The following topics are covered in this section:
Applications that rely on a highly available DB2 instance must be able to reconnect in the event of a failover. Since the host name and IP address of a logical host remain the same, there is no need to connect to a different host name or to recatalog the database.
Consider a cluster with two machines and one DB2 Universal Database Enterprise Edition (EE) instance. The EE instance will normally reside on one of the machines in the cluster. Clients of the HA instance will connect to the logical IP address (or host name) of the logical host associated with the HA instance.
According to an HA client, there are two types of failover. One type occurs if the machine that is hosting the HA instance crashes. The other type occurs when the HA instance is given an opportunity to shut down gracefully.
If a machine crashes and takes down the HA instance, both existing connections and new connections to the database will hang. The connections hang because there are no machines on the network with the IP address that the clients were using for the database. If the database is shut down gracefully, a db2stop force breaks existing connections to the database, and an error message is returned.
During the failover, the logical IP address associated with the database is offline, either because the SC2.2 software took it offline, or because the machine that was hosting the logical host crashed. At this point, any new connections to the database will hang for a short period of time.
The logical IP address associated with the database is eventually brought up on another machine before DB2 is started. At this stage, a connection to the database will not hang, but will receive a communication error, because DB2 has not yet been started on the system. DB2 clients that were still connected to the database will also begin receiving communication errors. Although the clients still believe they are connected, the machine that has started hosting the logical IP address has no knowledge of any existing connections. The connections are simply reset, and the DB2 client receives a communication error. After a short time, DB2 will be started on the machine, and a successful connection to the database can be made. At this point, the database may be inconsistent, and clients may have to wait for it to recover.
When designing an application for an HA environment, it is not necessary to write special code for the stages where the database connections hang. The connections only hang for a short period of time while the Sun Cluster software moves the logical IP address. Any data service running on Sun Cluster will experience the same hanging connections during this stage. No matter how the database comes down, the clients will receive an error message, and must try to reconnect until successful. From the client's perspective, it is as if the HA instance went down, and was brought back up on the same machine. In a controlled failover, it appears to the client that it was forced off, and that it can later reconnect to the database on the same machine. In an uncontrolled failover, it appears to the client that the database server crashed, and was soon brought back up on the same machine.
DB2 expects the disk devices or file systems it requires to appear the same on each machine in the cluster. To ensure that this happens, the required disks or file systems should be configured in such a way that they follow the logical host associated with the HA instance, and will have the same path names on each machine in the cluster.
Both DMS and SMS table spaces are supported in an HA environment. Device containers for DMS table spaces must use raw devices created by the volume manager, which are either mirrored, or in a RAID configuration. Regular disk devices, such as /dev/rdsk/c20t0d0s0 should not be used because:
If DB2 is failed over in this situation, the disk devices it requires will not look the same as they did on the other machine, and it will not start. File containers for DMS table spaces, and containers for SMS table spaces, must reside on mounted file systems. The file systems for a logical host are mounted automatically when they are included in the vfstab file for the logical host.
The vfstab file for a logical host is in the path:
/etc/opt/SUNWcluster/conf/hanfs/vfstab.<logical_host>
where logical_host is the name of the logical host that is associated with the vfstab file.
Each logical host has its own vfstab file, which contains file systems that are to be mounted after the disk groups for the logical host have been transferred to the current machine, but before the HA services are started. The Sun Cluster software will try to mount any file system that is properly defined after running fsck (file system check), to ensure the health of the file system. If fsck fails, the file system will not be mounted, and an error message is logged.
| Note: | If a process has an open file, or its current working directory is under a mount point, the mount will fail. To prevent this, ensure that no processes are left under the mount points contained in the logical host's vfstab file. |
Any convention can be used for the file system layout of an EEE instance when using SMS table spaces. Following is the convention used by the hadb2_setup utility:
scadmin@crackle(190)# pwd /export/ha_home/db2eee/db2eee scadmin@crackle(191)# ls -l total 18 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0000 -> /log0/disks/db2eee/NODE0000 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0001 -> /log0/disks/db2eee/NODE0001 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0002 -> /log0/disks/db2eee/NODE0002 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0003 -> /log0/disks/db2eee/NODE0003 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0004 -> /log0/disks/db2eee/NODE0004 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0005 -> /log1/disks/db2eee/NODE0005 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0006 -> /log1/disks/db2eee/NODE0006 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0007 -> /log1/disks/db2eee/NODE0007 lrwxrwxrwx 1 root build 28 Aug 12 19:08 NODE0008 -> /log1/disks/db2eee/NODE0008 scadmin@crackle(192)#
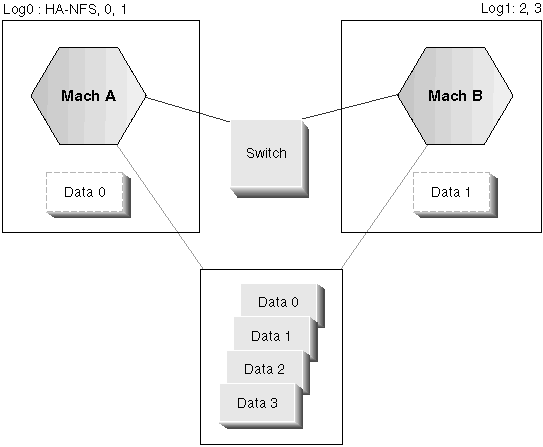
The instance owner is db2eee, and the default database directory for the db2eee instance is /export/ha_home/db2eee. Logical host log0 is hosting database partitions 0, 1, 2, and 3, while logical host log1 is hosting database partitions 4, 5, 6, 7, and 8.
