 View figure.
View figure.This chapter describes the facilities that are available for designing and implementing applications, and discusses some considerations that application developers and the database administrator (DBA) should take into account.
This section discusses the application implementation alternatives that developers can consider. For each environment, several different ways of implementing application functions are identified and discussed.
The following broad categories of applications are also discussed:
For batch/interactive DB2 Server for VSE usage environments, there are two alternatives for application implementations:
These are programs written in FORTRAN, PL/I, COBOL, or assembler that would run as VSE batch jobs or interactive (VSE/ICCF) applications.
In addition, you can use SQL Extended Dynamic Statements to code your own preprocessor in assembler language. Although the data requests must be made in SQL, you can code your preprocessor to translate some other data manipulation language to SQL statements. General concepts for coding a preprocessor are in the DB2 Server for VSE & VM Application Programming manual.
These are executions of the Database Services (DBS) Utility, which supports execution of SQL statements and DBS commands.
The primary vehicle for implementing application functions would be high-level-language programs written for execution as batch jobs in either VSE partitions or interactive partitions.
VSE batch jobs support unit record devices or VSE/POWER spool files and VSE files for input and output processing. The DB2 Server for VSE system can be used to support data sharing, data recovery, and data function requirements of the applications.
Application programs written for execution under VSE/ICCF can support some level of interaction with a terminal user. The VSE/ICCF environment supports invocation of an application from a user terminal, and can be effectively used to manage user input (SYSIPT) and output (SYSLST) files as VSE/ICCF files.
On batch/interactive systems with sufficient real storage available for dynamic SQL processing, the DBS Utility can be effectively used for file maintenance and reporting operations. For detailed information on maintenance, see Chapter 3, Maintaining Your Database.
Briefly, the DBS Utility can be used to:
Application functions that do not require procedural logic or variable information can be carried out as a sequence of DBS SQL statements in a SYSIPT (or VSE/ICCF) input file.
You can unload the data from the database using a DBS UNLOAD command, and reload it with a different structure using the DBS RELOAD command.
For example, the utility can be used to load and unload data in a zoned-decimal format. Zoned-decimal is not a DB2 Server for VSE data type, so the DBS Utility converts the data as needed.
If you include the VSE/ICCF /DATA INCON job control statement in the DBS job control, the utility takes its input (SYSIPT records) from the terminal input, and displays its output (SYSLST) at the terminal. You can tailor the DBS output to your terminal, by using the DBS SET LINEWIDTH command to specify the number of characters to be displayed on an output line.
The basic capabilities available in the batch/interactive environment are extended with the addition of the CICS subsystem and the online support. The following sections describe these additional capabilities.
The main method for implementing online transactions is through CICS high-level-language transaction processing programs. These programs can access the DB2 Server for VSE system and exploit the unique facilities of the CICS subsystem. Your transactions must be coded in COBOL, assembler, PL/I, or some other language that the CICS subsystem supports and for which you have coded a preprocessor. The CICS subsystem does not support FORTRAN.
The CICS transaction processing environment supports terminal-driven, fast-response-time application processing. It also provides facilities for interconnecting systems and distributing application processing in a network of systems.
In addition to supporting CICS transaction access to the DB2 Server for VSE system, data stored by the DB2 Server for VSE system can be shared with batch and VSE/ICCF application programs.
Data can be queried through either application programs, the DBS Utility, or ISQL. Which facility should be used depends on the complexity of the query and whether it will be used repeatedly.
Query functions can be coded as application programs or processed through ISQL. ISQL enables end users to formulate SQL queries on data and view and format the results.
You can satisfy many of your end users' data retrieval requirements by making the ISQL facilities available to them.
There are several ways to design queries that will be used repeatedly:
Queries can be developed under ISQL and stored for future, repetitive use. End users can develop and store their own, or as DBA, you may choose to create a specific set for distribution. When you develop a stored query you can also save information about how its display should be formatted, so that when users invoke the query, the display will be automatically formatted for them. In addition, if you must later change a stored query, you can also change the formatting information. When possible, ISQL saves existing formatting information so that you do not have to re-enter it when there is a minor change to a stored query.
Stored queries cannot be shared among users, so a separate copy must be stored for each of them. The developer of a set of queries could use an ISQL routine (see ISQL Routines) to enter and store them; then, any user who needed access to those queries would simply run the routine to obtain a copy of them. The user must have SELECT authority on the developer's ROUTINE table.
One of the advantages of stored queries is that users simply START them; they need not be familiar with SQL. With parameters, stored queries can be developed that are general in nature--that is, they can support variable input for the same basic function.
| Note: | If you develop stored queries and routines for use by multiple users, you may want to consider devising your own HELP tables to provide information on them. See Creating Your Own HELP Text Tables. |
For more complex application functions that involve multiple SQL functions, consider using ISQL routines. Routines have the following advantages over stored queries:
Like stored queries, routines can be parameterized to provide variability in the function provided, and users need not understand the details of the underlying statements.
Because stored routines may support complex functions, you may want to account for possible error conditions, by using the ISQL SET RUNMODE and SET AUTOCOMMIT commands to provide for error handling in routines.
Figure 34 illustrates a routine that updates the SALARY value in the sample EMPLOYEE table. It also displays a report showing the old and new values, and prints the report of the transaction.
Figure 34. Example ISQL Routine for the EMPLOYEE Table Update
SALUPD 0010 COMMIT WORK SALUPD 0020 SET AUTOCOMMIT OFF SALUPD 0030 SET RUNMODE CANCEL SALUPD 0040 UPDATE SQLDBA.EMPLOYEE - SALUPD 0050 SET SALARY = SALARY + &3 - SALUPD 0060 WHERE EMPNO = &1 AND JOB = &2; SALUPD 0070 SELECT EMPNO,JOB,SALARY-&3,SALARY - SALUPD 0080 FROM SQLDBA.EMPLOYEE - SALUPD 0090 WHERE EMPNO = &1 AND JOB = &2 - SALUPD 0100 UNION - SALUPD 0110 SELECT EMPNO,JOB,SALARY - SALUPD 0120 FROM SQLDBA.EMPLOYEE - SALUPD 0130 WHERE EMPNO ¬= &1 AND JOB = &2 - SALUPD 0140 ORDER BY 1 SALUPD 0150 FORMAT COL 3 NAME 'OLD SALARY' SALUPD 0160 FORMAT COL 4 NAME 'NEW SALARY' SALUPD 0170 FORMAT TOTAL (3 4) SALUPD 0180 FORMAT TTITLE 'UPDATED THE SALARY OF EMPLOYEE &1 BY $ &3' SALUPD 0190 DISPLAY SALUPD 0200 PRINT COPIES 3 SALUPD 0210 END SALUPD 0220 COMMIT WORK |
To execute the ISQL routine in Figure 34, a user would enter (during an ISQL session):
RUN SALUPD (empno job change)
The routine is designed to update one row of the EMPLOYEE table based on parameter input specified on the RUN command, and run a query that displays the results of the update. All salaries for the job are displayed, not just the updated salary. After reviewing the display, the user enters an END command to have three copies of the display printed; then, the routine commits the transaction to the database. If the displayed results are not correct, the user can cancel the update by issuing the CANCEL command in place of the END command.
In VM, ISQL and SQL statements can be stacked by an EXEC for execution by ISQL. Such EXECs can be created using either EXEC 2 or the System Product Interpreter, and can be written for execution either during or outside of an ISQL session. (You cannot write one that will run both ways.)
To process an ISQL EXEC that is designed to run during an ISQL session, the user enters "CMS" to get into Subset mode, and then types in the name of the EXEC.
The EXEC must place a RETURN CMS command as the first entry on the stack, in order to cause control to be returned to ISQL for processing of the rest of the statements on the stack.
| CAUTION: | EXECs that are processed from CMS Subset should not run ISQL, the DBS Utility, or SQL applications, as the results will be unpredictable. |
Figure 35 shows an example of an EXEC called UPDSAL.
Figure 35. ISQL EXEC for Updating the EMPLOYEE Table During an ISQL Session
/* UPDSAL EXEC 6/10/90 */
/* THIS EXEC PROGRAM ALLOWS A USER TO PERFORM UPDATES ON */
/* THE SALARY COLUMN OF THE EMPLOYEE TABLE. IT IS DESIGNED */
/* TO BE STARTED WHILE IN A CMS SUBSET, AND IT AUTOMATICALLY */
/* RETURNS TO ISQL TO EXECUTE THE UPDATE COMMANDS WHICH HAVE BEEN */
/* PLACED ON THE PROGRAM STACK; THEN THE TABLE IS DISPLAYED AND */
/* PRINTED TO SHOW THE CHANGES MADE. */
PARTLIST = "" /* WILL CONTAIN LIST OF EMPNO'S WHOSE */
/* TOTAL SALARY HAS CHANGED */
DO COUNT = 1
DO FOREVER
SAY "ENTER EMPNO (ENTER 'END' WHEN DONE)"
PULL E
IF E = 'END' THEN LEAVE COUNT
SAY ENTER JOB /* USER ENTERS UPDATE INFORMATION */
PULL J /* (DATA IS CHECKED FOR VALID */
SAY ENTER CHANGE TO SALARY /* TYPES) */
PULL CTS
IF DATATYPE(E,W) & DATATYPE(J,A) & DATATYPE(CTS,N) THEN LEAVE
ELSE SAY "DATA ENTERED INCORRECTLY--TRY AGAIN"
END
UPD.COUNT = "UPDATE EMPLOYEE SET SALARY = SALARY + "CTS,
" WHERE EMPNO = "E" AND JOB = "J /* UPDATE COMMANDS ARE */
EMPLIST = EMPLIST", "E /* HELD IN AN ARRAY */
END
QUEUE RETURN /* TO ISQL */
IF COUNT = 1 THEN EXIT /* NO UPDATES? */
ELSE EMPLIST = SUBSTR(EMPLIST,3) /* REMOVE FIRST COMMA */
QUEUE COMMIT WORK
QUEUE SET AUTOCOMMIT OFF
DO N = 1 TO COUNT-1 /* PLACE UPDATE COMMANDS */
QUEUE UPD.N /* ON PROGRAM STACK */
END
QUEUE "SELECT JOB, EMPNO, SALARY FROM EMPLOYEE -"
IF COUNT > 2
THEN QUEUE "WHERE EMPNO IN ("EMPLIST") -"
ELSE QUEUE "WHERE EMPNO = "EMPLIST" -" /* QUERY, FORMATTING, */
QUEUE "ORDER BY JOB, EMPNO" /* AND PRINT COMMANDS */
QUEUE FORMAT GROUP JOB
QUEUE FORMAT SUBTOTAL SALARY
QUEUE "FORMAT TTITLE 'SUMMARY OF CHANGES IN SALARY TOTALS'"
QUEUE DISPLAY
QUEUE PRINT COPIES 3
QUEUE END
QUEUE COMMIT WORK
|
Here, an ISQL EXEC stacks SQL UPDATE statements that are defined based on the user's responses to prompts for information. The prompts and stacking of updates are done in a loop, so that multiple EMPLOYEE rows can be updated with one execution of the EXEC.
