This chapter explains the information that you need to help you design your replication environment: capacity planning, storage requirements, network requirements, deciding what to replicate, auditing requirements, staging data, and planning for migration.
The Capture program does not generally impact other applications and requires a minimum of central processing unit (CPU) or central processing complex (CPC) capacity. For example, you can schedule Capture for OS/390 at a lower priority than the application programs that update the source tables. In this case, the Capture program lags behind when CPU resource is constrained.
The Capture program does use CPU resources when it prunes the CD tables and UOW table, but you can defer this activity to reduce system impact.
The Apply program affects CPU usage depending on the frequency of replication, that is, on the currency requirement of the target database. Because the Apply program reads data from the source server and copies that data to the target server, it uses CPU resources on both systems.
In general, the DB2 Control Center and DJRA do not require many local CPU resources. However, when you generate the SQL for replication sources and subscription-set definitions, DB2 DataPropagator extensively searches the catalogs of the source server. And for large sites, these searches can have a noticeable CPU or database system impact.
Recommendations: Plan replication administration for times when impact to the source and target database systems is minimal. Use filtering to minimize the amount of data returned from the source server.
In addition to the storage required for DB2, replication requires storage for:
If there is insufficient disk space for the spill files, the Apply program terminates. If you specify that Apply for OS/390 should use memory, but there is not enough memory for the spill files, the Apply program abends; in this case, specify that the Apply program should use disk space and restart it. For more information about spill files, see Spill files.
All of the sizes given in the following sections are estimates only. To prepare and design a production-ready system, you must also account for such things as failure prevention. For example, the holding period of data (discussed in Target tables and control tables) might need to be increased to account for potential line outage.
If storage estimates seem unreasonably high, reexamine the frequency interval of the Apply program (how often your subscriptions run) and pruning. Trade-offs frequently must be considered between storage usage, capacity for failure tolerance, and CPU overhead.
Before you can replicate a table, you must create it (or alter it) with the DATA CAPTURE CHANGES keywords. One of the effects of these keywords is that DB2 logs full-row images for each UPDATE statement. For a replica table (in an update-anywhere scenario), DB2 also logs the before-images for each update to the table. Another increase to the log or journal volume comes from DB2's logging insertions to and deletions from the unit-of-work (UOW) and change data (CD) tables.
Although estimating the increase in the log or journal volume is not easy, in general you will need an additional three times the current log volume for all tables involved in replication.
To make a more accurate estimate, you must have detailed knowledge of the updating application and the replication requirements. For example, if an updating application typically updates 60% of the columns in a table, the replication requirements could cause the log records to grow by more than half compared to a similar table that is not replicated. One of the replication requirements that adds the most to the log is the capturing of before- and after-images (as in the case of update-anywhere replication scenarios). One way to reduce the log volume is to reduce the number of columns defined for the replication source.
In addition to logging for the source database, there is also logging for the target database, where the rows are applied. Because the Apply program does not issue interim checkpoints, you should estimate the maximum amount of data that the Apply program will process in one time interval and adjust the log space (or the space for the current receiver for AS/400) to accommodate that amount of data.
For VM and VSE, when the active log is full, DB2 archives its contents. For AS/400, when the current receiver is full, the system switches to a new one; you can optionally save and delete old ones no longer needed for replication. When a system handles a large number of transactions, the Capture program can occasionally lag behind. If the log is too small, some of the log records could be archived before they are captured. Capture for VSE and VM running with DB2 for VSE & VM cannot recover archived log records. 13
For DB2 for VSE & VM, ensure that your log is large enough to handle at least 24 hours of transaction data. For DB2 for AS/400, ensure that the current receiver is large enough to handle at least 24 hours of data.
The space required for a target table is usually no greater than that of the source table (or tables), but can be much larger if the target table is denormalized or includes before images (in addition to after-images) or history data. The following also affect the space required for a target table: the number of columns replicated, the data type of columns replicated, any row subsets defined for the subscription-set member, and data transformations performed during replication.
The CD tables and the UOW table also affect the disk space required for a source database. The space required for the replication control tables is generally small because each requires only a few rows.
The CD tables grow in size according to the amount of data replicated until the Capture program prunes them. To estimate the space required for the CD tables, first determine how long you want to keep the data before pruning it, then specify how often the Capture program should prune these tables or how often you issue the prune command. To determine the minimum size for the CD table, use the following formula:
minimum_CD_size = ( (21 bytes) + sum(length of all registered columns) ) * (number of inserts, updates, and deletes to source table) * (exception factor)
When calculating the number of bytes of data replicated, you need to include 21 bytes for overhead data added to the CD tables by the Capture program. In the formula, determine the number of inserts, updates, and deletes to the source table within the interval between capturing and pruning of data. The exception factor allows for such things as network failures or other failures that prevent the Apply program from replicating data. Use a value of 2 initially, then refine the value based on the performance of your replication environment.
Example: If the Capture program prunes applied rows from the CD table once daily, your interval is 24 hours. If the rows in the CD table are 100 bytes long (plus the 21 bytes for overhead), and 100,000 updates are applied during a 24-hour period, the storage required for the CD table is about 12 MB.
