The hot standby capability can be used to failover the entire instance of a single partition database or a partition of a partitioned database configuration. If one processor fails, another processor in the cluster can substitute for the failed processor by automatically transferring the instance. The database instance and the actual database must be accessible to both the primary and the failover processor.
For detailed information about the actual installation requirements, and about instance creation, refer to HACMP for AIX, Version 4.2: Installation Guide, SC23-1940.
Each of the following examples has a sample script that is stored (on DB2 for AIX installations) in sqllib/samples/hacmp.
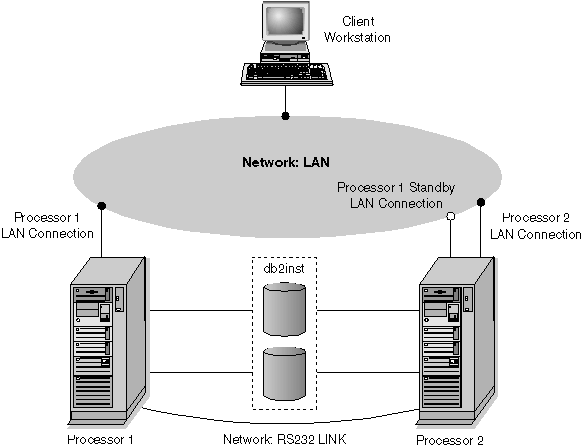
The following hot standby failover scenario consists of a two-processor HACMP cluster running a single-partition database instance (Figure 44). For information about configuring your HACMP cluster, see Resources.
Figure 44. Example of a Hot Standby Failover Configuration
Both processors have access to the installation directory, the instance directory, and the database directory. The database instance "db2inst" is being actively executed on processor 1. Processor 2 is not active, and is being used as a hot standby. A failure occurs on processor 1, and the instance is taken over by processor 2. Once the failover is complete, both remote and local applications can access the database within instance "db2inst". The database will have to be manually restarted or, if AUTORESTART is on, the first connection to the database will initiate a restart operation. In the sample script provided, it is assumed that AUTORESTART is off, and that the failover script performs the restart for the database. For more information about AUTORESTART, see Overview of Recovery .
Sample script:
hacmp-s1.sh
In the following hot standby failover scenario, we are using an instance partition instead of the entire instance. The scenario includes a two processor HACMP cluster as in the previous example, but the machine represents one of the partitions of a partitioned database server. Processor 1 is running a single partition of the overall configuration, and processor 2 is being used as the failover processor. When processor 1 fails, the partition is restarted on the second processor. The failover updates the db2nodes.cfg file, pointing to processor 2's host name and net name, and then restarts the partition on the new processor.
Following is a portion of the db2nodes.cfg file, both before and after the failover. In this example, node number 2 is running on processor 1 of the HACMP machine, which has both a host name and a net name of "node201". After the failover, node number 2 is running on processor 2 of the HACMP machine, which has both a host name and a net name of "node202".
Before:
1 node101 0 node101
2 node201 0 node201 <= HACMP
3 node301 0 node301
db2start nodenum 2 restart hostname node202 port 0 netname node202
After:
1 node101 0 node101
2 node202 0 node202 <= HACMP
3 node301 0 node301
Sample script:
hacmp-s2.sh
A more complex variation on the previous example involves the failover of multiple logical nodes from one processor to another. Again, we are using the same two processor HACMP cluster configuration as above. However, in this scenario, processor 1 is running 3 logical partitions. The setup is the same as that for the simple partition failover scenario, but in this case when processor 1 fails, each of the logical partitions must be started on processor 2. Each logical partition must be started in the order that is defined in the db2nodes.cfg file: the logical partition with port number 0 must always be started first.
Following is a portion of the db2nodes.cfg file, both before and after the failover. In this example, there are 3 logical partitions defined on processor 1 of a two-processor HACMP cluster.
Before:
1 node101 0 node101
2 node201 0 node201 <= HACMP
3 node201 1 node201 <= HACMP
4 node201 2 node201 <= HACMP
5 node301 0 node301
db2start nodenum 2 restart hostname node202 port 0 netname node202
db2start nodenum 3 restart hostname node202 port 1 netname node202
db2start nodenum 4 restart hostname node202 port 2 netname node202
After:
1 node101 0 node101
2 node202 0 node202 <= HACMP
3 node202 1 node202 <= HACMP
4 node202 2 node202 <= HACMP
5 node301 0 node301
Sample script:
hacmp-s3.sh