After the user has entered all the updates, the EXEC stacks a query that will display and print the results of the updates.
To process an ISQL EXEC that is designed to run outside of an ISQL session, the user simply enters the name of the EXEC--that is, the user initiates the EXEC while using CMS, without having to start or even know about ISQL.
This type of EXEC would not include a RETURN command, because there is no ISQL session to return to. Instead, it must include an ISQL EXIT command as the last entry on the stack, and must start ISQL (EXEC ISQL) after the stack entries have been completed.
Figure 36 illustrates an ISQL EXEC designed to be run outside of an ISQL session, which carries out the same function as the one shown in Figure 35.
Figure 36. ISQL EXEC for Updating the EMPLOYEE Table Outside of an ISQL Session
/* XUPDSAL EXEC */
/* THIS EXEC PROGRAM ALLOWS A USER TO PERFORM UPDATES ON */
/* THE SALARY COLUMN OF THE EMPLOYEE TABLE. IT IS DESIGNED */
/* TO BE STARTED WHILE IN CMS (WITHOUT AN ISQL SESSION). IT */
/* AUTOMATICALLY EXECUTES ISQL AFTER QUEUING UPDATE COMMANDS AND */
/* AN ISQL EXIT COMMAND ON THE PROGRAM STACK. COMMANDS ARE ALSO */
/* STACKED TO DISPLAY AND PRINT THE CHANGES MADE. */
EMPLIST = "" /* WILL CONTAIN LIST OF EMPNO'S WHOSE */
/* TOTAL SALARY HAS CHANGED */
DO COUNT = 1
DO FOREVER
SAY "ENTER EMPNO (ENTER 'END' WHEN DONE)"
PULL E
IF E = 'END' THEN LEAVE COUNT
SAY ENTER JOB /* USER ENTERS UPDATE INFORMATION*/
PULL J /* (DATA IS CHECKED FOR VALID */
SAY ENTER CHANGE TO SALARY /* NUMBERS) */
PULL CTS
IF DATATYPE(E,W) & DATATYPE(J,A) & DATATYPE(CTS,N) THEN LEAVE
ELSE SAY "DATA ENTERED INCORRECTLY--TRY AGAIN"
END
UPD.COUNT = "UPDATE EMPLOYEE SET SALARY = SALARY + "CTS,
" WHERE EMPNO = "E" AND JOB = "J /* UPDATE COMMANDS ARE */
EMPLIST = EMPLIST", "E /* HELD IN AN ARRAY */
END
IF COUNT = 1 THEN EXIT /* NO UPDATES? */
ELSE EMPLIST = SUBSTR(EMPLIST,3) /* REMOVE FIRST COMMA */
QUEUE COMMIT WORK
QUEUE SET AUTOCOMMIT OFF
DO N = 1 TO COUNT-1 /* PLACE UPDATE COMMANDS */
QUEUE UPD.N /* ON PROGRAM STACK */
END
QUEUE "SELECT EMPNO, JOB, SALARY FROM EMPLOYEE -"
IF COUNT > 2
THEN QUEUE "WHERE EMPNO IN ("EMPLIST") -"
ELSE QUEUE "WHERE EMPNO = "EMPLIST" -" /* QUERY, FORMATTING, */
QUEUE "ORDER BY JOB, EMPNO" /* AND PRINT COMMANDS */
QUEUE FORMAT GROUP JOB
QUEUE FORMAT SUBTOTAL SALARY
QUEUE "FORMAT TTITLE 'SUMMARY OF CHANGES IN SALARY TOTALS'"
QUEUE DISPLAY
QUEUE PRINT COPIES 3
QUEUE END
QUEUE COMMIT WORK
QUEUE EXIT /* THE ISQL EXECUTION */
EXEC ISQL /* TO EXECUTE THE COMMANDS THAT WERE STACKED */
|
Avoid using commands that would result in ISQL issuing a message that requires a response. For example, SET AUTOCOMMIT OFF will cause message ARI7602D to be issued when the EXIT command is entered, and this message requires a response of either COMMIT or ROLLBACK. Because of the interactive design of ISQL, the response must be entered by the user, and will not be accepted from the command stack.
If neither stored queries nor ISQL routines are appropriate, you can program query functions. Their primary advantage is application tailoring of the end user interface--that is, the application controls the user syntax for requesting data and the output format for displaying results. Program a query function if an application-specific interface must be provided to end users.
Another advantage is their ability to apply procedural logic. Unlike stored queries which support only a single SQL statement, or ISQL routines which support a fixed sequence of statements, programmed query functions can run different statements or statement sequences based on the results of previous statements or function input.
When designing a programmed query function, you may want to consider using the SQL Dynamic Statement support. With this, the program can translate queries in an application-specific syntax to SQL statements, which are then dynamically compiled and processed. Such a program can provide many query functions with minimal coding.
For even more sophisticated applications, you can use extended dynamic statements to code preprocessors for programming languages that are not supported by the application server. See the DB2 Server for VSE & VM Application Programming manual for information.
Reports can be produced through ISQL, the DBS Utility, or an application program.
When ISQL terminal users obtain query results through a SELECT statement, they can create reports from them using the FORMAT command. This command provides the following:
Both top and bottom titles can be created. If no top title is specified, a default is provided that consists of the first 100 characters of the SELECT statement that provided the query results. The bottom title defaults to blanks.
Both subtotals and totals can be provided for desired columns.
The characters to be used to separate columns can be specified.
If outlining is specified, successive duplicate values for a desired column are not repeated unless they start a new screen (or a new page for printed reports).
Users can control such things as:
For more information on formatting reports, see the DB2 Server for VSE & VM Interactive SQL Guide and Reference manual.
To obtain copies of a report, a user enters an ISQL PRINT command. This command allows you to specify the number of copies desired and the output printer class to be used. The printed reports are dated and the pages numbered.
In VSE, if you enter a PRINT command, but the printer is busy, ISQL will send you a message. Along with this message, ISQL will give you the option of:
When the printer is free, ISQL displays the message "THE PRINT IS IN PROGRESS".
| Note: | Some terminals support a copy key that, when pressed, causes a screen image to be printed on the CICS local printer. Such support does not follow any queue protocol and, if you use it while ISQL PRINT is in progress, the screen image may be interspersed with the ISQL PRINT output. |
In VM, the results of an ISQL PRINT command are sent to the user's virtual printer. The default print location will be wherever the user normally has his or her output printed. However, the user can change the destination of the files by going into CMS Subset mode, entering the SPOOL and TAG commands to route the output elsewhere, then returning to ISQL (by entering the RETURN command) and entering the PRINT command.
The following command, entered in CMS, will cause the printer output to be sent to the user's virtual reader:
CP SP PRT TO *
A reader file can read into a CMS file for inclusion in the text report.
Routines can be used to generate reports automatically. This is especially helpful for daily or weekly reports. A routine could issue a SELECT statement, format the output into the desired report, and print the report.
For more information on ISQL report writing, see the DB2 Server for VSE & VM Interactive SQL Guide and Reference manual.
The DBS Utility provides a limited report-writing capability through its support for SQL SELECT statement processing. The DBS SELECT processing writes the results of a query to the DBS Utility message file (SYSLST print file), with a default of 120 print positions per print line and 60 print lines per print page. These defaults can be changed through the DBS SET command. Refer to the DB2 Server for VSE & VM Database Services Utility manual for more information.
If an application requires special handling that is not supported by ISQL or the DBS Utility, it may be necessary to write a program to generate a report. For example, an application may need to generate output on special forms in a special format.
You can vary the contents of a programmed report with program variables. Using the Dynamic Statement support in SQL, you could even vary the tables being reported. When using the Dynamic Statement support, you would use the SQL DESCRIBE statement to obtain information on the data being accessed (for example, column names and column data types).
For complex application requirements that cannot be met by ISQL or DBS Utility facilities, you must code a program using DB2 Server for VSE & VM facilities.
In addition, you can use DB2 Server for VSE & VM extended dynamic statements to code your own preprocessor in assembler language to support other languages that can be mapped to SQL. Extended dynamic statements are explained in the DB2 Server for VSE & VM Application Programming manual.
Some application functions can be implemented using a combination of VM EXEC and DB2 Server for VM EXEC facilities. Several useful examples are discussed in the following sections.
| Note: | If you are using EXECs to invoke applications or to invoke other EXECs that access the application server, refer to SQLRMEND EXEC. |
The DBS Utility provides facilities for unloading tables to and loading them from CMS files. While in a CMS file, data can be manipulated by an editor (for example, XEDIT). Users can take advantage of the combination of these capabilities for editing data in their tables.
| CAUTION: | The following technique is not recommended for tables for which multiple users have UPDATE, INSERT, or DELETE privileges. It assumes that only the user doing the editing has update capabilities. |
Figure 37 shows an EXEC that can be used to edit private tables.
Figure 37. Example EXEC for Editing a Private Table
/* EDITTAB EXEC */
/* THIS EXEC PROGRAM USES THE SQLDBSU EXEC TO UNLOAD A USER'S TABLE*/
/* INTO A CMS FILE FOR EDITING WITH XEDIT. AFTER EDITING, THE USER*/
/* HAS THE OPTION OF REPLACING THE TABLE WITH THE EDITED CMS FILE, */
/* AND THEN MAY HAVE THE TABLE DISPLAYED BY ISQL. TWO CMS FILES */
/* MUST PREVIOUSLY HAVE BEEN CREATED WHICH CONTAIN COMMANDS TO */
/* SQLDBSU; THEIR FILENAMES MUST BE THE SAME AS THE NAME OF THE */
/* TABLE, TRUNCATED TO 8 CHARACTERS, AND THE FILETYPES MUST BE */
/* 'UNLD' AND 'REPL' (EXAMINE CLOSELY THE EXAMPLE GIVEN FOR THE */
/* EMPLOYEE TABLE.) */
SIGNAL ON ERROR
SAY WHICH TABLE WOULD YOU LIKE TO EDIT?
