A database can become unusable because of hardware or software failure (or both), and different failure scenarios may require different recovery actions. You should have a rehearsed strategy in place to protect your database against the possibility of failure.
This section discusses different recovery methods, and shows you how to determine which recovery method is best suited to your business environment. The following topics are covered:
You need to know the strategies available to you when there are problems with the database. These include problems with media and storage, power interruptions, and application failures. You can back up your database, or individual table spaces, and then rebuild them should they be damaged or corrupted in some way. The concept of a database backup is the same as any other data backup: taking a copy of the data and storing it on a different medium in case of failure or damage to the original. The simplest case of a backup involves shutting down the database to ensure that no further transactions occur, and then simply backing it up.
The rebuilding of the database is called recovery. Crash recovery automatically attempts to recover the database after a failure. There are two ways to recover a damaged database: version recovery and roll-forward recovery.
Non-recoverable databases have both the logretain and the userexit database configuration parameter disabled. This means that the only logs that are kept are those required for crash recovery. These logs are known as active logs, and they contain current transaction data. Version recovery using offline backups is the primary means of recovery for a non-recoverable database. (An offline backup means that no other application can use the database when the backup operation is in progress.) Such a database can only be restored offline. It is restored to the state it was in when the backup image was taken.
Recoverable databases have either the logretain database configuration parameter set to "RECOVERY", the userexit database configuration parameter enabled, or both. Active logs are still available for crash recovery, but you also have the archived logs, which contain committed transaction data. Such a database can only be restored offline. It is restored to the state it was in when the backup image was taken. However, with roll forward recovery, you can roll the database forward (that is, past the time when the backup image was taken) by using the active and archived logs to either a specific point in time, or to the end of the active logs.
Recoverable database backup operations can be performed either offline or online (online meaning that other applications can connect to the database during the backup operation). The database restore and roll forward operations must always be performed offline. During an online backup operation, roll-forward recovery ensures that all table changes are captured and reapplied if that backup is restored.
If you have a recoverable database, you can back up, restore, and roll forward individual table spaces, rather than the entire database. When you back up a table space online, it is still available for use, and simultaneous updates are recorded in the logs. When you perform an online restore or roll forward operation on a table space, the table space itself is not available for use until the operation completes, but users are not prevented from accessing tables in other table spaces.
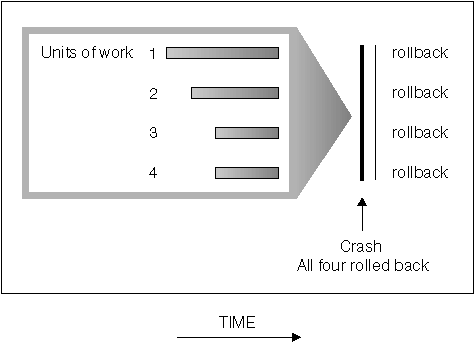
Crash recovery protects a database from being left in an inconsistent, or unusable, state. Transactions (or units of work) against the database can be interrupted unexpectedly. If a failure occurs before all of the changes that are part of the unit of work are completed and committed, the database is left in an inconsistent and unusable state.
The database then needs to be moved to a consistent and usable state. This is done by rolling back incomplete transactions and completing committed transactions that were still in memory when the crash occurred (Figure 13).
Figure 13. Rolling Back Units of Work
|
When a database is in a consistent and usable state, it has attained what is known as a "point of consistency". An offline database backup represents a point of consistency. When a point of consistency is reached, all transactions have been resolved and the data is available to other users or applications.
You can move to a point of consistency following a crash by invoking the RESTART DATABASE command (refer to the Command Reference). If you want this done in every case of a failure, you should consider the use of the automatic restart enable (autorestart) configuration parameter. The default behavior for this database configuration parameter is to invoke the RESTART DATABASE command whenever it is needed. When autorestart is enabled, the next connect request to the database after a failure causes the RESTART DATABASE command to be invoked.