For each database partition, there is a corresponding NODExxxx directory. The node directories for the database partitions point to a directory under the associated logical host file system.
When choosing a path convention, ensure that:
For an EE instance, the home directory should be a file system that is defined in the vfstab file for a logical host. This directory will be available before DB2 is started, and is transferred with DB2 to wherever the logical host is moved in the cluster. Each machine has its own copy of the vfstab file, and care should be taken to ensure that it has the same contents on each machine. Following is an example of the home directory for an EE instance:
/log0/home/db2ee
where /log0 is the logical host file system for the logical host log0, and db2ee is the name of the DB2 instance. This home directory path should be placed in the /etc/passwd file on each machine in the cluster that could host the "db2ee" instance.
For an EEE instance, there are two ways to set up the home directory. For a hot standby configuration, the home directory can be set up in the same way as for an EE instance. For a mutual takeover configuration, HA-NFS must be used for the home directory, and must be configured properly before setting up the EEE instance.
One of the machines in the cluster must export the file system for the EEE instance, using the dfstab file for a chosen logical host. The dfstab file contains file systems that should be exported through NFS when a machine is hosting a logical host. Each machine has its own copy of the dfstab file, and care should be taken to ensure that it has the same contents on each machine.
Information for the HA-NFS file system is placed in the hadb2tab file (through the hadb2_setup program). When an HA agent reads the information for the instance, it automatically mounts the HA-NFS file system for the instance (see The hadb2tab File).
The mount point for the HA-NFS file system is typically /export/ha_home. On each machine in the cluster, this would be NFS mounted from the logical host that is exporting the HA-NFS directory. The EEE instance owner's home directory is placed under this directory and is called:
/export/ha_home/<instance>
where instance is the name of the instance owner.
One could have a home directory for an instance on each machine, to avoid having to mount or unmount it. Doing this requires extra administrative overhead to ensure that the home directories remain identical on each machine. Failure to do so can prevent DB2 from starting properly, or cause it to start with a different configuration. This is not a supported configuration.
A logical host is usually chosen to host one or more database partitions, as well as export the HA-NFS file system. For example, if there are four database partitions and two machines in the cluster, there should be one logical host for each machine (Figure 119). One logical host could host two database partitions, and export the HA-NFS file system, while the other logical host could host the remaining two database partitions.
By default, a DB2 UDB EEE instance allocates enough resources to successfully add up to two database partitions to a machine that already has one or more live database partitions for that instance. For example, if there are four database partitions for a single instance on a cluster, this will only be a concern if there is one database partition per logical host, or one logical host is hosting three database partitions. In either case, it is possible to have three database partitions fail over to a machine that is already hosting a database partition for the same instance.
The DB2_NUM_FAILOVER_NODES registry variable can be used to increase the amount of resource reserved for database partitions that are failed over.
Figure 119. One Logical Host For Each Machine
The file system on which DB2 is installed should be mirrored, or at least be in a RAID configuration. If DB2 is installed on regular disks, disk failure is more likely; the resulting failover is considered preventable, and decreases the stability of the cluster.
DB2 cannot be installed on disks in a disk group for a logical host, because the HA agent always needs to have access to the DB2 libraries. If the HA agents do not have access to the DB2 libraries, they will fail. DB2 must be installed normally on each machine in the cluster.
The database manager configuration parameters can be changed after a failover, and before DB2 is started, by using the pre_db2start script (see User Scripts). This executable script is run (if it exists) under the sqllib/ha directory of the instance owner's home directory. As the name suggests, it is run just before db2start. The same arguments that are passed to the control methods are passed to the pre_db2start script, unless the instance is an EEE instance. For an EEE instance, the pre_db2start script is also passed the node number for the db2start command.
Crash recovery in an HA environment is the same as it would in a regular environment. Even if the HA instance is brought up on a different machine from the one on which it crashed, the files and disk devices for the instance will look the same, and the actions needed to recover the database will not be different. For more information about crash recovery and other forms of database recovery, see Chapter 19, Recovering a Database .
Although a database can be restarted manually (or through one of the user scripts), it is recommended that the autorestart database configuration parameter be set to ON, especially for an EEE instance. This will minimize the amount of time that the database is in an inconsistent state.
Data availability can also be enhanced through replication. By replicating data between two servers, a form of high availability is achieved. If one of the servers goes down, the other server should be able to take over and continue to provide the data service.
However, because the replication is done asynchronously, some changes may not have been propagated to the other server when that server goes down.