The maximum size of a CD table is dependent on the maximum number of
columns and maximum size of a row allowed by DB2 for a particular
platform. Table 4 shows how to calculate the maximum size for a CD
table. For replica tables, you must divide the maximum number of
columns and maximum row length by two, because the CD table for a replica
table includes columns for before images.
Table 4. Calculating maximum size for a CD table
| The value maxCols represents the maximum number of columns allowed by DB2 for a table; the value maxLength represents the maximum row length allowed by DB2. | ||
| For read-only target tables | For read-write (replica) target tables | |
|---|---|---|
| Number of columns | maxCols - 3 columns | (maxCols - 3 columns) / 2 |
| Row length | maxLength - 21 bytes | (maxLength - 21 bytes) / 2 |
The UOW table grows and shrinks based on the number of rows inserted in a particular time interval (the number of commits issued within that interval by transactions that update source tables or by Capture for AS/400). You should initially overestimate the size required and monitor the space actually used to determine if any space can be recovered. The size of each row in the UOW table is fixed at 79 bytes (except for DB2 for AS/400, where it is 109 bytes). For a first approximation of the space needed for the UOW table, multiply 79 bytes (or 109 bytes) by the number of updates applied during a 2-hour period. Use a formula similar to the one given above for CD tables to obtain a better estimate for the space needed for the UOW table. For more information, see Unit-of-work table.
The Apply program stores updates to target tables in temporary files called spill files. 14 These files hold the updates until the Apply program applies them to the target tables. The Apply program uses multiple spill files for subscription sets with multiple subscription-set members: one spill file for each target table. The Apply program stores the spill file on disk for every operating-system environment, but Apply for OS/390 can use virtual memory instead. Unless you have virtual memory constraints, store the spill files in virtual memory rather than disk.
The size of the spill file is equal to the size of the data selected for replication during each replication interval. You can estimate the size of the spill file by comparing the frequency interval (or data-blocking interval; see Data blocking for large volumes of changes) planned for the Apply program with the volume of changes in that same time period (or in a peak period of change). The spill file's row size is the target row size, including any DB2 DataPropagator overhead columns. This row size is not in DB2 packed internal format, but is in expanded, interpreted character format (as fetched from the SELECT). The row also includes a row length and null terminators on individual column strings.
Example: If change volume peaks at 12,000 updates per hour and the Apply program frequency is planned for one-hour intervals, the spill file must hold one-hour's worth of updates, or 12,000 updates. If each update represents 100 bytes of data, the spill file will be about 1.2 MB.
This section describes connectivity requirements, discusses where to run the Apply program (using the push or pull configuration), and describes how data blocking can improve performance.
Because data replication usually involves physically separate databases, connectivity is important to consider during the planning stages. The workstation that runs the DB2 Control Center or DJRA must be able to connect to the control, source, and target server databases to perform their tasks. And the Apply program must be able to connect to the control, source, and target server databases.
When the databases are connected to a network, connectivity varies according to the platforms being connected:
If you use password verification for DB2 for OS/390, use Data Communication Service by adding DCS to the CATALOG DB statement. If you connect using SNA, add SECURITY PGM to the CATALOG APPC NODE statement. However, if you connect using TCP/IP, there is no equivalent security keyword for the CATALOG TCPIP NODE statement.
If your replication design involves staging data at a server that is different from the source database, you must carefully consider the communications between the various servers. For example, in an occasionally-connected replication scenario between DB2 Universal Database running on Windows 95 on a laptop PC and DB2 for OS/390, a good connectivity scenario might be for the Windows 95 PC to dial a local server (for example, an AIX server with DB2 Universal Database Enterprise Edition) using TCP/IP over a modem. The AIX workstation then connects to DB2 for OS/390 to fulfill the request from the Windows 95 machine.
Be sure to limit the layers of emulation, LAN bridges, and router links required, because these can all affect replication performance.
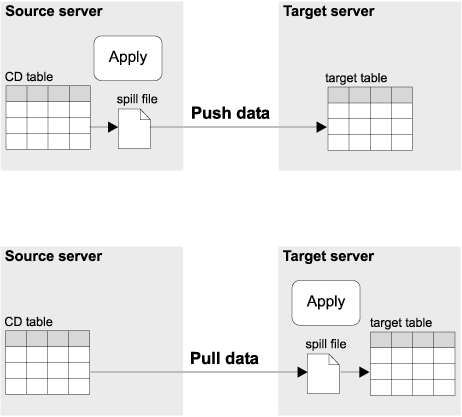
You can run the Apply program at the source server or at the target server. When the Apply program runs at the source server, you have a push configuration: the Apply program pushes updates from the source server to the target server. When the Apply program runs at the target server, you have a pull configuration: the Apply program pulls updates from the source server to the target server.
The Apply program can run in either or both configurations at the same time: it can push updates for some subscription sets and pull updates for others.
If the target table is in a non-IBM database, the Apply program connects to a DB2 DataJoiner database (with DB2 DataJoiner connected to the non-IBM database) and applies the changes to the target table using DB2 DataJoiner nicknames. In this case, the Apply program pushes updates from the DB2 DataJoiner source server to the target server or pulls updates from the DB2 DataJoiner source server to the target server. The Apply program cannot push or pull directly from the non-IBM server.