Crash recovery moves the database to a consistent and usable state. If, however, crash recovery is applied to a database that is enabled for forward recovery (that is, the logretain configuration parameter is set to "RECOVERY", or the userexit configuration parameter is enabled), and an error occurs during crash recovery that is attributable to an individual table space, that table space must be taken offline, and cannot be accessed until it is repaired. Crash recovery continues. At the completion of crash recovery, the other table spaces in the database are still usable, and connections to the database can be established. (There are exceptions involving the table spaces that have temporary tables or the system catalog tables. These are discussed under roll-forward recovery.)
As mentioned earlier, DB2 provides two methods to recover a damaged database:
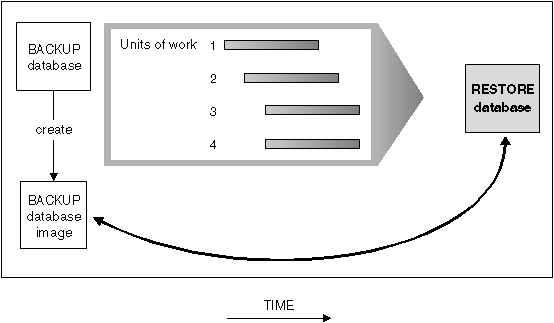
A database restore operation will rebuild the entire database using a backup of the database made earlier. A backup of the database allows you to restore a database to a state identical to the one at the time that the backup was made. Every unit of work from the time of the backup to the time of the failure is lost (see Figure 14).
Using the version recovery method, you must schedule and perform full backups of the database on a regular basis.
In a partitioned database environment, the database is located across many database partition servers (or nodes). You must restore all partitions, and the backup images that you use for the restore database operation must all have been taken at the same time. (Each database partition is backed up and restored separately.) A backup of each database partition taken at the same time is known as a version backup.
Figure 14. Restoring a Database
 |
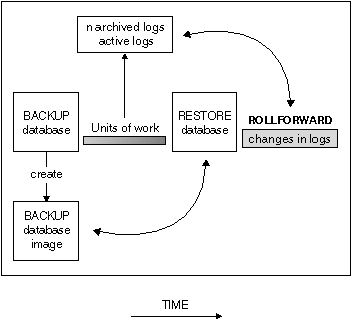
The two types of roll-forward recovery to consider are:
In a partitioned database environment, the database is located across many database partitions. If you are performing point-in-time roll-forward recovery, all database partitions must be rolled forward to ensure that all partitions are at the same level. If you need to restore a single database partition, you can perform roll-forward recovery to the end of the logs to bring it up to the same level as the other partitions in the database.
Figure 15. Database Roll-forward Recovery
 |
Notes:
Table space roll-forward recovery can be used in the following two situations:
| Note: | If the table space in error contains the system catalog tables, you will not be able to start the database. You must restore the SYSCATSPACE table space, then perform roll-forward recovery to the end of the logs. |
In a partitioned database environment, if you are rolling forward a table space to a point in time, you do not have to supply the list of nodes (database partitions) on which the table space resides. DB2 submits the roll-forward request to all partitions. This means the table space must be restored on all database partitions on which the table space resides.
In a partitioned database environment, if you are rolling forward a table space to the end of the logs, you must supply the list of database partitions if you do not want to roll the table space forward on all partitions. If you want to roll forward all table spaces on all partitions that are in roll-forward pending state to the end of the logs, you do not have to supply the list of database partitions. By default, the rollforward database request is sent to all partitions.
To decide which database recovery method to use, you must consider the following key factors:
In general, a database maintenance and recovery strategy should ensure that all information is available when it is required for database recovery. The strategy should include a regular schedule for taking database backups, as well as scheduled backups when a database is created, or in the case of a partitioned database system, when the system is scaled by adding or dropping database partition servers (nodes). In addition to these basic requirements, a good strategy will include elements that reduce the likelihood and impact of database failure.
