The following is a checklist of factors that can influence the planning of your archive and recovery strategy:
Taking into account the factors from the list above, some decisions should be made how you run your database and how you define your recovery strategy:
The following paragraphs outline considerations related to selected items of the lists above.
Type of Data
Some differences in backup could apply if the main purpose of the data residing in the database is statistics or running queries to determine trends, if the data is imported from somewhere else.
You can consider to reduce the frequency of backup when data is just history data and has very few updates.
You can consider even to omit regular backups, when the data is unimportant or reproducible:
Database Size
The backup strategy for a very large database is completely different from that for a small database. For a large one, online archives could lead to a checkpoint during the archive process preventing the users from work, so offline archives might be better suited, and if they take too long, it might even be not possible to perform an archive every day. The incremental backup can be a very efficient way of processing a BACKUP of such a database, by only saving modified pages, that represent a very small percentage of the database. For a small database, daily online archives can be made, even a Data Restore BACKUP to disk could be realistic, or just creating an image copy on a different set of disks; DDR disk to disk is very quick and can be an intermediate step before copying to tape.
Data Manipulation: Frequent Updates
If the data is very important and updated often, it is recommended to increase the size of the log disk, so that the interval between archives or log archives could be increased. For LOGMODE=L you should consider that for frequent updates it can take a very long time to apply forward recovery.
Type of Archive
Before the archive enhancements in SQL/DS V3R5 a tendency was to take user archives. Now that DB2 archive performance is improved, it gives you the possibility to choose between DB2 ARCHIVE and Data Restore BACKUP. The Data Restore BACKUP can be FULL (the whole database is saved) or INCREMENTAL (only modified pages from the last FULL archive are saved).
Archive Medium
For Data Restore BACKUP, user archives and (in VM) log archives, you have to decide whether to make them to disk or tape. To disk might be faster when using DDR or similar tools; with BACKUP we measured a better performance to tape. For the purpose of disaster recovery, backup to tape is required. For DB2 ARCHIVE only tape is supported.
The interval between archives and log archives depends on the frequency of data modifications in your database and the allocated size for the log disk. This should influence your decision which logmode you choose. With log archives (LOGMODE=L) often the interval between archives is increased. If you choose this, consider that for frequent updates it can take a very long time to apply forward recovery. Therefore, it is a good strategy to try to reduce the interval between archives. If time allows and if your archive procedure is fully or almost fully automated, this can be easy.
Additionally, make archives at certain points in time as described on page ***.
Archive Online or Offline
Using DB2 ARCHIVE, you can choose to perform online because its speed has improved in SQL/DS V3R5. For disaster recovery and for restoring a back level archive in LOGMODE=A, you might want to make offline archives from time to time, see page ***. For Data Restore BACKUP and user archives you have no choice; they must be taken offline.
Directory Verification
Whenever you perform an SQLEND, do it with the parameter DVERIFY to verify the directory. After larger updates of the database you might want to take the database manager offline just for the purpose of the database verification, as described in Directory Disk Failure.
Archive Sets
You should decide how many archive sets will be kept, before re-using the tapes. The number of tapes belonging to each set could be the main factor that influences this number of archive sets. As mentioned before, there might be some need to restore an older archive set due to a problem already present on the latest archive. If LOGMODE=L is used, all intermediate log files should also be available for this restore.
For example, if you are running your database in LOGMODE=L and you take archives every other day and log archives daily, you might want to keep archives and log archives for one week, and additionally the first (offline) archive of every month for one year.
For LOGMODE=A, an online archive can only be used if this is the newest one because online archives need the current log to become consistent. When you restore an older archive, you must choose one that has been taken offline.
For more information about log recovery after RESTORE of a storage pool, refer to Log Recovery.
Logging
The log archive takes less time than a full database archive. In VM it is possible to create log archives on disk.
There are some advantages creating log archives on disk instead of tape:
You must decide whether you need the log archives even in case of disaster recovery; if so, you need a tape copy.
When you update large amounts of data with DATALOAD or RELOAD in multiple user mode, log consumption can be high. This can be avoided by running DBSU in single user mode with LOGMODE=N. Or, for DATALOAD, you can specify the COMMITCOUNT option together with LOGMODE=Y in multiple user mode.
