 View figure.
View figure.This chapter describes the conceptual process of database design. The implementation of the design, that is, the actual creation of a set of objects, is discussed in Chapter 2, Implementing Your Design.
The DB2 Server for VSE & VM database contains sample tables that are referenced throughout this book and are used to demonstrate various concepts and procedures.
Some basic terms for database design are defined below. There is no universally accepted terminology for database design; these terms may be used differently elsewhere.
Entities and properties are represented as columns, and occurrences are
represented as values in the columns, as shown in Table 1.
Table 1. Occurrences and Properties of an Entity
| ENTITY | PROPERTIES | |||
|---|---|---|---|---|
| Employee | EMPNO | JOB | BIRTHDATE | SALARY |
| Sally Kwan | 000030 | Manager | 1941-05-11 | 38250 |
| William Jones | 000210 | Designer | 1953-02-23 | 18270 |
To be effective, your database must be designed specifically to meet the data storage and retrieval needs of your organization.
The first step in designing an effective database is to identify the collection of information that it will contain. You must then organize this information into tables, with each column of a row related in some way to all other columns of that row. This approach will enable you to identify the relationships that exist between the different entities.
For example, the following data relationships are expressed in the sample tables:
Before you design your tables, you must understand entities and their
relationships. Table 2 shows an example.
Table 2. Relationships in the Sample Database
| ENTITY | RELATIONSHIP | ENTITY |
|---|---|---|
| Employees | are assigned to | departments |
| Employees | earn | money |
| Departments | report to | departments |
| Employees | work on | projects |
| Employees | manage | departments |
The relationship between the columns in a table is the same in each row of the table. For example, in Table 1, the relationship between each entry in the Employee column and its corresponding entry in the Salary column is the same, because the Salary column describes the amount the employee earns.
In a relational database, you can express several types of entity relationships. Consider the relationship between employees and departments. A given employee can work in only one department, so this relationship is single-valued for employees. On the other hand, one department can have many employees, so this relationship is multivalued for departments. Accordingly, this constitutes a one-to-many relationship. Relationships can be:
If each employee can belong to several departments, the employees/departments relationship would be many-to-many.
You must define separate tables for different types of relationships.
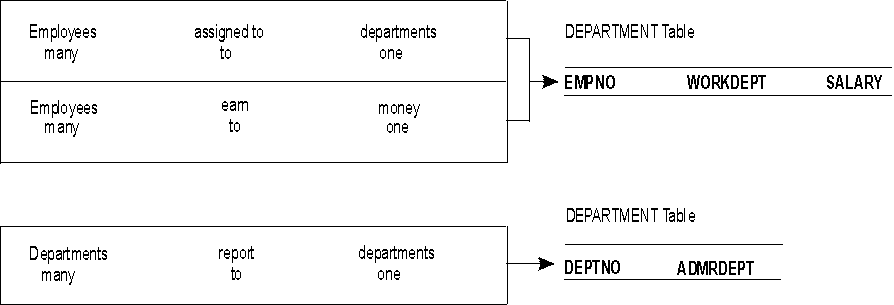
One-to-one relationships are single-valued in both directions. A manager manages one department; a department has only one manager. The questions "Who is the manager of Department C01?" and "What department does Sally Kwan manage?" both have single answers. The relationship could be assigned to either the department table or the employee table. Because all departments have managers, but not all employees are managers, it would be logical to add the manager to the department table, as shown in Figure 3.
Figure 3. Assigning One-to-One Facts to a Table
| View figure. |
To define tables for each one-to-many and many-to-one relationship, you must:
In Table 3, the "many" side of the first and second relationships
is "employees", so we defined an employee table (EMPLOYEE). In Figure 4, "departments" is the "many" side, so we defined a
department table (DEPARTMENT).
