When working with the performance of the database operations for DB2, you need some understanding of the rudimentary concepts involving the DB2 architecture and processes. This chapter presents sufficient information to provide you with information on how DB2 Universal Database works. While later chapters provide greater detail on some of the topics found here, what is shown in this chapter creates the context for later understanding.
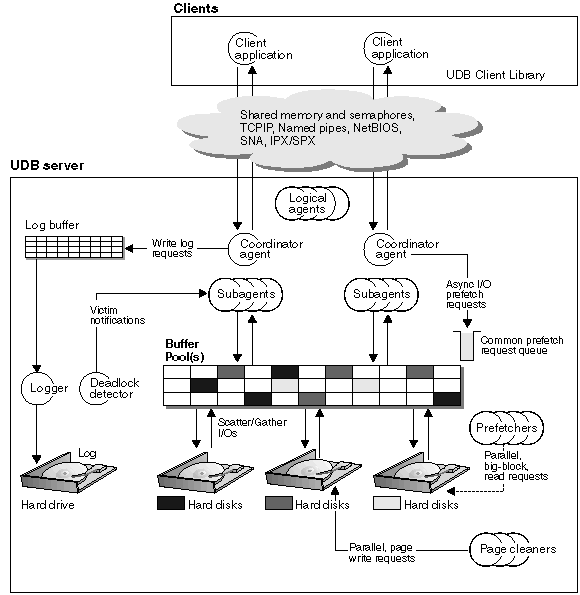
The first figure shows an overview of the architecture and processes for DB2 UDB.
Figure 67. Architecture and Processes Overview
|
On the client-side, there are local and/or remote applications that are linked with the DB2 Universal Database client library.
Between the clients and the DB2 Universal Database server is a "cloud" representing the means of communication between the local or remote clients, and the server. Local clients communicate using shared memory and semaphores; remote clients use a protocol such as Named Pipes (NPIPE), TCP/IP, NetBIOS, IPX/SPX, or SNA.
On the server-side, activity is controlled by engine dispatchable units (EDUs). In all figures in this chapter, EDUs are shown as circles or groups of circles. EDUs are implemented as threads on Windows NT and on OS/2 (all within a single process), and as processes on UNIX. The most common type of EDUs are DB2 agents. These EDUs carry out the bulk of the SQL processing on behalf of applications. Other examples of EDUs are the DB2 prefetchers and page cleaners which are responsible for various types of I/O processing. See Database Agents for more information.
Each client application is assigned a unique EDU called a "coordinator agent" which coordinates the processing for that application and communicates with it. There may also be a set of subagents assigned together to work on processing the client application requests. Multiple subagents maybe assigned so that if the machine where the server resides has multiple processors, like in a symmetric multiprocessing environment, the client application requests can exploit those processors.
All agents and subagents are managed using a pooling algorithm which minimizes the creation and/or destruction of EDUs.
A buffer pool is an area of storage memory where database pages of user table data, index data, and catalog data are temporarily moved and perhaps modified. The buffer pool is a key influencer of overall database performance because data can be accessed much faster from memory than from a disk. If more of the data needed by applications were present in the buffer pool then less time would be needed to access this data compared to time taken to find the data out on disk storage. See Managing the Database Buffer Pool for more information.
The configuration of the buffer pool, along with prefetcher and page cleaner EDUs, control the availability of the data needed by the applications.
The prefetchers are present to retrieve data from disk and move it into the buffer pool before applications need the data. For example, applications needing to scan through large volumes of data would have to wait for data to be moved from disk into the buffer pool if there were no data prefetchers. Agents of the application send asynchronous read-ahead requests to a common prefetch queue. As prefetchers become available, they implement those requests by using big-block or scatter read input operations to bring the requested pages from disk to the buffer pool. Having multiple disks for storage of the database data means that the data can be striped across the disks. This striping of data enables the prefetchers to use multiple disks at the same time to retrieve data. See Prefetching Data into the Buffer Pool and Configuring I/O Servers for Prefetching and Parallel I/O for more information.
Prefetchers are used to bring data into the buffer pool. Page cleaners are used to move data from the buffer pool back out to disk.
Page cleaners are background EDUs, independent of the application agents, that look for, and write out, pages from the buffer pool that are no longer needed. Page cleaners can ensure that there is room in the buffer pool for the pages being retrieved by the prefetchers.
Without the existence of the independent prefetchers and page cleaner EDUs, the application agents would have to do all of the reading and writing of data between the buffer pool and disk storage.
With multiple applications working with data from the database there are opportunities for a "deadlock" to occur between two or more applications. A deadlock is illustrated in the following figure.
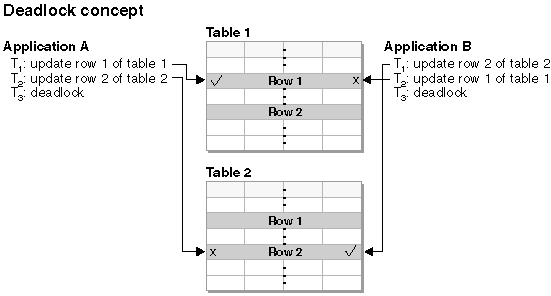 |
A "deadlock" means that more than one application is waiting for another application to release a lock on data. Each of the waiting applications is holding data needed by other applications through locking. This locked data is required by one or more other applications which are, in turn, holding data needed by other applications. Mutual waiting for the other application to release a lock on held data leads to a deadlock: The applications can wait forever until the "other" application releases the lock on the held data. The other applications do not voluntarily release locks on data that they need. A process is required to break these deadlock situations.
As its name suggests, the deadlock detector monitors the information about agents waiting on locks. The deadlock detector arbitrarily selects one of the applications in the deadlock to release the locks currently held by the "volunteered" application. By releasing the locks of that application, the data required by other waiting applications is made available for use. The formerly waiting applications are then free to use the data required to complete actions on data in the database.
Changes to data pages in the buffer pool are logged. A log buffer exists and is associated with a logger EDU. Agents updating a data record in the database update the associated page in the buffer pool and write a log record. The log record contains the information necessary to either redo or undo the change. Neither the page in the buffer pool nor the log record in the log buffer are written to disk immediately to optimize performance. The logger EDU and the buffer pool manager cooperate to implement a Write Ahead Logging (WAL) protocol that ensures that the data page is not written to disk before its associated log record is written to the log. The WAL protocol ensures that there is always enough information in the log to recover from a crash and to restore database consistency. If an uncommitted update on a page was written to a disk, crash recovery uses the undo information in the associated log record to undo the update. If a committed update did not make it to disk, crash recovery uses the redo information in the associated log record to redo the update.
| Note: | On a COMMIT, all log records in the transaction are flushed to disk, if they were not already flushed. |