Figure 16 shows the differences between the push and pull configurations.
Figure 16. Push versus pull configuration
|
In the push configuration, the Apply program connects to the local source server (or to a DB2 DataJoiner source server for non-IBM sources) and retrieves the data. Then, it connects to the remote target server and pushes the updates to the target table. The Apply program pushes the updates row by row, and cannot use DB2's block-fetch capability to improve network efficiency.
In the pull configuration, the Apply program connects to the remote source server (or to a DB2 DataJoiner source server for non-IBM sources) to retrieve the data. DB2 can use block fetch to retrieve the data across the network efficiently. After all data is retrieved, the Apply program connects to the local target server and applies the changes to the target table.
Generally, a pull configuration performs better than a push configuration because it allows more efficient use of the network. However, under the following circumstances a push configuration is a better choice:
To set up a push or pull configuration you need only to decide where to run the Apply program. DB2 DataPropagator, the DB2 Control Center, and DJRA recognize both configurations.
Replication subscriptions that replicate large blocks of changes in one Apply cycle can cause the spill files or log (for the target database) to overflow. For example, batch-Apply scenarios can produce a large backlog of enqueued transactions that need to be replicated. Or, an extended outage of the network can cause a large block of data to accumulate in the CD tables, which can cause spill-file overflows.
Use the Data Blocking page of the Subscription Timing notebook in the DB2 Control Center or the Blocking factor field of the Create Empty Subscription Sets window in DJRA to specify how many minutes worth of change data the Apply program can replicate during a subscription cycle. The number of minutes that you specify determines the size of the data block. 15 This value is stored in the MAX_SYNCH_MINUTES column of the Subscription set table. If the accumulation of change data is greater than the size of the data block, the Apply program converts a single subscription cycle into many mini-cycles, reducing the backlog to manageable pieces. It also retries any unsuccessful mini-cycles and will reduce the size of the data block to match available system resources. If replication fails during a mini-cycle, the Apply program retries the subscription set from the last successful mini-cycle. Figure 17 shows how the changed data is broken down into subsets of changes.
Figure 17. Data blocking. You can reduce the amount of network traffic by specifying a data-blocking value.
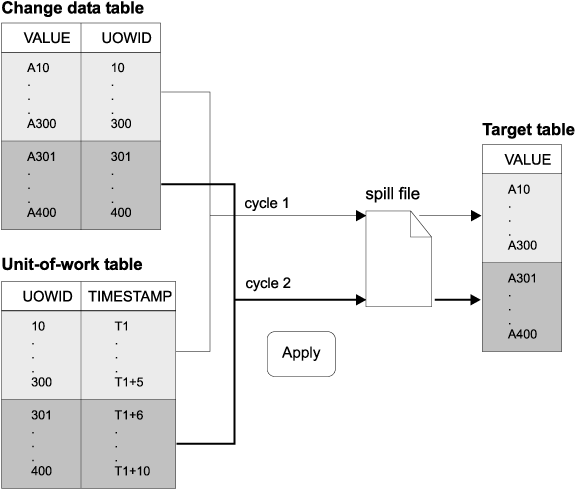 |
By default, the Apply program uses no data blocking, that is, it copies all available committed data that has been captured. If you set a data-blocking value, the number of minutes that you set should be small enough so that all transactions for the subscription set that occur during the interval can be copied without causing the spill files or log to overflow. For AS/400, ensure that the total amount of data to be replicated during the interval does not exceed 4 MB.
Restrictions:
As part of planning for replication, you need to consider how the data will be used at the target site. Often, the source data will need to be subsetted, transformed, or enhanced for decision-support or data-warehousing applications. This section sorts these requirements into those that are easily fulfilled by using the DB2 Control Center or DJRA, and those that require direct manipulation of the control tables.
The Control Center and DJRA support the following data manipulations:
The following sections describe the data manipulations that you can perform using the Control Center or DJRA. This chapter also describes replicating large-object (LOB) data, limits for column names for before-image data, and data-type restrictions.
IBM Replication supports both column (vertical) and row (horizontal) subsetting of the source table. This means that you can specify that only a subset of the source table columns and rows be replicated to the target table, rather than all of the columns and rows:
You can define column subsetting at one of two times:
Select only those columns that you want to make available for replication to a target table. Because CD tables must contain sufficient key data for point-in-time copies, you must include primary-key columns in your subset. The columns that you do not select will not be available for replication to any target table.
For the Control Center, use the advanced subscription options to select only those columns that you want to replicate to the target table. For DJRA, you can select the columns when you add members to the subscription set. The columns that you do not select are still available for other subscription sets, but are not included for the current subscription set.
Recommendation: When you define a replication source, select all columns (that is, do not subset any of them). Create your column subsets when you define subscription sets. By defining your column subsets in the subscription sets rather than in the replication sources, you will not have to redefine your replication sources if your subscription requirements change.
Use the advanced subscription options to define a WHERE clause when you define the subscription. All target table types support row subsetting.
If the primary key values of the target table will be updated, or the table (or view) contains a logical partitioning column that will be updated, you must specify replication logical-partitioning-key support when you define the replication source. Replication logical-partitioning-key support performs an UPDATE as a DELETE followed by an INSERT. See Enabling replication logical-partitioning-key support for more information.