Table 3. Many-to-One Relationships
| ENTITY | RELATIONSHIP | ENTITY |
|---|---|---|
| 1. Employees | are assigned to | departments |
| 2. Employees | earn | money |
| 3. Departments | report to | (administrative) departments |
Figure 4. Assigning Many-to-One Facts to Tables
 View figure. View figure. |
A relationship that is multivalued in both directions is many-to-many. An employee might work on more than one project, and a project might have more than one employee assigned to it. The questions "What does Dolores Quintana work on?" and "Who works on project IF1000?" both yield multiple answers. A many-to-many relationship can be expressed in a table with a column for each entity ("employees" and "projects"), as shown in Figure 5.
Figure 5. Assigning Many-to-Many Facts to a Table
 View figure. View figure. |
Defining a column in a table consists of:
If every row in a table represents relationships for a unique entity, the table should have a primary key: one column (or a set of columns) that provides a unique identifier for the rows of the table. A unique index of the columns of the primary key is created when the primary key is created. You can create the primary key when you create the table using the CREATE TABLE statement (see Creating Tables) or, if the table already exists, by using the ALTER TABLE statement (see Altering the Design of a Table). A primary key must not contain a nullable column or a long field.
| Note: | Long fields include the following data types: VARCHAR(n) with n>254, VARGRAPHIC(n) with n>127, LONG VARCHAR, or LONG VARGRAPHIC. |
The primary keys of some of the sample tables are:
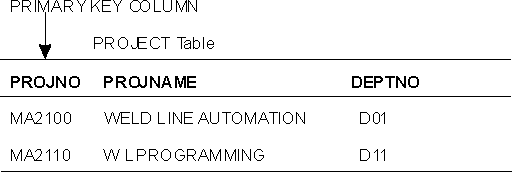
Figure 6 shows part of the PROJECT table with the primary key column indicated.
Figure 6. A Primary Key on a Table
 View figure. View figure. |
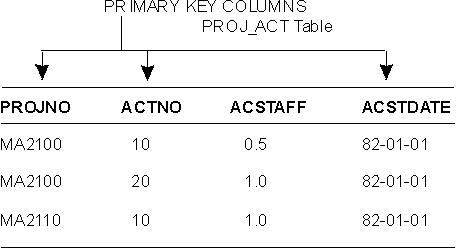
Figure 7 shows a primary key consisting of more than one column; it is a multicolumn key.
Figure 7. A Multicolumn Primary Key. The three columns PROJNO, ACTNO, and ACSTDATE are all parts of the primary key.
 View figure. View figure. |
If you have more than one candidate for a primary key, you can define a UNIQUE constraint on the column (or set of columns) that you do not select as the primary key. A column with a UNIQUE constraint is similar to a primary key in that a unique index on the column is created. It differs in that you can create more than one UNIQUE constraint on a table, and no foreign keys can reference a UNIQUE constraint (see Foreign Key).
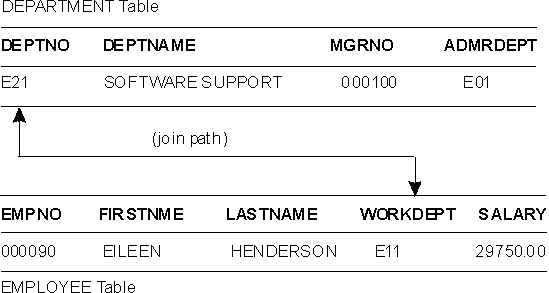
You can have more than one table describing properties of the same set of entities. For example, one table could give employees' job and salary information, as in the EMPLOYEE table, and another each employee's home address. To retrieve both sets of properties at once, you can join the tables on any set of matching columns, as shown in Figure 8. If there are two employees named Sally Kwan, a join on employee name may not match the correct rows. Similarly, if one person has more than one authorization ID, a join on ID may not produce the correct match. Thus, for the purpose of retrieving information about an entity from more than one table, an equal value in each of those tables should represent that entity. This type of join is an equijoin.
Figure 8 shows a join between the DEPARTMENT and EMPLOYEE tables on columns of department numbers.