PULL TNAME
FN = STRIP(LEFT(TNAME,8))
"STATE" FN "UNLD" /* VERIFIES EXISTENCE OF */
"STATE" FN "REPL" /* DBSU CONTROL FILES */
"FILEDEF WORKFILE DISK" FN "TABLE (LRECL 80 RECFM FBA"
"EXEC SQLDBSU IN("FN "UNLD) PR(PRINTER)" /* UNLOAD TABLE */
"XEDIT" FN "TABLE" /* FOR EDITING */
SAY "DO YOU WANT TO REPLACE THE" TNAME "TABLE? (Y OR N)"
PULL ANSWER1
IF ABBREV(NO,ANSWER1,1) THEN EXIT
"EXEC SQLDBSU IN("FN "REPL) PR(PRINTER)" /* TABLE IS REPLACED */
SAY WOULD YOU LIKE TO DISPLAY THE NEW TABLE? (Y OR N)
PULL ANSWER2
IF ABBREV(NO,ANSWER2,1) THEN EXIT
QUEUE "SELECT * FROM" TNAME /* MOVE ISQL COMMANDS INTO THE */
QUEUE DISPLAY /* PROGRAM STACK */
QUEUE END
QUEUE EXIT
EXEC ISQL
EXIT /* END OF PROGRAM */
ERROR: /* ERROR HANDLING */
SAY "UNEXPECTED EDITTAB TERMINATION RETURN CODE:" RC,
" LINE:" SIGL
|
Here, the EDITTAB EXEC prompts the user for the name of the table to be edited (only simple names are accepted), then uses that name to verify the existence of DBS command files needed to support editing of the table. The work file used for the CMS file version of the table is then defined (in the FILEDEF WORKFILE command). The DBS Utility (SQLDBSU) is then initiated to unload the table to the work file. Once the table has been unloaded, XEDIT is initiated to edit the work file.
On completion of the XEDIT session, the user is asked if the table is to be replaced in the database by its edited version. If the answer is yes, the DBS Utility is initiated to perform the REPLACE operation.
Finally, the EXEC asks the user if the new version of the table should be displayed. If the answer is yes, the table is displayed using ISQL.
For the EDITTAB EXEC to work, two DBS command files must be established for each table that is to be supported. Figure 38 and Figure 39 show the DBS command files needed to edit a user's version of the EMPLOYEE sample table.
| Note: | These examples assume that the user's version of the EMPLOYEE table, userid.EMPLOYEE, has already been created. |
The command file in Figure 38 unloads the EMPLOYEE table to a file that has been defined as WORKFILE. (This is the file defined in EDITTAB as a CMS file with a file name using the first eight characters of the table name, and a file mode of TABLE.) The information following the SELECT statement identifies the location in the output file (WORKFILE) where the data for the columns in the select-list should be placed.
Figure 38. DBS Unload Command File for Editing EMPLOYEE Table
COMMENT 'EMPLYEE UNLD A'
COMMENT 'DATAUNLOAD JOB FOR EDITING A USERS EMPLOYEE TABLE'
DATAUNLOAD
SELECT * FROM EMPLOYEE ORDER BY EMPNO;
EMPNO 5-10 CHAR
FIRSTNME 12-23 CHAR
MIDINIT 25 CHAR
LASTNAME 27-41 CHAR
WORKDEPT 43-45 CHAR
PHONENO 47-50 CHAR
HIREDATE 52-61 CHAR
JOB 63-70 CHAR
EDLEVEL 72-73 CHAR
SEX 75 CHAR
BIRTHDATE 77-86 CHAR
SALARY 88-96 CHAR
BONUS 98-106 CHAR
COMM 108-116 CHAR
OUTFILE (WORKFILE)
|
Figure 39. DBS Command File for Replacing Edited EMPLOYEE Table
COMMENT 'EMPLYEE REPL A'
COMMENT 'DATALOAD JOB FOR REPLACING AN EDITED EMPLOYEE TABLE'
DELETE FROM EMPLOYEE;
DATALOAD TABLE (EMPLOYEE)
EMPNO 5-10 CHAR
FIRSTNME 12-23 CHAR
MIDINIT 25 CHAR
LASTNAME 27-41 CHAR
WORKDEPT 43-45 CHAR
PHONENO 47-50 CHAR
HIREDATE 52-61 CHAR
JOB 63-70 CHAR
EDLEVEL 72-73 CHAR
SEX 75 CHAR
BIRTHDATE 77-86 CHAR
SALARY 88-96 CHAR
BONUS 98-106 CHAR
COMM 108-116 CHAR
INFILE (WORKFILE)
COMMIT WORK;
|
The command file in Figure 39 deletes the existing rows of the user's EMPLOYEE table, and loads the edited WORKFILE version of the table into it. The information between the DATALOAD table statement and the INFILE statement identifies the columns in the table to be loaded with the data from the input file at the specified locations. All the EMPLOYEE table columns here will be loaded with data from the WORKFILE input file. For example, data in positions 5 to 10 of the file will be loaded into the EMPNO column.
Another variation of the EDITTAB EXEC would be an EXEC that edited only a portion of the user's table. To do this, the DATAUNLOAD and DATALOAD command files must be selective about which rows are unloaded and replaced. This can be done using a subquery on the DATAUNLOAD, and a WHERE clause on the DELETE statement.
Figure 40 shows an example where the EXEC unloads an ISQL routine from the user's ROUTINE table, invokes XEDIT on the unloaded rows, and gives the user the option of reloading the edited routine back into the ROUTINE table.
Figure 40. Example EXEC for Editing Routines
/* EDITROUT EXEC */
SIGNAL ON ERROR
SAY WHICH ROUTINE WOULD YOU LIKE TO EDIT?
PULL RNAME
"STATE" RNAME "UNLD"
"STATE" RNAME "REPL"
"FILEDEF WORKFILE DISK" RNAME "TABLE (LRECL 100 RECFM FBA"
"EXEC SQLDBSU IN("RNAME "UNLD) PR(PRINTER)
"XEDIT" RNAME "TABLE"
SAY "DO YOU WANT TO REPLACE THE" RNAME "ROUTINE? (Y OR N)"
PULL ANSWER1
IF ABBREV(NO,ANSWER1,1) THEN EXIT
"EXEC SQLDBSU IN("RNAME "REPL) PR(PRINTER)"
SAY WOULD YOU LIKE TO DISPLAY THE ROUTINE? (Y OR N)
PULL ANSWER2
IF ABBREV(NO,ANSWER2,1) THEN EXIT
QUEUE "SELECT * FROM ROUTINES WHERE NAME='"RNAME"' -"
QUEUE "ORDER BY SEQNO"
QUEUE DISPLAY
QUEUE END
QUEUE EXIT
EXEC ISQL
EXIT
ERROR:
SAY "UNEXPECTED TERMINATION OF ROUTINE EDIT RETURN CODE:" RC,
" LINE:" SIGL
|
Figure 41. Example DBS DATAUNLOAD Command File for Editing Routine XMPLROUT
COMMENT 'XMPLROUT UNLD A'
DATAUNLOAD
SELECT NAME, SEQNO, COMMAND FROM ROUTINE
WHERE NAME = 'XMPLROUT';
NAME 1-8 CHAR
SEQNO 10-15 CHAR
COMMAND 17-95 CHAR
OUTFILE (WORKFILE)
|
Figure 42. Example DBS Command File for Replacing Routine XMPLROUT
COMMENT 'XMPLROUT REPL A'
DELETE FROM ROUTINE
WHERE NAME = 'XMPLROUT';
DATALOAD TABLE (ROUTINE)
NAME 1-8 CHAR
SEQNO 10-15 CHAR
COMMAND 17-95 CHAR
INFILE (WORKFILE)
COMMIT WORK;
|
Complex applications that are coded as programs (as opposed to DBS Utility input files or ISQL sessions) could involve many programs that operate on many tables. This section discusses how to make large-scale application development easier.
The DB2 Server for VSE & VM system can be used by application developers to prototype data designs and implement them during the application development process. In particular, in DB2 Server for VSE, the ability to dynamically CREATE, ALTER, and DROP tables from an online, interactive environment allows a developer to experiment with different design alternatives. A developer can then exploit the |DB2 Server for VSE & VM catalog tables and explanation tables for documentation and analysis of data designs.
The DB2 Server for VSE & VM facilities that should be considered for data prototyping activities are identified in the following sections.
ISQL or the DBS Utility can be used to enter table, view and index definitions for validating and testing data design. The interactive definition through ISQL gives the developer direct feedback on definitional errors. This feedback not only addresses syntax errors, but also addresses data mapping errors in view definitions.
Furthermore, if SQL definitional commands are entered through ISQL, these commands may be saved as stored queries. By saving the definitional commands, they can be recalled, modified and rerun as needed.
If you are developing your system under VSE/ICCF, you can save definitional statements by storing them in VSE/ICCF files that are used as input (SYSIPT) to the DBS Utility.
If you are developing your system under CMS, you can save definitional statements by storing them in CMS files that are used as input (SYSIN) to the DBS Utility.
Tables created for data design purposes can be loaded with test data using any one of several facilities, depending on the source of test data and the availability of machine readable versions of the data.
If data exists on a sequential file, or can be put into a sequential file, test data can be loaded using the DBS DATALOAD command.
If the data does not exist in machine readable form, or cannot be readily converted to a sequential format, it may be necessary to enter the data by hand. This could be done using the ISQL INPUT command or by building a file for input to the DBS Utility. In DB2 Server for VM the input file to the DBS Utility is a CMS file. In DB2 Server for VSE the input file to the DBS Utility is a VSE/ICCF file.
If the data can be found in existing DB2 Server for VSE & VM tables in the application development database, then data can be copied using the SQL INSERT statement.
If the data can be found in existing tables in another database, the data can be moved using either DBS UNLOAD and RELOAD or DBS DATAUNLOAD and DATALOAD commands. The UNLOAD/RELOAD commands allow easy movement of data on a table or dbspace level. DATAUNLOAD/DATALOAD lets you be more selective in what you want to unload, and where you want to load it. That is, rather than move an entire table, you can use DATAUNLOAD/DATALOAD to move only certain columns of certain rows of a table.
The catalog tables form a base for design documentation in as much as the catalog tables can be queried and used to generate reports. In addition to containing the base information from the SQL definitional commands, the catalog tables contain useful statistical information and dependency information.
You can analyze how a given design will perform by using the explanation tables and the SQL EXPLAIN statement.
The EXPLAIN statement can be issued in a program, from an ISQL terminal, by way of the DBS Utility, or through an application program. It lets you get information about the structure and execution performance of other SQL statements (especially the SELECT statement). Naturally, execution performance is affected by the data design.
In addition to the EXPLAIN statement, you can get an idea of how well a given SELECT statement performs by using the ISQL query cost estimate. The query cost estimate is displayed before the result of a SELECT statement is displayed. It is also displayed at the end of every SELECT result in ISQL.
The query cost estimate is a relative number (not expressed in real units) that represents an estimate of the resources used to process the statement. The query cost estimate displayed in ISQL is not the same number that can be obtained by using EXPLAIN. The cost estimate displayed by EXPLAIN is the number that is used internally, while the number displayed by ISQL is the internal number divided by 1000. This makes the query cost estimate more significant to a terminal user.
Application function can be prototyped using ISQL or DBS facilities for testing and debugging SQL statements to be used by the application.
The stored queries support can be effectively used to develop SQL statements to be used in an application. The stored queries could be developed for a test database. By using parameterized stored queries, you can simulate the use of program variables and test the results of your SQL statement against various input cases.
You can develop logical sequences of SQL statements by using the ISQL routine support. Different routines would be developed for different paths through the application logic. Again, parameterized stored routines can be effectively used to simulate program variables and test the functional results of the application path against various input cases.
You can use the ISQL SET RUNMODE command to aid in testing (and, perhaps, correcting) the application logic in routines.