Join views fill many requirements, both for denormalizing (restructuring) copies in data-warehouse scenarios, which enables simpler queries of copied data, and also for addressing the routing problem, sometimes called the database partitioning problem in distributed computing scenarios. 16 Views are also useful when you need to specify predicates for a row subset that exceed 512 bytes (the capacity of the PREDICATES column of the subscription-targets-member control table). Thus, you can choose to manage your subset predicates using views rather than as part of the subscription-set definition.
To define a join view as a replication source using the Control Center, first define all tables that participate in the join as replication sources (you do not need to define subscriptions for them). To define a join view as a replication source using DJRA, you can use existing views or you can define a join view that includes tables that are not defined as replication sources. You can use the Control Center or DJRA to define the view as a replication source; see Defining views as replication sources. If the replication sources defined in the join have CD or CCD tables, the Control Center or DJRA creates a CD view from the replication sources' CD tables.
IBM Replication supports the following types of view definitions:
Only views of tables that reside within DB2 databases are supported. Views of tables that are stored on Oracle, Microsoft SQL Server, Sybase, Sybase SQL Anywhere, Informix, or Teradata are not supported.
When defining DB2 views as a replication source, create them using a correlation ID.
Tip: If you define a view that includes two or more source tables as a replication source, also define a CCD table for one of the source tables in the join. This CCD table should be condensed and non-complete (or it can be complete) and should be located on the target server. A view that includes more than two source tables can be subject to the problem of "double deletes" which DB2 DataPropagator cannot replicate.
For example, if you define a view that contains the CUSTOMERS table and the CONTRACTS table, and if you delete a row from the CUSTOMERS table and also delete the corresponding row (from the join point of view) from the CONTRACTS table during the same replication cycle, you have a double delete. The problem is that, because the row was deleted from the two source tables of the join, the row does not appear in the views (neither base views or CD-table views), and thus the double-delete cannot be replicated.
Defining a condensed and non-complete CCD table for one of the source tables in the join solves this problem because you can use the IBMSNAP_OPERATION column of this CCD table to detect the deletes. You can add an SQL statement to the definition of the subscription set that should run after the subscription cycle. This SQL statement removes all the rows from the target table for which the IBMSNAP_OPERATION is equal to "D" in the CCD table.
You can define both before and after images in your replication sources and subscriptions. A before-image column is a copy of a column before it is updated, and an after-image column is a copy of a column after it is updated. DB2 logs both the before-image and after-image columns of a table for each change to that table. Replicating before images is required for update-anywhere scenarios when you define the replica with standard or enhanced conflict detection; in this case, the before images provide the required information for automatic compensation of rejected transactions. Replicating before images can also be useful for auditing purposes.
The before and after images have different values for different actions performed against the target tables, as shown below:
When you enable logical-partitioning key support, the before-image column appears in the deleted column and the after-image column appears in the inserted column. See Enabling replication logical-partitioning-key support for more information.
Before images do not make sense for base aggregate target-table types (there is no before image for computed columns). All other target-table types can make use of before-image columns.
Restriction: For columns that have a before-image defined, DB2 DataPropagator limits column names to 17 characters. Because DB2 DataPropagator adds a before-image column identifier (usually X) to target tables and because you must ensure that each column name is unique, you cannot use longer column names for those tables you replicate. For tables you do not plan to replicate, you can use longer column names, but consider using 17-character names in case you might want to replicate these tables in the future. For tables in DB2 for OS/390, you can use 18-character column names, but DB2 DataPropagator will replace the 18th character with the before-image column identifier in target tables, so you must ensure that the first 17 characters of the name are unique.
You can rename columns for point-in-time and user-copy target-table types. For other table types, you must define views in order to rename columns.
Using SQL, you can derive new columns from existing source columns. For aggregate target-table types, you can define new columns by using aggregate functions such as COUNT or SUM. For other table types, you can define new columns using SQL expressions.
You can also create computed columns by referring to user-defined functions when you create a view that will be used a replication source.
You can define run-time processing statements using SQL statements or stored procedures that can run before or after the Apply program processes a subscription set. Such statements can be useful for pruning CCD tables and controlling the sequence in which subscription sets are processed. You can run the run-time processing statements at the source server before a subscription set is processed, or at both the source and target servers before or after a subscription set is processed. For example, you can execute SQL statements before retrieving the data, after replicating it to the target tables, or both.
Stored procedures use the SQL CALL statement without parameters. The procedure name must be 18 characters or less in length (for AS/400, the maximum is 128). If the source table is in a non-IBM database, DB2 DataJoiner processes the SQL statements. The run-time procedures of each type are executed together as a single transaction. You can also define acceptable SQLSTATEs for each statement.
Depending on the DB2 platform, the SQL before and after processing statements can perform other processing, such as calling stored procedures.
DB2 Universal Database supports large object (LOB) data types, which include: binary LOB (BLOB), character LOB (CLOB), and double-byte character LOB (DBCLOB). This section refers to all of these types as LOB data.