Figure 8. A Join Path between Two Tables
 View figure. View figure. |
The connecting columns must be of the same data type. They can have different names (such as WORKDEPT and DEPTNO in Figure 8), or the same name (such as the two columns called DEPTNO in the DEPARTMENT and PROJECT tables). The latter case is illustrated in Figure 9.
Figure 9. A Join Path on Columns with the Same Name
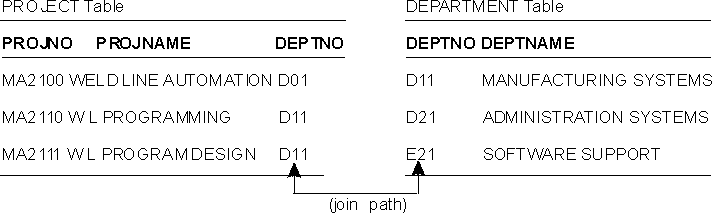 View figure. View figure. |
A table can serve as a complete list of all occurrences of a single entity. In the sample database, the EMPLOYEE table serves that purpose for employees: only the numbers that appear in this table are valid employee numbers. Similarly, the DEPARTMENT table provides a master list of all valid department numbers, and the PROJECT table provides a master list of valid projects. When a table refers to an entity for which there is a master list, it should identify an occurrence of the entity that appears in the master list; otherwise, either the reference is incorrect or the master list is incomplete.
When all references from one table to another are valid, this condition is called referential integrity. Having referential integrity does not necessarily mean the data is correct. That the EMPLOYEE table shows every employee assigned to a valid department number is one thing; whether it shows every employee in the correct department is quite another.
You must consider many different elements to ensure referential integrity. The concepts of a primary key and a unique constraint were described in Step 4: Identify One or More Columns as a Primary Key. Other elements to consider when dealing with referential integrity are described in the following sections.
A column or set of columns that refers to the primary key of another table is a foreign key. For example, the column Work Department (WORKDEPT) of the EMPLOYEE table is a foreign key; it refers to DEPTNO, the primary key of the DEPARTMENT table. The combination of the project number (PROJNO), activity number (ACTNO), and activity starting date (EMSTDATE) columns in the EMP_ACT table is a foreign key; it refers to the primary key of the PROJ_ACT table.
A referential constraint is a relationship between a primary key and a foreign key with certain deletion and update rules that define how the relationship is maintained. Refer to DELETE, INSERT, and UPDATE Considerations for information on deletion and update rules.
Establishing a referential constraint defines a relationship between two tables. The table containing the primary key is the parent table, and the one containing the foreign key is the dependent table. In a multilevel, hierarchical chain of dependent tables, a descendent table is any table below the top level. Such a table is a descendent of all the tables above it in the hierarchy.
A referential cycle is a set of referential constraints in which each table in the set is a descendent of itself. A table can be a parent of many tables, and it can also be a dependent or descendent of many parents.
A self-referencing table is one that contains both the primary key and the foreign key of a referential constraint. Conceptually, a self-referencing table is both the parent and the dependent table in a relationship. DB2 Server for VSE & VM does not support self-referencing.
When an employee retires, you remove that person's EMPLOYEE record. The deletion affects the information in the PROJECT, DEPARTMENT, and EMP_ACT tables. For any particular relationship, one of the following deletion rules is enforced:
You cannot delete any rows of the parent table that have dependent rows. In the DEPARTMENT-PROJECT relationship, using RESTRICT means that you cannot remove a department if any of its employees are assigned to a project.
When you delete a row of the parent table, the corresponding values of the foreign key in any dependent rows are set to NULL. This rule is used in the DEPARTMENT-EMPLOYEE relationship: when you delete a department record, the WORKDEPT column of dependent rows in the employee table is set to NULL, indicating that the employee is not assigned to a department.
When you delete a row of the parent table, any dependent rows in the dependent table are also deleted. This rule is useful when a row in the dependent table is useless without a row in the parent table. For example, if you delete an employee there is no reason to maintain the associated EMP_ACT record.