The following topics provide additional information:
While the general focus of this section is on the database, your overall recovery planning should also include recovering:
If you can recreate data easily, the database holding that data can be a non-recoverable database. For example:
If you cannot recreate data easily, the database holding that data should be a recoverable database. The following are examples of data that should be part of a recoverable database:
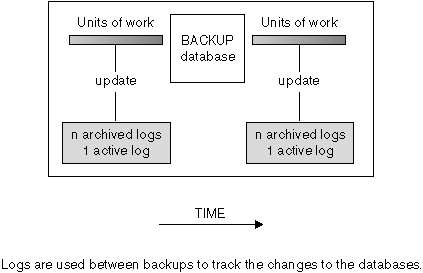
All databases have logs associated with them. These logs keep records of database changes. If a database needs to be restored to a point beyond the last full, offline backup, then logs are required to roll the data forward to the point of failure.
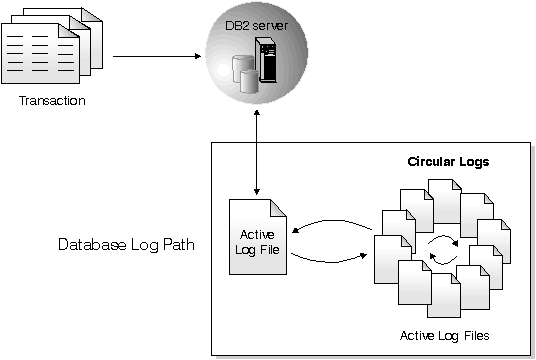
There are two types of DB2 logging: circular and archive, each providing a different level of recovery capability.
Circular logging is the default behavior when a new database is created. With this type of logging, only full, offline backups of the database are valid. As the name suggests, circular logging uses a "ring" of online logs to provide recovery from transaction failures and system crashes. The logs are used and retained only to the point of ensuring the integrity of current transactions. Circular logging does not allow you to roll forward a database through prior transactions from the last full backup. Recovery from media failures and disasters is done by restoring from a full, offline backup. All changes since the last backup are lost. The database must be offline (inaccessible to users) when a full backup is taken. Since this type of restore recovers your data to the specific point in time of the full backup, it is called version recovery.
Figure 16 shows that the active log uses a ring of log files when circular logging is active.
 |
Active logs are used during crash recovery to prevent a failure (system power or application error) from leaving a database in an inconsistent state. The RESTART DATABASE command uses the active logs, if needed, to move the database to a consistent and usable state. During crash recovery, changes recorded in these logs that were not committed because of the failure are rolled back. Changes that were committed but were not physically written from memory (buffer pool) to disk (database containers) are redone. These actions ensure the integrity of the database. The ROLLFORWARD DATABASE command may also use the active logs, if needed, during a point-in-time recovery, or a recovery to the end of the logs. Active logs are located in the database log path directory.
Archived logs are used specifically for roll-forward recovery. They can be:
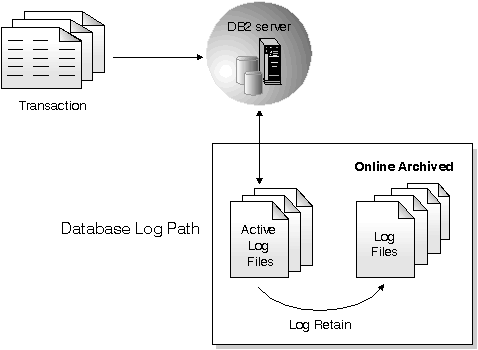 |
Figure 18. Offline Archived Logs
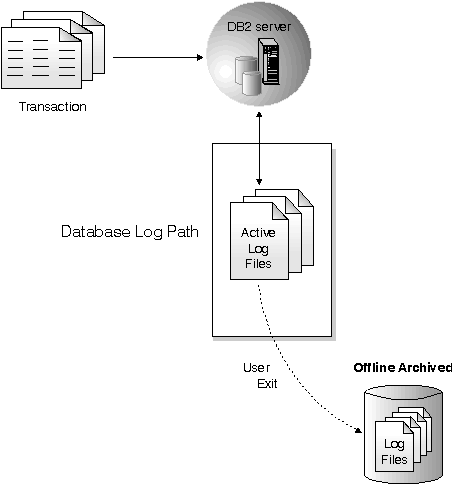 |
Roll-forward recovery can use both archived logs and active logs to rebuild a database either to the end of the logs, or to a specific point in time. The roll-forward function achieves this by reapplying committed changes found in the archived and active logs to the restored database.