The Capture program reads the LOB descriptor to determine if any data in the LOB column has changed and thus should be replicated, but does not copy the LOB data to the CD tables. When a LOB column changes, the Capture program sets an indicator in the CD tables. When the Apply program reads this indicator, it then copies the entire LOB column (not just the changed portions of LOB columns) directly from the source table to the target table.
To allow the Capture program to detect changes to LOB data, you must include the DATA CAPTURE CHANGES keywords when you create (or alter) the source table.
Because a LOB column can contain up to two gigabytes of data, you must ensure that you have sufficient network bandwidth for the Apply program. Likewise, your target tables must have sufficient disk space to accommodate LOB data.
Restrictions:
Accessing large files (such as multimedia data) over a remote network can be inefficient and costly. If these files do not change, or change infrequently, you gain faster access to the files and reduced network traffic by replicating these files to remote sites. DB2 Universal Database provides a DATALINK data type that allows the database to control access, integrity, and recovery for these kinds of files. DB2 Universal Database supports DATALINK values on all platforms except OS/390.
DB2 replicates DATALINK columns and uses the ASNDLCOPY user exit routine to replicate the external files to which the DATALINK columns point. This routine transforms each source link reference to a target link reference and copies the external files from the source system to the target system. In the sqllib/samples/repl directory, you can find a sample routine (ASNDLCOPY.SMP) that can use FTP or the file-copy daemon (ASNDLCOPYD.SMP) for the file transfer. For AS/400, you can find the sample programs in the files QCSRC, QCBLLESRC, and QRPGLESRC in library QDPR. See Using the ASNDLCOPY exit routine and Using the ASNDLCOPYD file-copy daemon.
Because external files can be very large, you must ensure that you have sufficient network bandwidth for both the Apply program and whatever file-transfer mechanism you use to copy these files. Likewise, your target system must have sufficient disk space to accommodate these files.
Recommendation:
Restrictions:
You cannot replicate DATALINK values to platforms that do not support them.
If you are replicating to condensed target tables (user copy, point-in-time, condensed CCD, or replica tables), do not use the syntax SET KEYCOL=KEYCOL + n for updates. Data cannot be replicated correctly with this form of key update. Use a different column in the source table as the key in the subscription set. If no alternate key exists in the source table, you can still replicate your data correctly using the following method:
Currently, DB2 DataPropagator has specific restrictions for certain operating-system environments and for certain data types. The major restrictions are:
Allocate sufficient disk space for the active log because Capture for VSE and Capture for VM cannot read archived logs.
DB2 DataPropagator can replicate data that is compressed through DB2 software or hardware compression on DB2 for MVS/ESA V4 (or later) if the dictionary used to compress the data is available. Before issuing REORG for compressed replication sources, you must either:
DB2 DataPropagator cannot replicate data that is compressed using EDITPROC or FIELDPROC.
DB2 Enterprise - Extended Edition can be a target server for the Apply program. Also, DB2 Enterprise - Extended Edition can be the middle tier in a 3-tier configuration. For example, you can capture changes at one database (tier 1) and replicate them to a CCD table in a DB2 Enterprise - Extended Edition database (tier 2), and then replicate the changes from the CCD table to another database (tier 3).
You can capture changes on DB2 Enterprise - Extended Edition only if the source table is nonpartitioned and it resides on the catalog node. Any replication control tables must also be nonpartitioned and reside on the catalog node.
The Control Center does not allow you to select DB2 Enterprise - Extended Edition objects as replication sources or make them part of a subscription set. However, DJRA does allow them.
Because of how communications are handled, you can use DB2 DataPropagator with remote journaling and any SNA connection or you can use DB2 DataPropagator with DRDA and any TCP/IP connection. Other combinations are not supported.
For DB2 for MVS V4 or earlier, if you have a target-tablespace partitioning key, it must match the primary key.
DB2 DataPropagator does not capture stored-procedure calls, but does capture row updates caused by stored procedures.
DB2 DataPropagator only supports referential constraints for user tables and replica tables.
DB2 DataPropagator does not support the following keywords of the SQL CREATE TABLE statement for replica tables that are subject to compensation: DELETE CASCADE, DELETE RESTRICT, and UPDATE RESTRICT.
DB2 DataPropagator cannot capture updates made by any of the database utilities. DB2 DataPropagator also cannot capture updates to data loaded with the LOAD RESUME LOG YES options.
DB2 DataPropagator cannot replicate data that is encrypted.
DB2 DataPropagator cannot replicate the following data types under any circumstances:
DB2 DataPropagator can replicate the following data types under certain circumstances:
User-defined data types (distinct data types in DB2 Universal Database) are converted to the base data type before replication.
You must have one DB2 DataJoiner database for each non-IBM source server. Although you can use one DB2 DataJoiner database for replicating data to multiple non-IBM target servers, you need a unique DB2 DataJoiner database for each non-IBM source server.
For DataJoiner for AIX, replication from Microsoft SQL Server 6.0 and 6.5 must use a DBLIB connection; for DataJoiner for NT, replication from Microsoft SQL Server 6.5 must use the ODBC protocol.
When the data source is Sybase or Microsoft SQL Server and the source table has a column of type timestamp, do not select before and after images when you define the table as a replication source. SQL Server allows only one column of type timestamp. If you require the before and after images, do not select the column of type timestamp when defining the replication source.