Multiple levels of CASCADE are supported; that is, a delete operation on a parent table deletes all dependent rows in its dependent tables if the dependent tables are enforced by the CASCADE delete rule of referential constraint. If any of these dependent tables are also parent tables, the delete rule of referential constraint in turn applies between them and their dependent tables. All applicable delete rules are used to determine the result of a delete operation. A delete operation is subject to rollback, if the parent row has a dependent row in a referential constraint with a delete rule of RESTRICT, or if the deletion cascades to any descendent that has a dependent row in a referential constraint with a delete rule of RESTRICT.
You may, at any time, delete rows from a dependent table without taking any action on the parent table. For example, you may no longer need EMP_ACT records after the project is completed. You can delete the record without affecting the EMPLOYEE or PROJ_ACT tables.
To ensure referential integrity, the table specified in the subquery must not be affected by the delete on the object table of the DELETE statement.
For example, if B is the object table of a DELETE statement, and A is a table that is referenced in the FROM clause of a subquery of that statement, then the following rules apply:
For more information on delete-connected tables, refer to Restrictions on Keys and Referential Constraints:.
You can insert a row at any time into a parent table without taking any action in the dependent table. For example, you can create a new department in the DEPARTMENT table without making any change to the EMPLOYEE table. For the insertion to be successful, the new primary key or unique key values must be unique.
You cannot insert a row into a dependent table unless a row in the parent table contains a primary key value equal to the foreign key value you want to insert. If a foreign key has a null value, it can be inserted into a dependent table, but no logical connection exists.
You cannot change a value in a primary key column if the associated row has a dependent row. For example, if a department number changes, the DEPTNO value in the DEPARTMENT table cannot be changed if there are employees in the EMPLOYEE table who are members of that department.
You cannot change a value in a foreign key column of a dependent table unless the new foreign key value already exists in the primary key of the parent table. For example, when an employee transfers from one department to another, the department number must change. The new value must be the number of an existing department, or null.
Normalization is the method of reducing data stored in tables so that the tables contain unique keys, each identifying a single entity. Each of these keys has an associated row of values that describes each entity. Complete normalization is not required for using the database manager.
The topic of normalizing tables draws much attention in database design. This section briefly reviews the rules for first, second, third, and fourth normal forms of tables, and describes some reasons why they should or should not be followed.
Any relational table satisfies the requirement of first normal form: at each row-and-column position in the table, there exists only one value, never a set of values.
A table is in second normal form if each column not in the key provides a fact that depends on the entire key.
Second normal form is violated when a non-key column is a fact about a subset of a composite key, as in Figure 10. An inventory table records quantities of specific parts stored at particular warehouses; its columns are shown below.
Figure 10. Key Violates Second Normal Form
 View figure. View figure. |
The key here consists of the PART and the WAREHOUSE columns together. Because the column WAREHOUSE-ADDRESS depends only on the value of WAREHOUSE, the table violates the rule for second normal form. The problems with this design are:
To satisfy second normal form, the information shown in Figure 10 must be in two tables, as in Figure 11.
Figure 11. Two Tables Satisfy Second Normal Form
 View figure. View figure. |
There is a performance disadvantage in having the two tables in second normal form, because programs that produce reports on the location of parts have to join both tables to retrieve the relevant information.
For further information on performance considerations, refer to Considerations for Normalization.
A table is in third normal form if each non-key column provides a fact that depends only on the key.
Third normal form is violated when a non-key column is a fact about another non-key column. For example, the first table in Figure 12 contains the columns EMPNO and WORKDEPT. Suppose a column DEPTNAME is added. The new column depends on WORKDEPT, whereas the primary key is the column EMPNO; thus, the table now violates third normal form.
Changing DEPTNAME for a single employee, John Parker, does not change the department name for other employees in that department. The inconsistency that results is shown in the updated version of the table in Figure 12.
Figure 12. Update of an Unnormalized Table. Information in the table has become inconsistent.