Roll-forward recovery can also use logs to rebuild a table space by re-applying committed updates in both archived and active logs. You can recover a table space to the end of the logs, or to a specific point in time.
During an online backup, all activities against the database are logged. When an online backup is restored, the logs must be rolled forward at least to the point in time at which the backup was completed. For this to happen, you must archive the logs and make them available when the database is to be restored. The log file used at backup time may continue to be open long after the backup operation completes. The FLUSH LOG option for online backup on the BACKUP DATABASE command will close the active log when an online backup completes. This will allow the active log to be archived, so that you will have a complete backup, as well as all of the logs required for the restoration of that backup.
Figure 19. Active and Archived Database Logs in Roll-forward Recovery
 |
Two database configuration parameters allow you to change where archived logs are stored: The newlogpath parameter, and the userexit parameter. Changing the newlogpath parameter also affects where active logs are stored. Refer to Administration Guide: Performance for more information about these configuration parameters.
To determine which log extents (see Containers) in the database log path directory are archived logs, check the value of the loghead database configuration parameter. This parameter indicates the lowest numbered log that is active. Those logs with sequence numbers less than loghead are archived logs and can be moved. You can check the value of this parameter by using the Control Center; or, by using the command line processor and the GET DATABASE CONFIGURATION command to view the "First active log file". Refer to Administration Guide: Performance for more information about this configuration parameter.
Notes:
If your application creates and populates work tables from master tables, and you are not concerned about the recoverability of these work tables because they can be easily recreated from the master tables, you may want to create the work tables specifying the NOT LOGGED INITIALLY parameter on the CREATE TABLE statement. The advantage of using the NOT LOGGED INITIALLY parameter is that any changes made on the table (including insert, delete, update, or create index operations) in the same unit of work that creates the table will not be logged. This not only reduces the logging that is done, but may also increase the performance of your application. You can achieve the same result for existing tables by using the ALTER TABLE statement with the NOT LOGGED INITIALLY parameter.
Notes:
Because changes to the table are not logged, you should consider the following when deciding to use the NOT LOGGED INITIALLY parameter:
| Note: | When a table is created, row locks are held on the catalog tables until a COMMIT is done. To take advantage of the no logging behavior, you must populate the table in the same unit of work in which it is created. This has implications for concurrency. For more information, refer to "Concurrency" in the Administration Guide: Performance. |
For more information about creating tables, refer to the SQL Reference.
If you plan to use declared temporary tables as work tables, note the following:
For more information about declared temporary tables and their limitations, refer to the DECLARE GLOBAL TEMPORARY TABLE statement in the SQL Reference.
The version and roll-forward recovery methods provide different points of recovery. The version method involves making an offline, full database backup copy of the database at scheduled times. With this method, the recovered database is only as current as the backup copy that was restored. For instance, if you make a backup copy at the end of each day, and you lose the database midway through the next day, you will lose a half-day of changes.
In the roll-forward recovery method, changes made to the database are retained in logs. With this method, you first restore the database or table spaces using a backup copy; then you use the logs to reapply changes that were made to the database since the backup copy was created.
With roll-forward recovery enabled, you can take advantage of online backup and table space level backup. For full database and table space roll-forward recovery, you can choose to recover to the end of the logs, or to a specified point in time. For instance, if an application corrupted the database, you could start with a restored copy of the database, and roll forward changes up to just before that application started. No units of work written to the logs after the time specified are reapplied.