When the data source is Oracle, do not select before and after images if the source table has column of type LONG. An Oracle table can contain only one column of type LONG.
DJRA does not support replication of LOB columns in a heterogeneous environment.
DJRA does not support update anywhere replication in a heterogeneous environment.
You do not need to define nicknames for Microsoft Jet or Microsoft Access tables in DB2 DataJoiner. See Using DB2 DataPropagator for Microsoft Jet.
If you run DJRA in a Windows 9x environment, and you experience TCP/IP-related connection problems (for example, a connection failure can make client applications appear to be frozen), you can set network options to control the interval before failure is detected. These are system-wide parameters and can impact all TCP/IP applications. To set these options, edit TCP/IP parameters in the Windows Registry. Be sure to back up your Registry before making changes.
Recommendations for Informix:
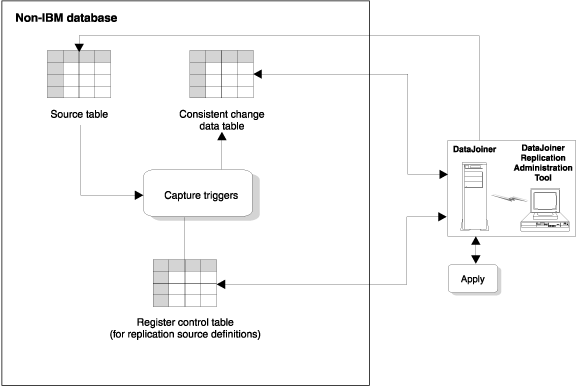
Capture triggers are used for replication from non-IBM databases. They capture changed data from a source table and make the changed data available for replication. Capture triggers perform the same task as the Capture program does for DB2, but in a different manner. DJRA generates the Capture triggers.
DJRA, working through DB2 DataJoiner, creates Capture triggers at the non-IBM source database when you define the source tables as replication sources. Capture triggers capture committed changes made to source data and place the captured changes into a staging table, called the consistent change data (CCD) table. DB2 DataJoiner has a nickname for the CCD table, and programs that want to replicate the changes (for example, the Apply program) can access this nickname. See Staging data for more information about CCD tables.
There are three triggers for each source table: DELETE, UPDATE, and INSERT.
The Capture triggers work with the following objects: the CCD table, the register control table, the pruning control table, and the register synchronization control table.
DJRA generates SQL (when you define a table as a replication source) that, when run:
Whenever a delete, update, or insert operation occurs at the defined source, a Capture trigger records the change into the CCD table. When the Capture triggers retrieve changed information, they can also obtain before and after column data to put into the CCD table.
If the primary key values of the target table will be updated, or the table (or view) contains a logical partitioning column that will be updated, you must specify replication logical-partitioning-key support when you define the replication source. Replication logical-partitioning-key support performs an UPDATE as a DELETE followed by an INSERT. See Enabling replication logical-partitioning-key support for more information.
The Apply program then reads the CCD table (through DB2 DataJoiner nicknames), copies the changes to the target server, and applies the changes to the target table. Figure 18 shows the relationship between the Capture triggers, the source table, the register control table, and the CCD table.
Figure 18. Capture triggers at the source server. The Capture triggers monitor source changes, capture the changed data, and write the changed data to the CCD table.
 |
When DJRA creates and places Capture triggers on a non-IBM database, you might encounter the following situations:
Typically during replication, changes to a source table are captured, the changed rows are inserted into the CD table, and the related transaction information is inserted into the UOW table. The CD table is joined with the UOW table to determine which changes are committed and can therefore be replicated to target tables. This joined output can be saved in a CCD table from which changed data information can also be read. A CCD table contains committed changes only. By using a CCD table, several subscription sets (and their members) can refer to that information without each incurring overhead for a join of the CD and UOW tables for each subscription cycle. 18
There are other uses for CCD tables apart from eliminating the need to join the CD and UOW tables. When you set up your replication environment, you can choose the type of CCD table that is appropriate for your replication environment. To help you determine whether or not you need to use CCD tables, this section describes the attributes of CCD tables and the typical uses of CCD tables.
If you want to use a CCD table, you must decide where you want it located and what change data it must contain.
A local CCD table resides in the source database. A remote CCD table resides away from the source database; that is, in any other database in the network that the Apply program can access. If you have many remote targets, you can use a remote CCD table as the source table to reduce network traffic from the source.
A complete CCD table contains all rows that satisfy the source view and predicates from the source table or view. The Apply program uses a complete CCD table as the source for full refreshes or to replicate changes to other target tables.
A noncomplete CCD table contains only changes that were made to the source table. Thus, a noncomplete CCD table is initially empty and is populated as changes are made to the source table. When a noncomplete CCD table is initially created, or when the Capture program is cold started, the Apply program does not refresh a noncomplete CCD table with all the rows of the source table. 19 The Apply program records changes that are made to the source table but does not replicate the original rows. The Apply program cannot use a noncomplete CCD table to refresh other target tables.