SET RUNMODE can be coded in the routine or issued from the terminal. It lets you stop or continue the processing of an ISQL routine when an error is encountered.
You can use the DBS Utility to try out SQL statements or sequences of SQL statements. Note however, you cannot use it to process parameterized SQL statements or SQL statements having host variables.
Using the DBS Utility to test SQL statements in VSE has the advantage of keeping the SQL statements in a VSE/ICCF file that can be modified. When testing is complete, you can include the VSE/ICCF file in a source code file. If you are using the DBS Utility under VSE/ICCF, use the VSE/ICCF editor to modify the command sequence for each test run.
Using the DBS Utility to test SQL statements in VM has the advantage of keeping the SQL statements in a CMS file that can be modified. When testing is complete, the CMS file can be included in a source code file. Using the DBS Utility under CMS, you would have to modify the command sequence using a CMS editor (XEDIT, for example) for each test run.
As in ISQL, the DBS Utility also provides error handling. Issue the command SET ERRORMODE to tell the utility how (or if) it is to process SQL and DBS commands after an error has occurred.
For development of application code, VSE/ICCF and CMS provides an interactive environment in which to build source code files, to run the DB2 Server for VSE & VM preprocessors, to run the high-level-language compilers, and to test batch (or VSE/ICCF) applications. In VSE, tests of CICS transactions must be run under the CICS subsystem.
Using either the VSE/ICCF editor or a CMS editor, developers can interactively build and edit source statements for their programs. Developers can use the DBS Utility to test SQL statements. They can copy tested statements into the source file, and modify them for the appropriate programming language syntax.
If many applications are to use the same host variables or the same SQL statements, the developers should consider using the SQL INCLUDE statement, which causes the preprocessors to include source lines from other source members (VSE) or CMS files (VM). For example, a developer can place a lengthy SELECT statement here and use that query in many programs by coding SQL INCLUDE statements.
The DB2 Server for VSE preprocessors can be run under VSE/ICCF, using VSE/ICCF files for source code input, or under CMS, using CMS files for source code input. The printed output from the preprocessors, SYSLST for VSE and SYSPRINT for VM, can be directed under VSE/ICCF to VSE/ICCF files, or under CMS, to CMS files for developer review from the terminal. Similarly, the punch output, SYSPCH for VSE and SYSPUNCH for VM, from the preprocessors can be directed under VSE/ICCF to VSE/ICCF files or under CMS, to CMS files, for input to the appropriate compiler.
The preprocessors integrate any external source lines from INCLUDE statements. Use of the INCLUDE statement does not cause more compilation steps.
When developing a program with embedded SQL statements, run the preprocessors with a CHECK option. Under this option the preprocessor produces diagnostics on the SQL in the program, but does not create a package or compiler input. Therefore initial code development and debugging can be done on just a skeleton of the final program.
When preprocessing programs under development, application developers can back up packages that they create with the DBS Utility UNLOAD PROGRAM command. For information on this command, see the DB2 Server for VSE & VM Database Services Utility manual.
To test user SQL programs the developer must preprocess, compile, and link-edit the program as a multiple user mode batch application program. This can either be done under VSE/ICCF, or as a normal VSE batch job.
Once an application has been preprocessed, compiled, and link-edited, normal VSE/ICCF procedures for application execution can be used. The only DB2 Server for VSE requirement for program execution is that the VSE/ICCF control statement "/OPTION GETVIS=AUTO" must follow the "/LOAD" statement. The program only needs to be re-preprocessed if the SQL statements that the program runs are modified.
To test user SQL programs under CMS, the application developer would preprocess, compile, and link-edit the program as a multiple user mode application program, using the usual CMS commands.
Following this, CMS commands for application execution can be entered (for example, START and RUN).
If you develop a DB2 Server for VM application that invokes CMS Subset, be sure to tell users not to invoke any commands, programs, or EXECs that access the application server while in CMS Subset mode. (The results would be unpredictable and error conditions could be generated.) This also applies if they invoke CMS Subset from ISQL.
The following sections discuss the implications that the various types of application implementations have on database design.
When applications are being developed, not all of the data is already predefined. You will therefore need to set up your database to support both data that exists in a predefined state, and data that is still under development. For the latter, you should consider establishing both PUBLIC and PRIVATE dbspaces specifically defined for application development purposes.
Application developers and database designers will need their own PRIVATE dbspaces for prototyping data designs and functions on various data designs. These are better than PUBLIC dbspaces for this activity, because they provide an environment of less concurrency and no deadlocks. They also have the advantage of being user-controlled, so application developers need not worry about others altering the data in their test tables.
Such dbspaces must only be large enough to support sample data in the tables. Because they are used primarily for functional feasibility testing, they do not have to support large versions of the tables.
PUBLIC dbspaces are required to model the final database implementation: the final testing stages and performance testing of applications and data organizations. They would probably represent the actual production environment, as they allow a greater concurrency and are DBA-controlled. Tables stored here would hold a larger, more representative sampling of the data.
Queries and report writing also have unique database design requirements. In particular, the needs of query users for private storage of their data, queries, and routines must be considered.
Many query users will want to be able to store their own private data. To support this, you need to set up space in the database: how you do so will depend on how you want to control space usage and table creation. Some variations on this are described below.
You can enable query users to define and control their own data by giving them RESOURCE authority, which lets them create tables in the database. For more information see Granting Authorities. They will also need PRIVATE dbspaces to hold their tables. Users with RESOURCE authority can issue their own ACQUIRE DBSPACE statements; however, you will probably prefer to do this for them. (See Identifying Dbspace Requirements.)
If you do not want to give all query users RESOURCE authority, you could set up a PUBLIC dbspace that would support the data requirements of a whole group, and give just one user RESOURCE authority to handle the data requirements of the group.
If you need to tightly control or centralize control of database usage, you (or someone with DBA authority) can establish PRIVATE dbspaces for individual users and PUBLIC dbspaces for common data requirements, but create all tables yourself and restrict access to those tables to certain users only.
Users who do not have RESOURCE authority can still create tables in PRIVATE dbspaces that the DBA has acquired for them. This still allows the DBA to control how much space each user has in the database, but gives users the freedom to create whatever tables they choose within that space. This technique is sometimes called "create table authority."
Query users who want to develop their own ISQL routines will need to have a ROUTINE table somewhere in the database. Creating this table is typically done by the DBA when enrolling a new query user on the system. (See Adding a New User.)
Users who have their own PRIVATE dbspaces can create their own ROUTINE tables there. If a user's routines are to be shared by others, then this table should be created in a PUBLIC dbspace instead, and access to it established through views (rather than duplicating the table or having the other users qualify the name of the routine by a user ID).
If users are invoking ISQL to access a non-DB2 Server for VSE & VM application server and you require a master ISQL profile routine, then you must create a table called SQLDBA.ROUTINE and store the master routine in this table. See the DB2 Server for VM System Administration and DB2 Server for VSE System Administration manuals for details on setting up a routine table.
| Note: | Access to an application server using the DRDA protocol is only possible if the Distributed Relational Database Architecture (DRDA) facility has been installed on the application requester and if the application server supports IBM's implementation of the DRDA protocol. |
A final requirement for supporting a query/report writing environment is to define data for three dbspaces: "PUBLIC".ISQL, "PUBLIC".HELPTEXT, and "PUBLIC".SAMPLE.
This dbspace contains the SQLDBA."STORED QUERIES" table, which holds the queries stored by ISQL users. Because stored queries cannot be shared, users must have their own copy of any stored query they need to run. One or more standard stored queries may be established for each new user; in addition, some users may also have application programmer-developed stored queries established for them. Thus, this table may contain redundancy.
If an installation has many stored queries, the "PUBLIC".ISQL dbspace may run out of space. If this happens:
If the HELP text has been installed, this dbspace contains the SQLDBA.SYSTEXT1, SQLDBA.SYSTEXT2, and SQLDBA.SYSLANGUAGE tables, which hold the information displayed in response to an ISQL HELP command. If you plan to expand the text or topics covered in the HELP tables, you will need to increase the size of this dbspace. See Making the HELPTEXT Dbspace Larger.
This dbspace contains the sample tables provided with the DB2 Server for VSE & VM product: SQLDBA.EMPLOYEE, SQLDBA.DEPARTMENT, SQLDBA.PROJECT, SQLDBA.ACTIVITY, SQLDBA.EMP_ACT, SQLDBA.PROJ_ACT, SQLDBA.CL_SCHED and SQLDBA.IN_TRAY.
The considerations regarding the implementation of applications are discussed here.
The considerations pertinent to user-written application programs for the batch/ICCF environment and to DBS Utility applications are security, recovery and error handling.
DB2 Server for VSE data protection applies to programs written for batch and VSE/ICCF execution (and to the data itself). In particular, when a user preprocesses a program, the database manager checks the authority and privilege of that user on tables and views used in the program. When a user runs a preprocessed program, the database manager checks only for RUN privilege of that user on the program.
When a program is preprocessed, users with the appropriate data authority for the program functions must supply a user ID and password. Users are verified by the supplied password, and their authority is checked for each SQL request embedded in the program. On successful completion of the preprocessor job, a user becomes the owner of the application program, and can control who else can run it by issuing a GRANT RUN statement.
| Note: | In a batch/interactive environment, a GRANT statement is typically entered through a DBS Utility execution. For program execution, the batch and VSE/ICCF applications must be written to establish a user connection to the DB2 Server for VSE application server through the SQL CONNECT statement. This statement establishes the user of the program and checks that user's authority to run the program and to perform any interpretive SQL functions in the program. |
For example, security-sensitive applications can be written to require that the user ID and password of the program runner be supplied through control statements or terminal input at execution time. The programs should be written to read this information into the host program variables referenced in a DB2 Server for VSE CONNECT statement.
You can bypass this security facility by writing the application so that it supplies the user ID and password independent of the actual user of the application. If you do so, you must code the CONNECT statement in the application and grant RUN authority to the user IDs to be generated.
In general, you can use program authorization as a means of controlling access to data. If the end user of the application has access to the data only through specific application programs, the user can do only what the application is programmed to do.
All batch/ICCF programs should explicitly issue COMMIT WORK and ROLLBACK WORK statements as required, rather than relying on the implicit COMMIT and ROLLBACK functions of the database manager. The rules determining whether to do an implicit COMMIT WORK or an implicit ROLLBACK WORK are rather complex. By coding explicit COMMIT WORK and ROLLBACK WORK statements, you can determine what work is done by a batch application from the last statement completed.
In general, if a batch/ICCF application is terminated abnormally, the database manager backs out all uncommitted changes. If it terminates normally, the database manager commits changes not explicitly committed by the application. An application program can be coded to handle negative SQLCODEs by using SQL WHENEVER statements, as described in the DB2 Server for VSE & VM Application Programming manual.
The DBS Utility input must include an SQL CONNECT statement before any other SQL statement or UNLOAD, RELOAD or DATALOAD commands are issued. The only exception to this rule is when the DBS Utility is called by a user application that has already issued an SQL CONNECT statement.