You can also roll forward table spaces to the end of the logs, or to a specific point in time.
Your recovery plan should allow for regularly scheduled backups, since backing up a database requires time and system resources.
You should take full database backups regularly, even if you archive the logs (which allows for roll-forward recovery). If your recovery strategy includes roll-forward recovery, a recent full database backup will mean that there are fewer archived logs to apply to the database, which reduces the amount of time required by the ROLLFORWARD utility to recover the database.
You should also consider not overwriting backups and logs, saving more than one full database backup and its associated logs as an extra precaution.
If the amount of time needed to apply archived logs when recovering and rolling forward a very active database is a major concern, consider the cost of backing up the database more frequently. This reduces the number of archived logs you need to apply when rolling forward.
You can perform a backup while the database is either online or offline. If it is online, other applications or processes can continue to connect to the database, as well as read and modify data while the backup operation is running. If the backup is performed offline, only the backup operation can be connected to the database; the rest of your organization cannot connect to the database while the backup task is running.
To reduce the amount of time that the database is not available, consider using online backups. Online backups are supported only if roll-forward recovery is enabled. If roll-forward recovery is enabled and you have a complete set of logs, you can rebuild the database, should the need arise.
Notes:
If a database contains large amounts of long field and LOB data, backing up the database could be very time-consuming. The BACKUP command provides the capability of backing up selected table spaces. If you use DMS table spaces, you can store different types of data in their own table spaces to reduce the time required for backup operations. You can keep table data in one table space, long field and LOB data in another table space, and indexes in another table space. By storing long field and LOB data in separate table spaces, the time required to complete the backup can be reduced by choosing not to back up the table spaces containing the long field and LOB data. If the long field and LOB data is critical to your business, backing up these table spaces should be considered against the time required to complete the restore operation for these table spaces. If the LOB data can be reproduced from a separate source, choose the NOT LOGGED option when creating or altering a table to include LOB columns.
If you reorganize a table, you should back up the affected table spaces after the operation completes. If you have to restore the table spaces, you will not have to roll forward through the data reorganization.
| Note: | If you back up a table space that does not contain all of the table data, you cannot perform point-in-time roll-forward recovery on that table space. All the table spaces that contain any type of data for a table must be rolled forward simultaneously to the same point in time. |
The time required to recover a database is made up of two parts: the time required to complete the restoration of the backup; and, if the database is enabled for forward recovery, the time required to apply the logs during the roll-forward operation. When formulating a recovery plan, you should take these recovery costs and their impact on your business operations into account. Testing your overall recovery plan will assist you in determining whether the time required to recover the database is reasonable given your business requirements. Following each test, you may want to increase the frequency with which you take a backup. If roll-forward recovery is part of your strategy, this will reduce the number of logs that are archived between backups and, as a result, reduce the time required to roll forward the database after a restore operation.
| Note: | The setting of the "enable intra-partition parallelism" (intra_parallel) database manager configuration parameter does not affect the performance of either backup or restore operations. Multiple processes will be used for each of these operations, regardless of the setting of the intra_parallel parameter. |
When deciding which recovery method to use, consider the storage space required.
The version recovery method requires space to hold the backup copy of the database and the restored database. The roll-forward recovery method requires space to hold the backup copy of the database or table spaces, the restored database, and the archived database logs.
If a table contains long field or large object (LOB) columns, you should consider placing this data into a separate table space. This will affect your storage space considerations, as well as affect your plan for recovery. With a separate table space for long field and LOB data, and knowing the time required to back up long field and LOB data, you may decide to use a recovery plan that only occasionally saves a backup of this table space. You may also choose, when creating or altering a table to include LOB columns, not to log changes to those columns. This will reduce the size of the required log space and the corresponding log archive space.