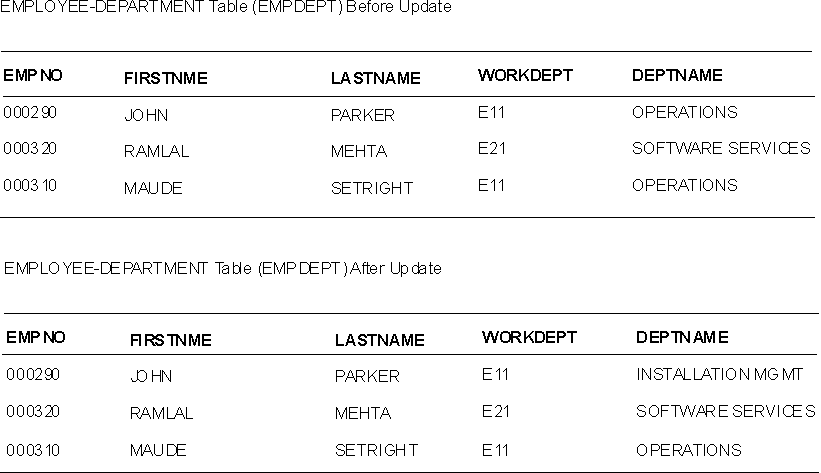 View figure. View figure. |
The table can be normalized by providing a new table, with columns for WORKDEPT and DEPTNAME. In that situation, updating a department name is much easier as it only has to be made to the new table. But an SQL query that shows the department name with the employee name is more complex to write: it requires joining the two tables. It also takes longer to run than the query of a single table. As well, the entire arrangement takes more storage space, because the WORKDEPT column must appear in both tables.
A table is in fourth normal form if no row contains two or more independent multivalued facts about an entity.
Consider facts about employees, skills, and languages, where an employee may have several skills and know several languages. There are two relationships, one between employees and skills, and one between employees and languages. A table is not in fourth normal form if it represents both relationships, as in Figure 13.
Figure 13. A Table That Violates Fourth Normal Form
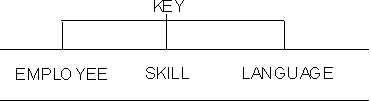 View figure. View figure. |
Instead, the relationships should be represented in two tables, as in Figure 14.
Figure 14. Tables in Fourth Normal Form
 View figure. View figure. |
If, however, the facts are interdependent (that is, the employee applies certain languages only to certain skills), then the table should not be split.
Any data can be put into fourth normal form. A good rule when designing a database is to arrange all data in tables in fourth normal form, and then decide whether the result will give you an acceptable level of performance. If it will not, you are at liberty to undo the normalization of your design.
Two types of access to DB2 Server for VSE & VM data are available. They are remote unit of work and distributed unit of work.
Remote unit of work, implemented in SQL/DS V3.3, for VM, and SQL/DS V3.4, for VSE, lets a user or application program on a Distributed Relational Database Architecture (DRDA) application requester to read or update data stored in a DB2 Server for VSE & VM DRDA application server. With remote unit of work, a user or application program can have many SQL statements within a unit of work; accessing one database management system with each SQL statement; and accessing one database management system within a unit of work.
Distributed unit of work, implemented in DB2 Server for VSE & VM Version 5 Release 1 lets a user or application program on a Distributed Relational Database Architecture (DRDA) application requester to read or update data stored in multiple locations, where the DB2 Server for VSE & VM DRDA application server is one of the multiple sites where data is read or updated within a single unit of work. With distributed unit of work, a user or application program can have many SQL statements within a unit of work; accessing one database management system with each SQL statement; and accessing many database management systems within a unit of work. Commit and rollback are coordinated at all locations so that if a failure occurs anywhere in the system, data integrity is preserved. This type of coordinated approach is called two phase commit processing and is done by a Sync Point Manager. In phase one, the coordinating RDBMS (generally the requesting RDBMS) polls each participating RDBMS to vote to commit or rollback the transaction. In phase two, the coordinator directs the RDBMSs to commit or rollback based on the preceeding vote.
Access to DB2 Server for VSE & VM DRDA application servers by DRDA application requesters is possible only if the DRDA facility is installed on the DB2 Server for VSE & VM application server.