A DBS input (SYSIPT) file can contain multiple SQL CONNECT statements. This capability can be used to write one DBS input file that performs operations for multiple users. The operations to be performed for any one user are preceded by an SQL CONNECT statement.
The DBS Utility applications can control commit processing through the appropriate use of the DBS SET AUTOCOMMIT command and SQL COMMIT WORK and ROLLBACK WORK statements. By setting AUTOCOMMIT ON, DBS will automatically issue an SQL COMMIT WORK after each SQL or DBS command (except for certain statements that imply commit processing is not appropriate, like ROLLBACK WORK). By setting AUTOCOMMIT OFF, no commit processing will be done unless explicitly requested by an SQL COMMIT WORK statement or when the input command file is exhausted.
For batch processing, you typically run with AUTOCOMMIT set OFF, so commit points are explicitly identified by SQL COMMIT WORK statements. This is the default for DBS processing.
When running DBS in an interactive fashion (under VSE/ICCF with /DATA INCON specified), you should run with AUTOCOMMIT set ON. If you run with AUTOCOMMIT set OFF, shared data is not available to other users while you are thinking about command responses or entering commands, unless the other users are using isolation level UR.
DBS terminates execution of commands in the input (SYSIPT) file and performs a ROLLBACK WORK if it encounters an error on any of the commands. However, DBS will read all the input records and provide diagnostics for the remaining commands. In addition, you can include SET ERRORMODE OFF commands to cause DBS to stop processing the input in error mode (that is, resume execution of commands in the input file).
The SET ERRORMODE OFF capability is useful for execution of independent command sequences in the same input file. Each independent sequence of commands would be preceded by a SET ERRORMODE OFF command.
Another use of the SET ERRORMODE command is when running DBS under VSE/ICCF in conversational mode (/DATA INCON). In this case, you should use the SET ERRORMODE CONTINUE command. If a normal SQL error is encountered on any command entered, the DBS utility processes subsequent commands from the terminal user. It goes into error mode processing only if the error is fatal. This saves the terminal user from having to enter SET ERRORMODE OFF every time a minor mistake is made.
Security design in an online (CICS) transaction processing environment should consider the facilities of the CICS subsystem as well as those offered by the DB2 Server for VSE application server. In particular, the CICS subsystem provides facilities for performing user verification (signon), and for controlling user authority to run CICS transactions. SQL programs written for execution in the CICS programming environment can be designed to take advantage of these facilities.
User identification and verification for CICS SQL transactions can be handled in one of the following ways:
The CICS SQL transactions do not have to contain SQL CONNECT statements. If a CONNECT statement is not present in the transaction, the |DB2 Server for VSE online support attempts to obtain the CICS signon userid using the EXEC CICS ASSIGN command. The user ID of the program user is assumed to be this signon ID.
If your CICS users do not go through a signon process for access to CICS transactions, user identification and verification can still be accomplished through the SQL CONNECT statement in the individual transaction programs.
However, the transaction would have to obtain a user ID and password in order to issue a CONNECT statement.
| Note: | This does not apply in a DRDA environment. |
For the online (CICS) environment, you can choose to run without requiring any user identification or verification, by treating all CICS users as though they had the same user ID and authority. To do this, you would identify the default CICS user ID when starting the DB2 online support (see CICS Transaction Environment).
| Note: | This does not apply in a DRDA environment. |
You can design each CICS transaction to handle user verification and identification differently. Some may require the user to sign on to the CICS subsystem, others may issue SQL CONNECT statement, and yet others may assume the default user ID for CICS users.
| Note: | In cases where the CICS subsystem does user verification or the user runs under the default user ID, it is not necessary to have the user defined to the DB2 Server for VSE application server through the GRANT statement (CONNECT authority). |
Application recovery processing for CICS SQL transactions is coordinated between the CICS subsystem and the DB2 Server for VSE database manager. In particular, a CICS SYNCPOINT request causes an SQL COMMIT WORK to be issued to commit table information as well as CICS information. Similarly, a CICS SYNCPOINT ROLLBACK request causes an SQL ROLLBACK WORK to be issued. The reverse is also true: a COMMIT WORK causes a CICS SYNCPOINT to be issued and an SQL ROLLBACK WORK causes a CICS SYNCPOINT ROLLBACK to be issued.
In addition, CICS end-of-task processing is coordinated with the DB2 Server for VSE database manager to assure that transaction processing is properly committed or rolled back, depending on the conditions under which the transaction ended.
For supporting recovery processing for CICS SQL transactions, the CICS subsystem must be generated with the Dynamic Transaction Backout Program (DBP parameter), and individual transactions must be installed with the CICS DTB=YES option.
Pseudoconversational transactions must not be run on the same terminal with ISQL while ISQL has "timed out".
You can load test data in any of these ways:
Live data can be unloaded and then reloaded back into the system, but directed at the test dbspace. The tables can be created new (using the NEW option of the RELOAD command); or, if the tables already exist, then all rows can be deleted and the unloaded data inserted using the PURGE option of the RELOAD command. If an application development environment exists where the test data is on a separate test database, then DBS UNLOAD/RELOAD can be used to load data from one database to another.
Live data can also be loaded into a table by using the INSERT with subselect:
INSERT INTO TESTTABLE
SELECT * FROM USERID.LIVETABLE
WHERE ...
This approach to loading test data has the advantage of using a WHERE clause for defining a sample from the live data rather than the entire table. An INSERT with subselect can be entered through ISQL, the DBS Utility, or an application program. An INSERT with subselect can be used to convert data from one data type to another; the specific limits on data type conversion depend on the number of conversions and the data types involved. Refer to the DB2 Server for VSE & VM Application Programming manual for the general restrictions on data type conversions.
The DBS Utility DATALOAD command may be used to input test data for new tables. The input to the DATALOAD command is from SYSIPT or sequential (SAM) files in VSE, from SYSIN or sequential (CMS) files in VM. A subset of all the data on the input sequential file can be loaded by using the "IF POS" clause of the DATALOAD command. For example, suppose that on an input sequential file containing customer information, the telephone number data is in positions 28-39 and positions 28-30 contain the area code. You could then load just the 555 area codes into the table TESTCUST by specifying the following DATALOAD command format:
DATALOAD TABLE (TESTCUST) IF POS (28-30)='555'
·
·
·
The test table would contain a subset of the actual data that the application will use.
You can get even more selectivity by using the DATAUNLOAD command to create the sequential file. This is especially useful if the data exists in tables, but not input files.
As the DATAUNLOAD command incorporates an SQL SELECT statement, you can be highly selective about what data you wish to unload. Furthermore, because the DATALOAD command can be used to reload the data, you can significantly restructure the data when you load it. That is, DATAUNLOAD/DATALOAD is not restricted to a table-to-table or dbspace-to-dbspace data movement. For example, you can unload data generated from a subquery, and then load only a portion of the result into a completely different table. This facility is useful for rapidly getting data into a new design prototype.
To simplify coding and testing of SQL statements that will eventually reference the live data, a developer may use the SYNONYM capability. Under the user ID established for a developer, synonyms would be defined so table references would translate to test tables when preprocessed under the developer's user ID.
For example, an application needs to be written that will access the PAYROLL table. The fully qualified table name is LOCALDBA.PAYROLL, having been created for the user ID LOCALDBA. A developer, with userid = DEV, has a temporary version of the payroll table called DEV.TESTPAY. Because the SQL statements refer to the table name PAYROLL, the developer creates the name PAYROLL as the synonym for TESTPAY:
CREATE SYNONYM PAYROLL FOR TESTPAY
Now all references to PAYROLL made from userid DEV translate to TESTPAY. When it comes time to switch to the live data, the program will be preprocessed under the userid of the creator of the PAYROLL table (LOCALDBA in this case), so that the program will access the PAYROLL table no matter who runs it.
| Note: | An exception to the above commands are applications that require Dynamic Statement Support (including Extended Dynamic Statements). For those dynamic statements, table references are translated based on the userid of the user that runs the program (the userid specified in the CONNECT statement). Execution of any test program against live data can be prevented by not granting run authority to anyone who does not have the appropriate synonyms defined. |
Before actually coding an application, the programmer may test/develop SQL statements to be embedded in the program by using ISQL against test data. The programmer would develop a set of SQL statements using the stored query facilities of ISQL. As each statement is formed, it would be run against the test data to verify expected results. Syntax and execution errors will be caught and error messages returned. The HELP facility of ISQL could be used to obtain detailed error descriptions and SQL statement descriptive information. For user logic errors on non-query statements (such as INSERT or UPDATE), the programmer can issue SELECT statements to inspect the effects of the tested statements.
To maintain a consistent state of the test database when using non-query statements, the programmer will want to issue SET AUTOCOMMIT OFF from the ISQL terminal, so that any changes that the test statements may make to the test database can be undone with a ROLLBACK WORK.
To place an SQL command in the stored queries table without executing it first, the programmer should use the ISQL HOLD and STORE commands under AUTOCOMMIT ON mode. For example:
HOLD DELETE FROM PAYROLL WHERE NAME = 'SMITH' STORE DELETE1
The HOLD command will place the command in the SQL command buffer of ISQL, but will not run it. Then the STORE command will place the contents of the SQL command buffer into the "STORED QUERIES" table. Once the command is in the "STORED QUERIES" table, the programmer can run it while controlling his own logical unit of work (under SET AUTOCOMMIT OFF), so that the changes done by the command can be rolled back.
As each command is corrected and verified, it can be stored away as parameterized stored SQL command in a ROUTINE table. The programmer would use stored command parameters where the program will have program variables. The commands can be placed in the ROUTINE table in the same logical order that they will be run in the application program. In this manner a prototype will be created that will demonstrate sample application usage. End users can then see the proposed system in operation before it is coded. Design flaws can be more easily corrected at this early phase.
| Note: | Stored queries and synonyms cannot be shared, but routines can be shared. You can run another user's routine if you have obtained the SELECT privilege (through a GRANT command) on that user's ROUTINE table. Care must be taken in running another user's routines however, because any stored SQL commands or synonyms used in a routine will not be recognized unless you have also defined them yourself. |
After debugging and testing the SQL commands on ISQL, the application programmer would then code the application. Having developed the source program with embedded SQL commands, the next step is to run the program through the appropriate DB2 Server for VSE & VM preprocessor. If the programmer is unsure of the SQL commands embedded in the program, he can run the preprocessor with the CHECK option. The SQL commands will be preprocessed and error messages will be output to SYSLST in VSE and SYSPRINT in VM, but a package is not created and no modified source will be produced. Running the preprocessor without the CHECK option will generate a package and the modified source to be used as input to the desired compiler.
After the program has been preprocessed and compiled, the final step in the testing cycle would be execution against the test data. To ensure a consistent test database the application programmer should place a ROLLBACK WORK statement in his application that will undo any changes that the program may make during execution before the program terminates. This ROLLBACK WORK statement may be left in the application for the first few runs on the live data. Once the program is operating correctly on the live data, the ROLLBACK WORK statement can be removed (or replaced with a COMMIT WORK statement).