The backup of an SMS table space that contains LOBs can be larger than the size of the original table space. The backup can be as much as 40 per cent larger, depending on the LOB data size in the table space. For example, if you take a backup of a 1 GB SMS table space (with LOBs), you will need more than 1 GB of disk space when you restore it. This only occurs on file systems that support sparse allocation (for example, on UNIX based operating systems).
To prevent media failure from destroying a database and your ability to rebuild it, keep the database backup, the database logs, and the database itself on different devices. For this reason, it is highly recommended that you use the newlogpath configuration parameter to put database logs on a separate device once the database is created. (This and other configuration parameters related to logging are discussed in Rolling Forward Changes in a Database .)
The database logs can use up a large amount of storage. If you plan to use the roll-forward recovery method, you must decide how to manage the archived logs. Your choices are the following:
| Note: | On OS/2, DB2 supports a user exit program to handle the storage of both database backup images and database logs on standard and non-standard devices. For more information, see Appendix F, User Exit for Database Recovery . |
As part of your database design, you will know the relationships that exist between tables. These relationships can be expressed at the application level, when transactions update more than one table, or at the database level, where referential integrity exists between tables, or where triggers on one table affect another table. You should consider these relationships when developing a recovery plan. You will want to back up related sets of data together. Such sets can be established at either the table space or the database level. By keeping related sets of data together, you can recover to a point where all of the data is consistent. This is especially important if you want to be able to perform point-in-time roll-forward recovery on table spaces.
When working in an environment that has more than one operating system, you must consider that the backup and recovery plans cannot be integrated. That is, you may not use the BACKUP DATABASE command on one operating system, and the RESTORE DATABASE command on another operating system. You should keep the recovery plans for each operating system separate and independent.
If you must move tables from one operating system to another, use the db2move command, or use the EXPORT with the IMPORT or LOAD commands. For more information, refer to the Data Movement Utilities Guide and Reference.
A damaged table space has one or more containers that cannot be accessed. This is often caused by media problems that are either permanent (for example, a bad disk), or temporary (for example, an offline disk, or an unmounted file system).
If the damaged table space is the system catalog table space, the database cannot be restarted. If the container problems cannot be fixed leaving the original data intact, the only available options are:
| Note: | Table space restore is only valid for recoverable databases, since the database must be rolled forward. |
If the damaged table space is not the system catalog table space, DB2 attempts to make as much of the database available as possible; success in this case depends on the logging strategy.
If the damaged table space is a sole temporary table space, you should create a new temporary table space as soon as a connection to the database is made. Once created, the new temporary table space can be used, and normal database operations requiring temporary table space can resume. You can, if you wish, drop the offline temporary table space. There are special considerations for table reorganization using a system temporary table space:
The damaged table space is put in offline and not accessible state, and in roll forward pending state, because crash recovery is necessary. The restart operation will succeed if there is no additional problem. The damaged table space can be used again once you:
Since crash recovery is necessary, and logs are not kept indefinitely, the restart operation can only succeed if the user is willing to drop the damaged table spaces. (Successful completion of recovery means that the log records necessary to recover the damaged table spaces to a consistent state will be gone; therefore, the only valid action against such table spaces is to drop them.)
You can do this by invoking an unqualified restart database operation. It will succeed if there are no damaged table spaces. If it fails (SQL0290N), you can look in the db2diag.log file for a complete list of table spaces that are currently damaged.
| Note: | Putting a table space name into the DROP PENDING TABLESPACES list does not mean that the table space will be in drop pending state. This will occur only if the table space is found to be damaged during the restart operation. Once the restart operation is successful, you should issue DROP TABLESPACE statements to drop each of the table spaces that are in drop pending state (invoke the LIST TABLESPACES command to find out which table spaces are in this state). This way the space can be reclaimed, or the table spaces can be recreated. |
The following should be considered when thinking about recovery performance:
You should also consider what other files are on the disk. For example, moving the logs to the disk used for system paging in a system that has insufficient real memory will defeat your tuning efforts.
