When the condition is "false" or "unknown," the row or group does not qualify.
The result of a search condition is derived by application of the specified logical operators (AND, OR, NOT) to the result of each specified predicate. If logical operators are not specified, the result of the search condition is the result of the specified predicate.
AND and OR are defined in the following table in which P and Q are any
predicates:
Table 5. Truth Tables for AND and OR
| P | Q | P AND Q | P OR Q |
|---|---|---|---|
| True | True | True | True |
| True | False | False | True |
| True | Unknown | Unknown | True |
| False | True | False | True |
| False | False | False | False |
| False | Unknown | False | Unknown |
| Unknown | True | Unknown | True |
| Unknown | False | False | Unknown |
| Unknown | Unknown | Unknown | Unknown |
NOT(true) is false, NOT(false) is true, and NOT(unknown) is unknown.
Search conditions within parentheses are evaluated first. If the order of evaluation is not specified by parentheses, NOT is applied before AND, and AND is applied before OR. The order in which operators at the same precedence level are evaluated is undefined to allow for optimization of search conditions.
Examples:
 View figure.
View figure.
 View figure.
View figure.