Each query user should be given a unique user identifier and CONNECT authority on the DB2 Server for VSE & VM application server using GRANT statements, as described under Adding a New User. Multiple users can use the same DB2 Server for VSE & VM userid, but this can result in conflicts between the users' access to the system and to data.
ISQL users should be careful if there is more than one user using the same userid. In particular:
Applications that use multiple CMS Work Units can:
For more information on CMS Work Units, see the DB2 Server for VSE & VM Application Programming manual.
| Note: | Access to an application server that is not DB2 Server for VM is only possible if the Distributed Relational Database Architecture (DRDA) facility has been installed on the application requester and if the non-DB2 Server for VM application server supports IBM's implementation of the DRDA protocol. |
DB2 Server for VSE & VM users and programs are independent of the physical storage of data. This means that procedures and programs need not be changed when their information is updated or reorganized, and logical changes can be made to the data without requiring expensive rewrites, retraining, or reorganization of the supporting application system.
This data independence improves productivity, by enabling users and programs to concentrate on the application instead of on details such as how data is stored, which users share it, or what changes have been made to it. It also means that new applications may be written with little initial regard for performance considerations: much of the optimization is handled automatically, and user-directed optimization can be done later without significant effect on the applications using the data. In addition, one user may change the format or organization of some data with minimal effect on other users who share it.
The DB2 Server for VSE & VM product supports a powerful query capability, as well as an easy-to-learn interactive support system (ISQL). The DBA can use these functions to scan stored data to determine when reorganization of data is appropriate, decide how to logically organize the data, audit its consistency and accuracy, and assess the impact of changes.
Another way to examine data is through the catalog tables, which are internally updated as a result of many SQL statements. For example, a CREATE TABLE statement causes a new entry in the SYSTEM.SYSCATALOG table; each column in the new table results in an entry in SYSTEM.SYSCOLUMNS. Because the catalog tables are regular tables (with appropriate security protection), the SQL language examines them. DBAs can look at these tables to determine table sizes and statistics, what programs use particular tables or columns, the current data types of columns in a particular table, various security information, and many other things required for understanding the status and dependencies of the database.
Refer to the DB2 Server for VSE & VM SQL Reference manual for more information about the catalog tables along with examples of their use.
To see if a data design is meeting performance requirements, the DBA can use the EXPLAIN statement to analyze the structure and performance of frequently used SQL statements, and to determine whether any statements or the data they access should be redesigned. See the DB2 Server for VSE & VM Application Programming manual for a description of the EXPLAIN statement.
A wide range of conversions from one data type to another is supported. This means that, within reason, the data type or the size of a column may be changed without requiring changes to the accessing programs. Data is converted on input and output if the data types used in program variables do not match those defined for the stored data. Data conversions and their restrictions are shown below; explanatory notes follow.
Figure 43. Data Conversion Chart
| Source Data Type | Target Data Type | ||||||
|---|---|---|---|---|---|---|---|
| CHAR | DATE | DECIMAL | FLOAT- DOUBLE | FLOAT- SINGLE | GRAPHIC | INTEGER | |
| CHAR | YES3 | YES6 | NO | NO | NO | NO | NO |
| DATE | YES7 | YES | NO | NO | NO | NO | NO |
| DECIMAL | NO | NO | YES1,4 | YES13 | YES12,13 | NO | YES1,2 |
| FLOAT-DOUBLE | NO | NO | YES1,4,5 | YES | YES11 | NO | YES1,2 |
| FLOAT-SINGLE | NO | NO | YES1,4,5 | YES10 | YES | NO | YES1,2 |
| GRAPHIC | NO | NO | NO | NO | NO | YES3 | NO |
| INTEGER | NO | NO | YES1 | YES | YES12 | NO | YES |
| LONG VARCHAR | YES3 | NO | NO | NO | NO | NO | NO |
| LONG VARGRAPHIC | NO | NO | NO | NO | NO | YES3 | NO |
| SMALLINT | NO | NO | YES1 | YES | YES12 | NO | YES |
| TIME | YES7 | NO | NO | NO | NO | NO | NO |
| TIMESTAMP | YES7 | NO | NO | NO | NO | NO | NO |
| VARCHAR8 | YES3 | YES6 | NO | NO | NO | NO | NO |
| VARGRAPHIC9 | NO | NO | NO | NO | NO | YES3 | NO |
| Source Data Type | Target Data Type | ||||||
|---|---|---|---|---|---|---|---|
| LONG VARCHAR | LONG VAR- GRAPHIC | SMALL-INT | TIME | TIME- STAMP | VAR- CHAR8 | VAR- GRAPHIC9 | |
| CHAR | YES | NO | NO | YES6 | YES6 | YES3 | NO |
| DATE | NO | NO | NO | NO | NO | YES | NO |
| DECIMAL | NO | NO | YES1,2 | NO | NO | NO | NO |
| FLOAT-DOUBLE | NO | NO | YES1,2 | NO | NO | NO | NO |
| FLOAT-SINGLE | NO | NO | YES1,2 | NO | NO | NO | NO |
| GRAPHIC | NO | YES | NO | NO | NO | NO | YES3 |
| INTEGER | NO | NO | YES1 | NO | NO | NO | NO |
| LONG VARCHAR | YES | NO | NO | NO | NO | YES3 | NO |
| LONG VARGRAPHIC | NO | YES | NO | NO | NO | NO | YES3 |
| SMALLINT | NO | NO | YES | NO | NO | NO | NO |
| TIME | NO | NO | NO | YES | NO | YES7 | NO |
| TIMESTAMP | NO | NO | NO | NO | YES | YES7 | NO |
| VARCHAR8 | YES | NO | NO | YES6 | YES6 | YES3 | NO |
| VARGRAPHIC9 | NO | YES | NO | NO | NO | NO | YES3 |
Notes to Figure 43:
The following sections define the rules for arithmetic operations with the data types that are supported. Note the conditions under which overflow errors can occur.
A decimal number has a fixed number of places in total, and a fixed number of places in its fractional part (to the right of the decimal point). The total number of places is often called the precision, and the number of places in the fractional part scale. A decimal column is defined in a CREATE TABLE or ALTER TABLE statement as: DECIMAL (precision,scale).
The precision and scale of the decimal number resulting from an arithmetic operation on two numbers (operands) are determined by the following rules:
Binary integers defined as SMALLINT will be converted to DECIMAL(5,0), while those defined as INTEGER will be converted to DECIMAL(11,0). Integer constants will always be converted to DECIMAL (11,0). The result is a decimal number as specified below.
Table 27. Precision and Scale of Decimal Results
Assume the following notation:
| |
| Operation | Characteristics of the Result |
| Addition and Subtraction |
Precision: MIN(31,MAX(PA-SA,PB-SB)+MAX(SA,SB)) Scale: MAX(SA,SB) |
| Multiplication |
Precision: MIN(31,PA+PB) Scale: MIN(31,SA+SB) |
| Division |
Precision: 31 Scale: 31-PA+SA-SB (Scale must not be negative) |
If both operands are binary integers, the operation is performed in fixed binary. The result is in the INTEGER data type.
The result of a division operation is truncated. The result of a fixed binary operation must be within the range of the INTEGER data type. See Specifying Columns for the ranges of data types.
If either operand is a floating point number, both operands are converted to double-precision floating point numbers. The result depends on the data type of the target column or host variable. In the case of decimals, some accuracy may be lost.
If the target data type or host variable is single-precision floating point, the result is converted to single-precision floating point; otherwise, it is converted to double-precision floating point.
The result of a floating point operation must be within the range of the FLOAT data type. See Specifying Columns for the ranges of data types.
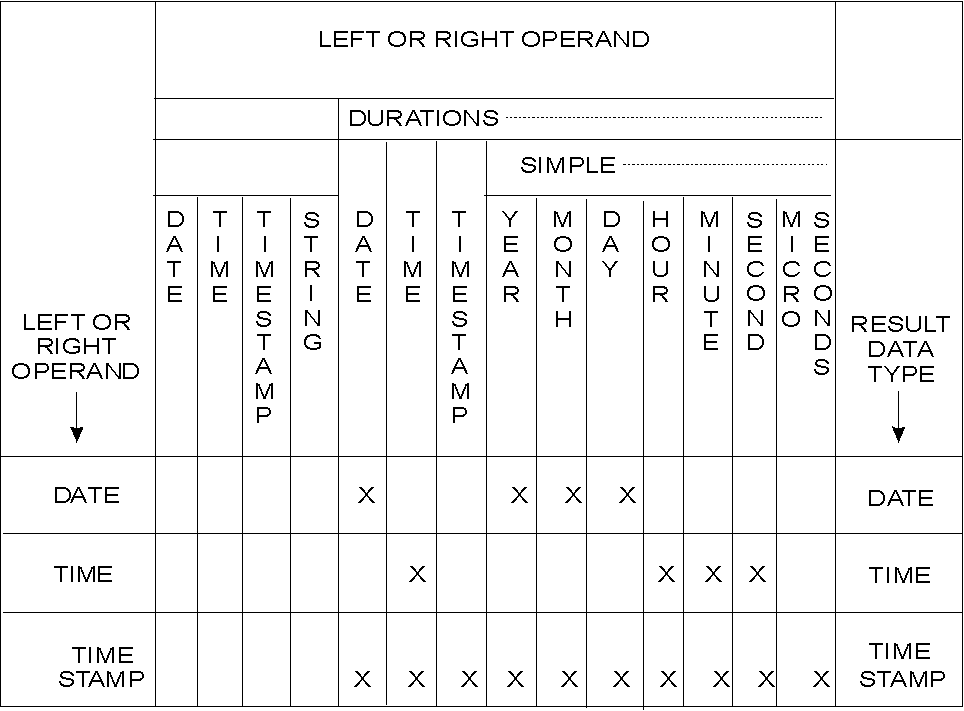
Date/time arithmetic involves intervals of time that are represented by numbers called durations. A duration is an interpretation of a number, not a new data type. The number may be a constant, a column name, a host variable, a function, or an expression. Numbers are interpreted as durations, only in certain contexts as defined below.
The duration types are:
A labeled duration is any number of years, months, days, hours, minutes, seconds, or microseconds. It is used in an expression that involves a date/time value, and consists of a numeric expression followed by one of YEAR(S), MONTH(S), DAY(S), HOUR(S), MINUTE(S), SECOND(S), or MICROSECOND(S). For example, in the expression START_DATE + 120 DAYS, the labeled duration is 120 DAYS. Fractional durations will be truncated to whole numbers (for example, 2.9 DAYS = 2 DAYS).
A date duration represents a number of years, months, and days, expressed as a DEC(8,0) number. It has the format yyyymmdd, where yyyy is the number of years, mm the number of months, and dd the number of days. An example of a date duration is the result of D1-D2, where D1 and D2 are dates.