A condensed CCD table contains only the most recent values for columns. For example, if one row is changed 5 times in the source table, the condensed CCD table would contain one row showing the results of all 5 changes to the source table. Condensed CCD tables consolidate changes and reduce network traffic for staged replication. A noncondensed CCD table contains one row for each change that is made to a row in the replication source. In this case, if a single row is changed 5 times in the source table; the noncondensed CCD table would contain 5 rows (one for each change). That is, it represents the history of changes to each row. Noncondensed CCD tables are useful for auditing purposes.
Defining unique indexes: A condensed CCD table requires unique key values for each row, but a noncondensed CCD table can have multiple rows with the same key values. Because of the differences in key uniqueness, you must define a unique index for a condensed CCD table, and you must not define one for a noncondensed CCD table.
Table 5 summarizes the types of CCD tables based on the possible
combinations of attributes.
Table 5. Basic types of CCD tables
| A CCD table can be local or remote, complete or noncomplete, condensed or noncondensed, or any combination of these. | |||
| Location | Complete | Condensed | Description |
|---|---|---|---|
| Local | Yes | Yes | A CCD table that resides in the source database and contains the same data as the replication source. |
| No | A CCD table that resides in the source database and contains a complete history of changes including the original data from the replication source. | ||
| No | Yes | A CCD table that resides in the source database and contains the latest change data only. | |
| No | A CCD table that resides in the source database and contains all change data only. | ||
| Remote | Yes | Yes | A CCD table that resides in a database that the Apply program can access, other than the source database, and contains the same data as the user table. |
| No | A CCD table that resides in a database that the Apply program can access, other than the source database, and contains a complete history of changes including the original replication source data. | ||
| No | Yes | A CCD table that resides in a database that the Apply program can access, other than the source database, and contains the latest change data only. | |
| No | A CCD table that resides in a database that the Apply program can access, other than the source database, and contains all the change data only. | ||
You can use CCD tables as sources for replication to other target tables. 20
Depending on your replication environment, you can choose to register your complete CCD table as a replication source (an external CCD table), or you can set up your CCD table so that it is used implicitly as a source for replication (an internal CCD table).
If you perform a full refresh on an external CCD table, the Apply program performs a full refresh on all target tables that use this external CCD table as a replication source. This process is referred to as a cascade full refresh. You can define more than one external CCD table for a replication source. An external CCD table can have any attributes you like (local or remote, complete or noncomplete, condensed or noncondensed); however, if you use it to stage data, you must use a complete CCD table because the Apply program will use it to perform both full refresh and change replication.
Internal CCD tables are useful for staging changes. The Apply program uses the original source table for full refreshes, and it uses the internal CCD for change replication (instead of joining the CD and UOW table each time changes are replicated). 21
Use an internal CCD table as a local cache for committed changes to a source table. The Apply program replicates changes from an internal CCD table, if one exists, rather than from CD tables.
You can use an internal CCD table as an implicit source for replication without explicitly defining it as a replication source. When you add a subscription-set member, you can specify that you want an internal CCD table if the table has the following attributes:
The following list shows all types of CCD tables and describes whether they are suitable for staging data.
You can define this type of CCD table as a replication source and use it in the following ways:
Typically you would create this table nearer the targets rather than local to the source to save network traffic during both change replication and full refreshes. Also, multiple updates to a single source table row will result in replication of a single row to all target tables.
Do not define this type of CCD table as a replication source nor as an internal CCD table.
Do not use this type of CCD table as a replication staging table because of the space consumed by saving each and every change.
This table contains a complete set of rows initially, and it is appended with each and every row change. No information is overwritten, and no information is lost. Use this type of CCD table with applications that need to process temporal queries (for example, as of last Tuesday, a month ago, or yesterday) anytime following the initialization of the CCD table. Also use this type of CCD table for auditing applications that require a complete set of rows. (Other ways of auditing are described in Auditing data usage.)
You can define this type of CCD table as an internal CCD table for the replication source. By defining it as an internal CCD table, you access the original source during full refreshes only, and use the CCD table for updates. It is efficient because the join of the CD and UOW tables happens only once, to populate the CCD table, and then changes are replicated from the CCD table to all targets without the join overhead. Because the CCD table is noncomplete, full refreshes must come from the original source table. This type of table is also useful for condensing change data from a CD table. Condensing reduces the number of rows replicated to remote sites, and the number of SQL operations against the target tables, by eliminating all but the last change for each row.
In most cases, do not define this type of CCD table as a replication source. Use this type of table for auditing applications that do not require a complete set of rows, only the recently changed rows.
You might define the CCD table as an internal CCD for a replication source when the remote targets themselves are noncondensed. In this case, if there are many remote targets, you can benefit by avoiding repeated joins of the CD tables with the UOW table, as long as this benefit outweighs the cost of storing and maintaining the CCD table.
If you define an internal CCD table as a target, all other target tables associated with the source table will have changes replicated from that internal CCD table and not from the original source table. For this reason it is important to plan all the potential target tables to make sure that you define the internal CCD table correctly. If you do not include all the columns of the source table in the internal CCD table, but a target table includes all of those columns, then replication will fail. Similarly if the CD table used to maintain the internal CCD table does not include all the columns of the source table, but a target table includes all the columns, then replication will fail also.
Internal CCD tables do not support additional UOW table columns. If you define target CCD tables (with UOW columns) as a replication source, you cannot then define an internal CCD table. Do not use an internal CCD table if you already defined a target CCD table that includes UOW columns.