If you use multiple buffers and I/O channels, you should use at least twice as many buffers as channels to ensure that the channels do not have to wait for data. The size of the buffers used will also contribute to the performance of the restore operation. The ideal restore buffer size should be a multiple of the extent size for the table spaces.
If you have multiple table spaces with different extent sizes, specify a value that is a multiple of the largest extent size.
The minimum recommended number of buffers is the number of media devices or containers plus the number specified for the PARALLELISM option.
| Note: | If you back up a table space that contains table data without the associated long or LOB fields, you cannot perform point-in-time roll-forward recovery on that table space. All the table spaces for a table must be rolled forward simultaneously to the same point in time. |
The term disaster recovery is used to describe the activities that need to be done to restore the database in the event of a fire, earthquake, vandalism, or other catastrophic events. A plan for disaster recovery can include one or more of the following:
If your plan for disaster recovery is to recover the entire database on another machine, you require at least one full database backup and all the archived logs for the database. You may choose to keep a standby database up to date by applying the logs to it as they are archived. Or, you may choose to keep the database backup and log archives in the standby site, and perform restore and rollforward operations only after a disaster has occurred. (In this case, a recent database backup is clearly desirable.) With a disaster, however, it is generally not possible to recover all of the transactions up to the time of the disaster.
The usefulness of a table space backup for disaster recovery depends on the scope of the failure. Typically, disaster recovery requires that you restore the entire database; therefore, a full database backup should be kept at a standby site. Even if you have a separate backup image of every table space, you cannot use them to recover the database. If the disaster is a damaged disk, a table space backup of each table space on that disk can be used to recover. If you have lost access to a container because of a disk failure (or for any other reason), you can restore the container to a different location. For additional information, see Redefining Table Space Containers During RESTORE .
Both table space backups and full database backups can have a role to play in any disaster recovery plan. The DB2 facilities available for backing up, restoring, and rolling forward data provide a foundation for a disaster recovery plan. You should ensure that you have tested recovery procedures in place to protect your business.
To reduce the probability of media failure, and to simplify recovery from this type of failure:
If you are concerned about the possibility of damaged data or logs due to a disk crash, consider the use of some form of disk fault tolerance. Generally, this is accomplished through the use of a disk array. A disk array consists of a collection of disk drives that appear as a single large disk drive to an application.
Disk arrays involve disk striping, which is the distribution of a file across multiple disks, the mirroring of disks, and data parity checks.
Disk arrays are sometimes referred to simply as RAID (Redundant Array of Independent Disks). The specific term RAID generally applies only to hardware disk arrays. Disk arrays can also be provided through software at the operating system or application level. The point of distinction between hardware and software disk arrays is how CPU processing of I/O requests is handled. For hardware disk arrays, I/O activity is managed by disk controllers; for software disk arrays, this is done by the operating system or an application.
In a RAID disk array, multiple disks are used and managed by a disk controller, complete with its own CPU. All of the logic required to manage the disks forming this array is contained on the disk controller; therefore, this implementation is operating system independent.
There are five types of RAID architecture, RAID-1 through RAID-5, and each provides disk fault tolerance. Each varies in function and performance. In general, RAID refers to a redundant array. RAID-0, which provides only data striping (and not fault-tolerant redundancy), is excluded from this discussion. Although the RAID specification defines five architectures, only RAID-1 and RAID-5 are typically used today.
RAID-1 is also known as disk mirroring or duplexing. Disk mirroring duplicates data (a complete file) from one disk onto a second disk, using a single disk controller. Disk duplexing is the same as disk mirroring, except that disks are attached to a second disk controller (like two SCSI adapters). Data protection is good. Either disk can fail, and data is still accessible from the other disk. With duplexing, a disk controller can also fail without compromising data protection. Performance with RAID-1 is also good, but the trade-off in this implementation is that the required disk capacity is twice that of the actual amount of data, because data is duplicated on pairs of drives.