A time duration represents a number of hours, minutes, and seconds, expressed as a DEC(6,0) number. It has the format hhmmss, where hh is the number of hours, mm the number of minutes, and ss the number of seconds. An example of a time duration is the result of T1-T2, where T1 and T2 are times.
A timestamp duration represents a number of years, months, days, hours, minutes, seconds, and microseconds, expressed as a DEC(20,6) number. It has the format yyyy-xx-dd-hh.mm.ss.zzzzzz, where yyyy, xx, dd, hh, mm, ss, and zzzzzz represent, respectively, the number of years, months, days, hours, minutes, seconds, and microseconds. An example of a timestamp duration is the result of TS1-TS2, where TS1 and TS2 are timestamps.
The only arithmetic operators that can be applied to date/time values are addition and subtraction. If a date/time value is the operand of addition, the other operand must be a duration.
A labeled duration can only be used as the operand of an arithmetic operator such that the other operand is a date/time value. For example, if D is a date and N and M are numbers, D + N DAYS + M MONTHS is a valid expression, but D + (N DAYS + M MONTHS) is not.
No automatic data conversion is provided among date/time data types. If an arithmetic operation is to be performed among different date/time values, the scalar functions should be used to convert them into the same data type. For example, if A is a TIMESTAMP column and B is a DATE column, the difference between the two in date duration can be obtained by DATE(A) - B. If you specify just A - B, an error will occur indicating incompatible types.
The specific rules for the use of the addition operator on date/time values are as follows:
The rules for the use of the subtraction operator on date/time values are not the same as for addition: first, because a date/time value cannot be subtracted from a duration, and second, because the operation of subtracting two date/time values is not the same as that of subtracting a duration from a date/time value. The rules are as follows:
The semantic rules for date, time, and timestamp arithmetic are discussed below. Since there is no established standard for date/time arithmetic, some of the operations are defined procedurally. These procedural definitions use some of the scalar functions.
Dates can be incremented, decremented, and subtracted. The operation of incrementing or decrementing a date by some number of days is well defined and can be verified by a calendar. The other operations are subject to peculiarities because not all months have the same number of days.
When two dates are subtracted, the result is a date duration that gives the number of years, months, and days between those dates. The data type of the result is DECIMAL(8,0).
In the following procedural description of the operation, the term "subtrahend" refers to the number to be subtracted, and "minuend" is the number that the subtrahend is subtracted from.
If DAY(subtrahend) is not greater than DAY(minuend), the day part of the result is equal to DAY(minuend) - DAY(subtrahend).
If DAY(subtrahend) is greater than DAY(minuend), the day part of the result is equal to N + DAY(minuend) - DAY(subtrahend), where N is the last day of MONTH(subtrahend). (For example, if MONTH(subtrahend) is 1, N is 31.) MONTH(subtrahend) is incremented by one.
If MONTH(subtrahend) is not greater than MONTH(minuend), the month part of the result is equal to MONTH(minuend) - MONTH(subtrahend).
If MONTH(subtrahend) is greater than MONTH(minuend), the month part of the result is equal to 12 + MONTH(minuend) - MONTH(subtrahend). YEAR(subtrahend) is incremented by one.
The year part of the result is equal to YEAR(minuend) - YEAR(subtrahend).
For example, the result of DATE('3/15/2000') - '12/31/1999' is 00000215 (a duration of 0 years, 2 months, and 15 days).
The result of adding a duration or subtracting it from a date is a date. The result must be within the range of dates.
When a labeled duration of years is added to or subtracted from a date, the result is a date (that is, the specified number of years before or after the date in the operation). Only years are counted. The month of the result is always the same as the month of the date in the operation. The day of the result is also the same as the day of the date in the operation, unless the result would be February 29 of a non-leap year, in which case the day part of the result is 28 and SQLWARN7 is set to W.
When a labeled duration of months is added to or subtracted from a date, the result is a date (that is, the specified number of months before or after the date in the operation). Only months (calendar pages) and years (if necessary) are counted. The day of the result is the same as the day of the date in the operation, unless the result would be an incorrect date, in which case the day part of the result is the last day of the month and SQLWARN7 is set to W.
When a labeled duration of days is added to or subtracted from a date, the result is a date (that is, the specified number of days before or after the date in the operation).
When a positive date duration is added to a date or a negative duration subtracted from it, the result is a date (that is, y years, m months, and d days after the date in the operation, where y, m, and d are the year, month, and day parts of the date duration). When a positive date duration is subtracted from a date or a negative duration added to it, the result is a date (that is, y years, m months, and d days before the date in the operation). The arithmetic is performed using the rules defined above, including the setting of SQLWARN7 whenever an end-of-month adjustment is performed. The date duration must be DEC(8,0).
Figure 44. Setting SQLWARN7 During Date Arithmetic. When incrementing or decrementing dates, SQLWARN7 is set when the resulting date is an incorrect date because of leap year or month difference, and a valid date is derived.
Let D1 be the DATE 1984-02-29, a leap year.
SQLWARN7
D1 + 1 DAY = 1984-03-01 ' '
D1 + 2 MONTHS = 1984-04-29 ' '
D1 + 1 YEAR = 1985-02-28 'W'
D1 + 4 YEARS = 1988-02-29 ' '
Let N be DEC(8,0) and set to 00010203.
D1 + N
= 1984-02-29 + 1 YEAR + 2 MONTHS + 3 DAYS
= 1985-02-28 + 2 MONTHS + 3 DAYS 'W'
= 1985-04-28 + 3 DAYS
= 1985-05-01
Let D2 be the DATE 1985-03-31.
SQLWARN7
D2 + 1 MONTH = 1985-04-30 'W'
D2 + 2 MONTHS = 1985-05-31 ' '
|
What does it mean to add a month to a given date? The rules defined above are based on the assumption that the result should be the same day of the next month. Thus, one month after January 1 is February 1, and one month after February 1 is March 1. But what is one month after January 31? This difficulty, which is the reason why certain contracts are always dated the first of the month, is resolved by the further assumption that the result should be the last day of February.
Thus, adding a month to a given date gives the same day of the next month unless the next month does not have such a day, in which case the result is the last day of that month. Similarly, one month from the last day of a month is not necessarily the last day of the next month. For example, one month from the last day of February is not the last day of March. In sum, "a date + a labeled duration of months - a labeled duration of months" is not necessarily equal to the original date.
The definition of the month does not permit a consistent system of date arithmetic. If this is a problem, you can avoid it by using days rather than months. For example, to increment the date "DATE3" by the difference between the dates "DATE1" and "DATE2", the expression "DATE (DAYS(DATE1) - DAYS(DATE2) + DAYS(DATE3))" will give an accurate result, whereas "DATE1 - DATE2 + DATE3" may not.
Times can be incremented, decremented, and subtracted. The only peculiarity is the modules of 24 hours. For example, adding any multiple of 24 hours to a time gives the same time. The exception is 00:00:00, where adding 24:00:00 becomes 24:00:00.
When two times are subtracted, the result is a time duration that gives the number of hours, minutes, and seconds between the two times. The data type of the result is DECIMAL(6,0).
In the following procedural description of the operation, the term "subtrahend" refers to the number to be subtracted, and "minuend" is the number that the subtrahend is subtracted from.
If SECOND(subtrahend) is not greater than SECOND(minuend), the seconds part of the result is equal to SECOND(minuend) - SECOND(subtrahend).
If SECOND(subtrahend) is greater than SECOND(minuend), the seconds part of the result is equal to 60 + SECOND(minuend) - SECOND(subtrahend). MINUTE(subtrahend) is incremented by one.
If MINUTE(subtrahend) is not greater than MINUTE(minuend), the minute part of the result is equal to MINUTE(minuend) - MINUTE(subtrahend).
If MINUTE(subtrahend) is greater than MINUTE(minuend), the minute part of the result is equal to 60 + MINUTE(minuend) - MINUTE(subtrahend). HOUR(subtrahend) is incremented by one.
The hour part of the result is equal to HOUR(minuend) - HOUR(subtrahend).
The result of adding a duration to a time or subtracting a duration from it is a time. In each of the following cases, any overflow or underflow of hours is discarded. Thus, the result is always within the range of a time.
When a labeled duration of hours is added to or subtracted from a time, the result is a time (that is, the specified number of hours before or after the time in the operation). Only hours are counted. Thus, the minute and second of the result are the same as the minute and second of the time in the operation.
When a labeled duration of minutes is added to or subtracted from a time, the result is a time (that is, the specified number of minutes before or after the time in the operation). Only minutes and hours (if necessary) are counted. Thus, the second of the result is the same as the second of the time in the operation.
When a labeled duration of seconds is added to or subtracted from a time, the result is a time (that is, the specified number of seconds before or after the time in the operation).
When a time duration is added to or subtracted from a time, the result is a time (that is h hours, m minutes, and s seconds before or after the time in the operation, where h, m, and s are the hour, minute, and second parts of the time duration). The time duration must be a DEC(6,0) value.
Timestamps can be incremented, decremented, and subtracted. The operations are a combination of the date arithmetic and time arithmetic defined above, except that any overflow or underflow of hours is reflected in the date part of the result.
When two timestamps are subtracted, the result is a timestamp duration that gives the number of years, months, days, hours, minutes, and seconds between the two timestamps. The data type of the result is DECIMAL(20,6).
In the following procedural description of the operation, the term "subtrahend" refers to the number to be subtracted, and "minuend" is the number that the subtrahend is subtracted from.
If MICROSECOND(subtrahend) is not greater than MICROSECOND(minuend), the microseconds part of the result is equal to MICROSECOND(minuend) - MICROSECOND(subtrahend).
If MICROSECOND(subtrahend) is greater than MICROSECOND(minuend), the seconds part of the result is equal to 1000000 + MICROSECOND(minuend) - MICROSECOND(subtrahend). SECOND(subtrahend) is incremented by one.
Second and minute are subtracted as specified in the rules for Subtracting Times.
If HOUR(subtrahend) is not greater than HOUR(minuend), the hour part of the result is equal to HOUR(minuend) - HOUR(subtrahend).
If HOUR(subtrahend) is greater than HOUR(minuend), the hour part of the result is equal to 24 + HOUR(minuend) - HOUR(subtrahend). DAY(subtrahend) is incremented by one.
Day, month, and year are subtracted as specified in the rules for Subtracting Dates.
The result of adding a duration to or subtracting it from a timestamp is a timestamp. In each of the following cases, date and time arithmetic are performed as defined above, except that an overflow or underflow of hours is carried into the date part of the result, which must be within the range of dates.
When a labeled duration of years is added to or subtracted from a timestamp, the result is a timestamp (that is, the specified number of years from the timestamp).
When a labeled duration of months is added to or subtracted from a timestamp, the result is a timestamp (that is, the specified number of months from the timestamp).
When a labeled duration of days is added to or subtracted from a timestamp, the result is a timestamp (that is, the specified number of days from the timestamp).
When a labeled duration of hours is added to or subtracted from a timestamp, the result is a timestamp (that is, the specified number of hours from the timestamp).