DB2 Server for VM implements the application server and application requester support for DRDA remote unit of work, and the application server support for DRDA distributed unit of work. VM application requesters can participate in remote unit of work activity but cannot participate in distributed unit of work activity.
Access to non-DB2 Server for VM application servers by DB2 Server for VM application requester is possible only if the DRDA facility has been installed on the DB2 Server for VM application requester and if the non-DB2 Server for VM application servers support IBM's implementation of the DRDA protocol.
DB2 Server for VSE implements the application requester support for DRDA remote and distributed unit of work for CICS/VSE online applications. VSE online application requesters can participate in remote and distributed unit of work activity. With distributed unit of work, a CICS/VSE online application is limited to accessing a single DRDA application server within one LUW. However, it can update another CICS resource, in addition to the remote DRDA application server it is accessing, within one LUW, provided both the DRDA application server and the CICS resource participates in two-phase commits.
|DB2 Server for VSE implements the application requester support for |DRDA remote unit of work for Batch applications. VSE batch application |requesters can participate in remote unit of work activity, but cannot |participate in distributed unit of work activity.
Access to remote application servers by a DB2 Server for VSE application requester is possible only if the DRDA facility has been installed on the DB2 Server for VSE application requester and if the remote application server supports IBM's implementation of the DRDA protocol.
Designing a distributed database management system involves making decisions about where to put the data, how to manage security and accounting, and how to handle problems, backup, recovery, and change control.
For general guidance on making these decisions, refer to the following manuals:
The decision to access distributed data has implications for many activities: application programming, data recovery, and authorization. This section introduces some of these considerations. Refer to the appropriate manual for information on particular tasks.
The application requester is the component that accepts a request from an application and passes it to an application server.
The application server is the component that receives and processes requests issued by the application requester.
In VSE an application server is local if it resides in the same VSE machine as the DB2 Server for VSE application requester. This can also be a DB2 Server for VM application server accessed through VSE guest sharing. This DB2 Server for VM server can be either on the same VM machine as the VSE guest, or on another VM machine accessed remotely through AVS or TSAF. A remote application server can be a DB2 Server for VSE application server not residing in the same VSE machine as the application program connecting to it, or a non-DB2 Server for VSE application server.
In VM, a system is local if the application requester and the application server reside on the same processor, and is remote if they reside on different processors. Remote does not necessarily mean at a distance; the application server and application requester may be at the same user site.
Two relational database systems are like if both the application requester and the application server are the same product (for example, both are DB2 Server for VSE or both are DB2 Server for VM).
They are unlike if different products are involved (for example, a DB2 Server for VM application requester and a DB2 Server for VSE application server).
A DB2 Server for VM application requester can communicate with a like system, either local or remote, through the SQLDS protocol or the DRDA protocol. It can communicate with an unlike system through the DRDA protocol, if the Relational Database Management System (RDBMS) of the unlike system supports the protocol.
A DB2 Server for VSE application requester can communicate with a local DB2 Server for VSE application server through the SQLDS protocol |or a DB2 Server for VM application server which is accessed using |Guest Sharing through the SQLDS protocol. A DB2 Server for VSE application requester can communicate with a remote application server through the DRDA protocol, if the Relational Database Management System (RDMS) of the remote application server supports the protocol.
Several categories of application programming considerations are:
Data and statements are converted if the connected systems are using different coded character set identifiers (CCSIDs). For example, an SQL statement originating in an ASCII environment that is sent to an EBCDIC environment must be converted for the DB2 Server for VSE & VM application server to process it. This conversion ensures that the application server correctly interprets the statement and the data, and displays the results using the appropriate character sets. For more information on character conversion, refer to either the DB2 Server for VM System Administration or the DB2 Server for VSE System Administration manual.
It is important that the application server and application requester have the same CCSID value, unless there is a specific reason for them to be different. When the application server and application requester have different CCSID values, character conversion cannot be avoided. This conversion has an associated performance overhead, and causes performance degradation. For more information on performance, see the DB2 Server for VSE & VM Performance Tuning Handbook manual.