If you want to use column subsetting in an internal CCD table, review all previously-defined target tables to make sure that the internal CCD table definition includes all appropriate columns from the source tables. If you define the subscription set for the internal CCD table before you define any of the other subscription sets from this source, the other subscription sets are restricted to the columns that are in the internal CCD table.
You can use CCD tables to replicate changes that are captured by application programs or tools on other database management systems, such as Oracle. Triggers on the Oracle tables simulate the Capture program by placing the changes into Oracle CCD tables. Capture triggers for non-IBM sources also use the internal CCD setup to replicate changes. For an example of this usage, see Retrieving data from a non-DB2 distributed data store.
Similarly, changes captured by application programs or other tools, such as IMS DataPropagator, can be defined as sources for subscription sets. The application program must create and maintain a complete CCD table, and that CCD table is considered to be an external CCD table. This CCD table must be external, but can be condensed or noncondensed. For example, IMS DataPropagator captures changes to IMS DB segments and updates its CCD table. You define the CCD table as a replication source, and then you define subscription sets using this CCD table, regardless of where the original updates occur. For an example of this usage, see Distributing IMS data to remote sites.
The Capture program can prune CD tables based on information inserted into the pruning control table by the Apply program. You control whether the Capture program prunes CD tables by using the PRUNE or NOPRUNE parameter. You can also control when the pruning takes place and how the prune interval is set by modifying the tuning parameters control table.
Some CCD tables can continue to grow in size, especially noncondensed CCD tables. These tables are not pruned automatically; you must prune them manually or use an application program. For some types of CCD tables, you might want to archive them and define new ones, rather than prune them.
When the source table is a non-IBM table, the Capture triggers prune the CCD table based on a synchpoint that the Apply program writes to the pruning control table.
Auditing is the need to track histories of data use, in terms of before and after comparisons of the data or identifying changes by time and by updating user ID.
IBM Replication supports auditing in the following ways:
A noncondensed CCD table holds one row per UPDATE, INSERT, or DELETE operation, thus maintaining a history of the operations performed on the source table. If you capture UPDATE operations as INSERT and DELETE operations (for partitioning key columns), the CCD table will have one row per DELETE and INSERT and two rows per UPDATE.
Important: Do not cold start the Capture program if you want to maintain accurate histories of change data. A gap might occur if the Apply program could not replicate changes before the Capture program was shut down. See Resolving gaps between source and target tables.
Use noncomplete, noncondensed CCD tables to keep a partial history of updates to a source table or to maintain an audit trail of database usage. For improved auditing capability, include the extra columns from the UOW table. 22
Use complete, noncondensed CCD tables to keep a complete history of changes to a source table.
For more information see Attributes of CCD tables.
If you need more user-oriented identification, columns for the DB2 for OS/390 correlation ID and primary authorization ID or the AS/400 job name and user profile are available in the UOW table.
Migration for AS/400:
You cannot run Version 1 of DPropR/400 concurrently with Version 7. If you currently use Version 1, or if you use Version 1 replication components in a Version 5 DPropR/400 environment, you must either:
Migrating from DPropR/400 V5 to V7 does not require any special migration.
You should use DJRA for all replication administration tasks. However, both DJRA and the DB2 Control Center provide basic replication administration functions for defining replication sources and subscription sets.
Migration for OS/2, UNIX, and Windows:
Beginning with Version 5 of DB2 Universal Database (for Windows, OS/2, and UNIX), the replication component is automatically installed with DB2 (that is, it is not optional). After you install DB2 UDB Version 7, you cannot:
Migrating from DB2 UDB V6 to V7 does not require any special migration for replication.
Important: Interoperability between Version 1 and Version 6 or Version 7 replication components is not supported. Therefore, you must complete all Version 1 to Version 5 migrations before you introduce DB2 UDB Version 6 or Version 7. Instructions are in the Migration Guide available from the Library page of the DB2 DataPropagator Web site (www.ibm.com/software/data/dpropr/).
The Version 5 Capture and Apply components can run alongside the Version 6 or Version 7 Capture and Apply programs; you do not need to migrate all servers at the same time.
In addition:
DB2 UDB supports the DB2 Universal Database Satellite Edition enabler command ASNSAT. However, you cannot use the DB2 Universal Database Satellite Edition SYNCH command in an existing replication environment because the SYNCH command relies on centralized administration controlled by a central control server. The central control server is not aware of any existing replication environment administered without use of the SYNCH command.
For more information about DB2 Universal Database Satellite Edition, see DB2 Universal Database Administering Satellites Guide and Reference.
Migration for OS/390:
Interoperability between Version 1 and Version 6 or Version 7 replication components is not supported. Therefore, you must complete all Version 1 to Version 5 migrations before you introduce DB2 for OS/390 Version 6 or Version 7. Instructions are in the Migration Guide available from the Library page of the DB2 DataPropagator Web site (www.ibm.com/software/data/dpropr/).
Migrating from DB2 for OS/390 V6 to V7 does not require any special migration for replication.
The Version 5 Capture and Apply components can run alongside the Version 6 or Version 7 Capture and Apply programs; you do not need to migrate all servers at the same time.