When a labeled duration of minutes is added to or subtracted from a timestamp, the result is a timestamp (that is, the specified number of minutes from the timestamp).
When a labeled duration of seconds is added to or subtracted from a timestamp, the result is a timestamp (that is, the specified number of seconds from the timestamp).
When a labeled duration of microseconds is added to or subtracted from a timestamp, the result is a timestamp (that is, the specified number of microseconds from the timestamp).
When a date duration is added to or subtracted from a timestamp, the result is a timestamp. The year, month, and day parts are the result of the arithmetic operation performed using the rules defined for incrementing or decrementing a date by a date duration. The hour, minute, second, and microsecond parts are the same as those of the timestamp in the operation.
When a time duration is added to or subtracted from a timestamp, the result is a timestamp. The time part is the result of the arithmetic operation performed using the rules defined above for incrementing or decrementing a time by a time duration, except that any overflow or underflow of hours is carried into the date part of the result. The microsecond part of the result is the same as the microsecond part of the timestamp in the operation.
When a timestamp duration is added to or subtracted from a timestamp, the result is a timestamp (that is, y years, x months, d days, h hours, m minutes, s seconds, and z microseconds before or after the time in the operation, where these values are the year, month, date, hour, minute, second and microsecond parts of the timestamp duration). Date and time arithmetic are performed as previously defined, except that an overflow or underflow of hours is carried into the date part of the result. Microseconds overflow into seconds. The timestamp duration must be DEC(20,6).
Figure 45 and Figure 46 summarize date/time addition and subtraction, respectively. The STRING column in both tables mean a character string in a valid date/time format.
DATE/TIME ADDITION = OPERAND + OPERAND
View figure.
An X denotes a valid date/time addition operation.
Figure 46. Date/Time Subtraction
DATE/TIME SUBTRACTION = MINUEND - SUBTRAHEND
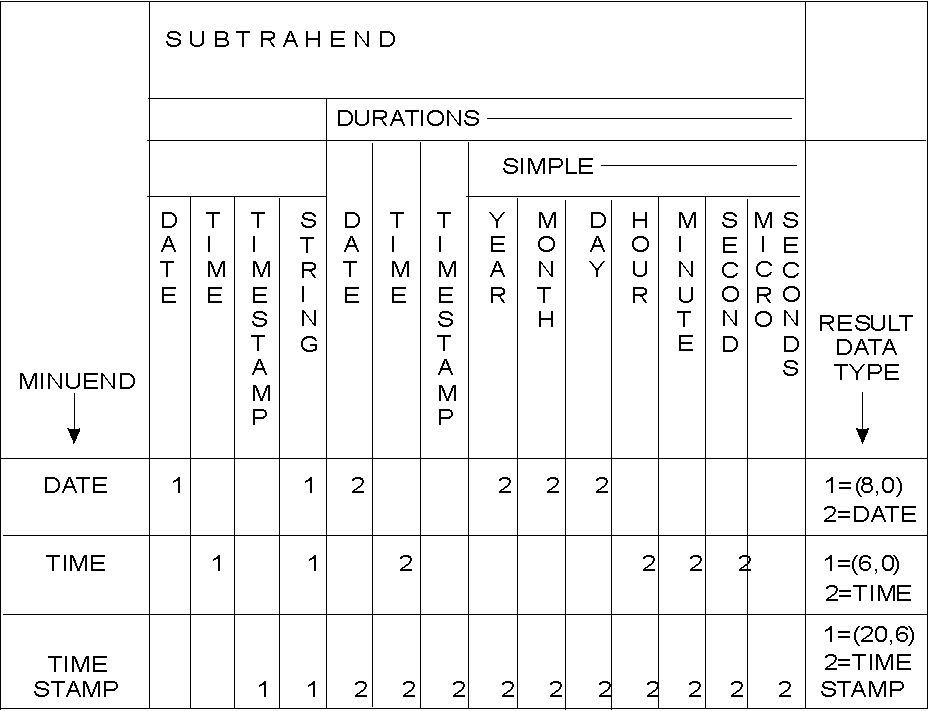 View figure.
View figure.
Both 1 and 2 denote a valid date/time subtraction operation. 1 means a result data type of DECIMAL(8,0), DECIMAL(6,0), or DECIMAL(20,6) that is deemed as a date duration, time duration, or timestamp duration, respectively. 2 means a result data type of date, time, or timestamp.
Users do not have to specify how data is to be accessed; only what data is to be accessed. Access path selection is done by the database manager, which determines which strategy will minimize the cost of processing a query. Cost is based on estimates of processor and I/O requirements. Users are not only free of such matters, they are not allowed to use any knowledge of such details. This allows the program to continue to operate when the underlying storage structures are changed.
Both logical and physical structural changes can be made to data without significant effect on users or their programs. The database manager permits flexibility in the binding of programs' data references to the data objects in the database. This significantly reduces the impact of changes.
The following sections note a few important considerations to reduce the effect of data restructuring.
When a program is preprocessed, references to nonexistent tables, views, or columns, or the use of statements that require a level of authority that has not yet been granted, do not prevent a package from being created; these conditions only cause warning messages. If the required authority or object exists when the referencing statement is processed, execution will proceed normally.
Although this design is very useful, it exacts a performance penalty. Preprocessing of such a program should be done again before the program is used extensively. By repeating the preprocessing step after acquiring the authority or having the required objects created, you avoid implicit, dynamic preprocessing of those statements that had unresolved objects or authority at the time of the original preprocessing.
When you add new columns to existing tables, referencing programs are normally not affected.
With SELECT statements, when selected columns are specifically named (rather than specifying SELECT *) or when a view is used, there is no effect on the program.
With INSERT statements, the effect of added columns on existing programs can be eliminated by specifically naming the target fields or by using a view, when the new columns permit NULL values. If the fields are not named, and if affected or new columns do not permit NULLS, the program must be changed and preprocessed again.
With the UPDATE statement, there is no effect because of changes, because individual fields are always specifically named.
With DELETE statements, the action applies to the row as a whole, so adding fields has no direct effect on existing programs.
When you add new fields, you may have to rewrite old programs to pick up the new function associated with those fields. However, with the above described restrictions, there need be no effect on old programs for existing function. Programs can continue to work normally through such changes until it is really necessary to update them.
To drop a column from a table, drop the table (DROP TABLE) and recreate it (CREATE TABLE) without that column. If the column dropped is not used by an existing program, dropping it in this manner does not functionally affect that program. The program is automatically re-preprocessed when it is next used.
| Note: | If the table has data in it, before dropping it, save the data. Either use the DBS Utility to unload the table to a tape or DASD SAM file; or create a new temporary table, and use an INSERT with Subselect statement to copy the data into it. Later, you can either use the DBS Utility to reload the data into the newly created table; or use an INSERT with Subselect statement to copy the data from the temporary table to the newly created table, then drop the temporary table. |
When you drop a table, all keys, indexes, and privileges are lost.
When a program is preprocessed, all of its dependencies (such as tables needed) are recorded in the SYSTEM.SYSUSAGE table. Then, whenever one of these objects is dropped, the SYSTEM.SYSUSAGE table is searched to check for dependencies; if the program depends on the object just dropped, it marks the entry invalid in the SYSTEM.SYSACCESS table against the package for that program, and marks any loaded copies of the package (in the cache) unusable.
The next time the package is invoked, it will automatically be re-preprocessed. If referenced objects have been reestablished properly, the preprocessing will succeed. The user will not be aware of the activity, except for a longer than usual time delay when the package is first invoked after the change.
Of course, when a program requires a field that is dropped, it can no longer function properly until it is brought current with the change. Because the program references the dropped field, if it is submitted for execution without being changed, the automatic re-preprocessing will fail and the submitter will be notified.
Adding an index to a table has no effect on users or programs that use the table. However, to make it possible to take advantage of potential performance improvements offered by the index, programs using it should be preprocessed again. (You should apply the UPDATE STATISTICS statement for the table after adding the index and before preprocessing the program again.) The preprocessing step enables the database manager to re-examine the possible access strategies, and possibly take advantage of the new index.
Indexes for tables used in programs are recorded in SYSTEM.SYSUSAGE in the same manner described above for tables. When an index is dropped, the same automatic re-preprocessing occurs for dependent programs, allowing adjustment of the access strategy to reflect the lost index. For a dropped index, there is no need for further action by the programmers who create the using programs, because the automatic re-preprocess activity handles required adjustments.
Data relationships are handled by keeping the data structures simple (see Step 7: Normalize Your Tables) and expressing the relationships in the accessing statements. If this is done properly, new relationships can be accomplished without changing existing programs or users. For example, new tables may be associated with old ones by way of joins; predicates may use fields from many tables, and new views may be added.
There is considerable flexibility allowed in adding or dropping referential constraints. If the structure of your data changes, you can drop the primary key of a table, and create a new primary key for it. For information on primary keys, see Step 4: Identify One or More Columns as a Primary Key. You can also add new foreign keys to accommodate changes in the structure of your data, and drop old ones when they are no longer used. For more information, see Step 6: Plan for Referential Integrity.
When referential constraints are changed or if keys are inactivated, application programs that access the affected tables will automatically be re-preprocessed and compiled.
Unique constraints are similar to primary keys, and are useful when uniqueness on more than one column is desired. You can drop the unique constraint of a table and create a new one, or add additional ones. For information on unique constraints, see Step 4: Identify One or More Columns as a Primary Key.
When unique constraints are dropped or inactivated, application programs that access the affected tables will automatically be re-preprocessed and compiled.
When new authorization is added, old programs are completely unaware of the change.
When the preprocessor encounters program dependencies on specific authorizations, these dependencies are recorded in the SYSTEM.SYSTABAUTH table as described above for dependent objects. When a program-dependent authorization is removed, the package associated with the program is marked invalid, and the automatic re-preprocessing occurs as described before. If proper authorization is re-acquired before the automatic re-preprocessing, the package is re-preprocessed successfully; otherwise, the invoker is notified of the problem and the re-preprocessing fails.
The preprocessor has an option called KEEP|REVOKE, which allows for either keeping or revoking previously granted RUN authority. It pertains to the version of the package that is produced by the new preprocessing step.
This design simplifies the effect of changes that require repeating the preprocessing step, by not having to repeat the associated authorization procedures. When an automatic re-preprocessing occurs, the KEEP option is implicitly in effect.
Because users are not affected by data sharing, new users can be added, data can be employed by different people in different ways, and previous uses can be discontinued without effect on current users or their programs.
The recovery facilities also offer a significant benefit for managing changes to applications. With these facilities, changes can be applied, examined, tested and then everything can be backed out with a ROLLBACK statement, and it will appear as if nothing happened.
With ISQL, you must run with AUTOCOMMIT off.
The DBA may ask hypothetical questions without disrupting live data. Answers for questions such as: "What if I change the supplier of part ZT33592 to improve the delivery time?" or "What is the effect on overall product cost?" may be very valuable and, because they impose no permanent changes on the database, may be made safely.