RAID-5 involves data and parity striping by sectors, across all disks. Parity is interleaved with data information, rather than stored on a dedicated drive. Data protection is good. If any disk fails, the data can still be accessed by using the information from the other disks, along with the striped parity information. Read performance is good, though write performance is considerably worse than that of RAID-1 or normal disk. A RAID-5 configuration requires a minimum of three identical disks. The amount of extra disk space required for overhead varies with the number of disks in the array. In the case of a RAID-5 configuration of 5 disks, the space overhead is 20 percent.
When using a RAID (but not RAID-0) disk array, a failed disk will not prevent you from accessing data on the array. When hot-pluggable or hot-swappable disks are used in the array, a replacement disk can be swapped with the failed disk while the array is in use. With RAID-5, if two disks fail at the same time, all data is lost (but the probability of simultaneous disk failures is very small).
You might consider using RAID-1 or software-mirrored disks (see Software Disk Arrays) for your logs, because this provides for recoverability to the point of failure, and offers good write performance, which is important for logs. In cases where reliability is critical (time cannot be lost recovering data following a disk failure), and write performance is not so critical, consider using RAID-5 disks. Alternatively, if write performance is critical, and you are willing to achieve this despite the cost of additional disk space, consider RAID-1 for your data, as well as for the logs.
A software disk array accomplishes much the same as does a hardware disk array (see Hardware Disk Arrays (RAID)), but the management of disk traffic is done by either an operating system task, or an application program running on the server. Like other programs, the software array must contend for CPU and system resources. This is not a good option for a CPU-constrained system, and it should be remembered that overall disk array performance is dependent on the server's CPU load and capacity.
A typical software disk array provides disk mirroring (see Hardware Disk Arrays (RAID)). Although redundant disks are required, a software disk array is comparatively inexpensive to implement, because costly RAID disk controllers are not required.
| Note: | Having the operating system boot drive in the disk array prevents your system from starting if that drive fails. If the drive fails before the disk array is running, the disk array cannot allow access to the drive. A boot drive should be separate from the disk array. |
To reduce the impact of a transaction failure, try to ensure:
You should maintain relatively synchronized system clocks across the database partition servers to ensure smooth database operations and unlimited forward recoverability. Time differences among the database partition servers, plus any potential operational and communications delays for a transaction should be less than the value specified for the max_time_diff (maximum time difference among nodes) database manager configuration parameter.
To ensure that the log record time stamps reflect the sequence of transactions in a partitioned database system, DB2 uses the system clock on each machine as the basis for the time stamps in the log records. If, however, the system clock is set ahead, the log clock is automatically set ahead with it. Although the system clock can be set back, the clock for the logs cannot, and remains at the same advanced time until the system clock matches this time. The clocks are then in synchrony. The implication of this is that a short term system clock error on a database node can have a long lasting effect on the time stamps of database logs.
For example, assume that the system clock on database partition server A is mistakenly set to November 7, 1999 when the year is 1997, and assume that the mistake is corrected after an update transaction is committed in the partition at that database partition server. If the database is in continual use, and is regularly updated over time, any point between November 7, 1997 and November 7, 1999 is virtually unreachable through roll-forward recovery. When the COMMIT on database partition server A completes, the time stamp in the database log is set to 1999, and the log clock remains at November 7, 1999 until the system clock matches this time. If you attempt to roll forward to a point in time within this time frame, the operation will stop at the first time stamp that is beyond the specified stop point, which is November 7, 1997.
Although DB2 cannot control updates to the system clock, the max_time_diff database manager configuration parameter reduces the chances of this type of problem occurring:
To correct and prevent an incorrect time stamp in a database log from being propagated further:
After you complete these actions, the log time will be adjusted, the incorrect time stamp will not be propagated, and you will be able to do point-in-time recovery from the last backup taken on the database partition.