The limitations that exist for local multiple database applications apply to remote database applications with remote unit of work support. You cannot:
These limitations also apply to remote database applications with distributed unit of work support. One exception though, is that with DUOW you can access more than one application server in a single logical unit of work (LUW).
For the DRDA protocol restrictions, see the DB2 Server for VSE & VM SQL Reference manual.
An obvious consideration for an SQL query that is transmitted to a remote application server is that the query and its reply must both be transmitted over an SNA| or TCP/IP network, in VSE, or in VM, over a TSAF collection, VTAM network or TCP/IP network, conceivably as far as halfway around the world. This can increase the amount of processing and degrade the performance of the application in comparison with the same query run on your local application server. If the DRDA protocol is used, the DB2 Server for VSE & VM application requester has the option of increasing the block size used to return data. This can improve the performance of some applications. For more information in VM, see SQLINIT EXEC, in VSE, see Appendix E, SQLGLOB Parameters (VSE Only).
If the connected systems use different CCSIDs, performance can also be adversely affected, because additional processing is required to convert the data and statements.
Different relational database management systems use the SQL language, and strive to provide a consistent interface for applications. There are, however, some inconsistencies between systems. For example, the database manager does not support self-referencing constraints (a referential constraint in which both the primary key and the foreign key of the constraint are in the same table). On the other hand, it provides an EXPLAIN function, useful in tuning SQL statement performance, which is not provided by some RDBMS. These differences affect the portability of database designs and applications from system to system.
Several commands for monitoring the operations of the DB2 Server for VSE & VM application server provide detailed information to the database administrator about users and their systems. For more information on these commands, see the DB2 Server for VSE & VM Operation manual.
You cannot effectively administer a remote application server from your local system, and sometimes must coordinate operations by means external to your local system. Both the application requester and application server must be defined in an SNA | or TCP/IP network.
|In VSE using SNA networks, Transaction Program Names (TPNs) can be |used by remote application requesters to identify local DB2 Server for VSE |application servers to which they want to connect on the local VSE |system. These TPNs must be identified in the local DBNAME Directory and |mapped to the appropriate server APPLID. Likewise, Remote Transaction |Program Names (REMTPNs) can be used by the local system to identify the remote |DRDA application server to which the local DB2 Server for VSE online (CICS) |application requester wants to connect (Batch applications must use |TCP/IP). These REMTPNs must be identified in the local VSE DBNAME |Directory and mapped to the appropriate remote server SNA System ID |(SYSID).
|In VSE using TCP/IP networks, remote DRDA application requesters |must know the local VSE TCP/IP Server's IP Address (or Host Name) and the |local DB2 application server's Listener Port Number to access the local |DB2 Server for VSE DRDA application server. Likewise, local VSE DRDA |application requesters must know the remote DRDA application server's IP |address (or Host Name) and Listener Port Number, which are identified in the |local VSE DBNAME Directory.
|For additional information on the VSE DBNAME Directory, refer to the |DB2 Server for VSE System Administration manual.
|In VM, all access to remote application servers through VTAM or TCP/IP require a CMS Communication Directory for the application |requester. You must plan for creating and maintaining this directory on |each VM system where the application requester resides. See the |VM/ESA: Connectivity Planning, Administration, and Operation manual.
Similar considerations apply to users accessing other (non-DB2 Server for VSE & VM) application servers. Because each application server controls access to its own data, you must arrange to have valid user IDs on the other systems. As well, you must arrange for users to have proper authority and privileges on those application servers. Traces (used for problem determination) must also be coordinated with administrators at other sites, because traces must come from the system on which the data resides.
Although you can use the approaches previously described to distribute existing data, it is not a task to be undertaken lightly. Existing applications should only be distributed as part of an application redesign.
The best way to distribute data is the way used when the database was designed. However, the extent to which the preferred distribution method will affect existing applications must be considered in determining whether the preferred distribution should be implemented fully, partially, or at all.