Dual Log
The database manager requires at least one log disk and supports dual logging. Dual logging is recommended when high availability of the database is required because it helps to recover from log disk failures. Especially in VSE, where there is no additional copy of the log history file, this option is recommended.
In VM, make sure that the two log disks and the 191 disk of the database are on different DASDs.
In VSE, make sure that the two log extents (clusters) not only reside on different volumes (DASDs), but also in different VSAM catalogs in case of a catalog error.
LOGMODE
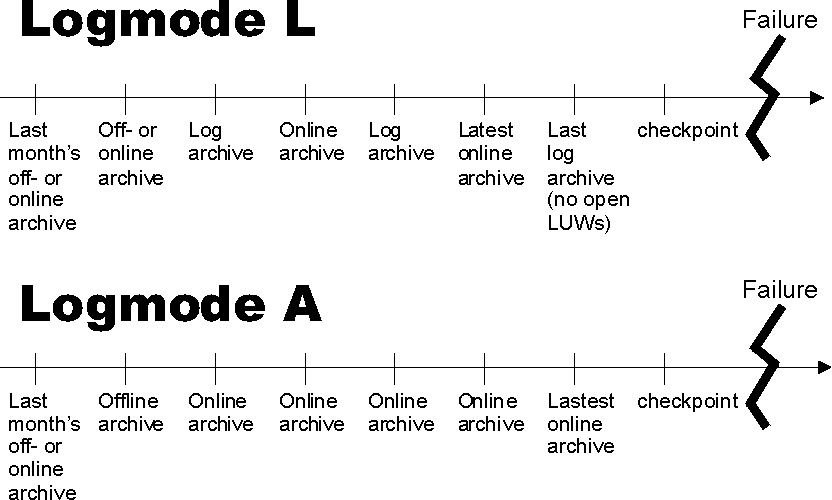
It should be decided, whether LOGMODE=A or LOGMODE=L will be used, because if a restore of the complete database is requested, it can take some time to apply all log files starting from the last archive.
In LOGMODE=L an online archive can be used for disaster recovery or to restore an older level of archive; in LOGMODE=A, for these two cases only offline archives can be used, as described in Recover from System Failure.
Log Size
A useful approach to calculate the size of your log is to estimate the percentage of data that will be generated, deleted, and changed over one archive period. You can estimate the log space requirement with the following calculation:
logsize estimate = (percentage generated
+ percentage deleted
+ percentage changed x 2) x database size
Checkpoint Interval
The database manager takes periodic checkpoints depending on the startup parameter CHKINTVL. This parameter defines how many log pages are to be written before DB2 automatically takes a checkpoint. A checkpoint record is written to the log to synchronize the log with the state of the database. The checkpoint parameter CHKINTVL controls the duration between checkpoints. Many installations find that the optimum CHKINTVL setting is between 50 and 300. Installations with small databases tend to be in the upper end of that range. Try to adjust the startup parameter CHKINTVL to have one checkpoint taken every 15 minutes.
If DB2 archives are taken online, you normally choose times of low activity. However, because your users want to continue to work, the CHKINTVL must be chosen large enough to avoid that during the archive another checkpoint (than the one at the beginning of the archive) will be requested; when that happens, your users will be forced to wait until the archive is finished.
|
Depending on your recovery strategy for your complete system, you will have to determine additional archiving steps. If your recovery procedure includes the ability to move your complete operating environment to a different system, for example in an IBM Backup and Recovery Center, and you can rely on regular backups taken, you need not worry about database definition files.
If this is not planned but your database should be able to be restarted on a different system, for example, with remote applications accessing your database, you need to keep an actual copy of your database definition files together with your archives.
All archives, log archives and files must reside on tapes for use on a different system.
When you are running in LOGMODE=A and performing regular online archives, you should consider to make additional offline archives (of any type) with a lower frequency, which might be acceptable for disaster recovery (see page ***). If a lower frequency even for the case of a disaster is not acceptable, you can run your database with LOGMODE=L, make log archives to tape, and after each one:
For more details, see Recover from System Failure.
When the database is restored after a failure, it represents the contents of a certain point in time backward from the failure; ideally this would be the moment immediately before the failure.
Depending on:
you must choose the archive frequency, the logmode, and whether you perform archives online or offline.
Consider the following sequence of events, as shown in Figure 1.