Following the creation of a database, the creation of a table space, the creation of a table, and the placing of data into the table, it is interesting to know how the table is organized and how indexes are used to retrieve that table data.
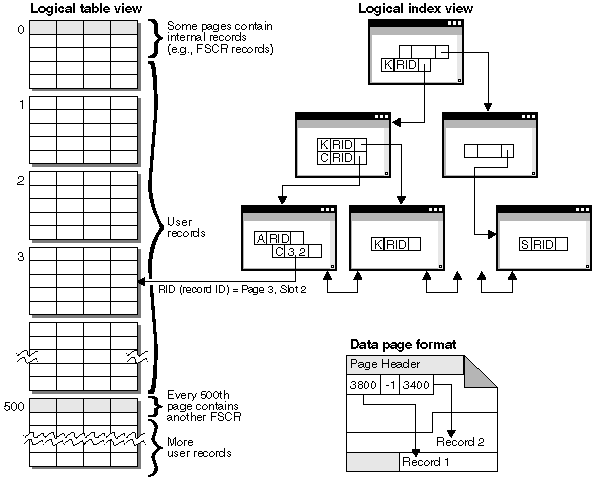
Figure 70. Tables, Records, and Indexes
|
Logically, table data is organized as a list of data pages. And these data pages are logically grouped together based on the extent size of the table space. For example, if the extent size is four, pages zero to three are part of the first extent, pages four to seven are part of the second extent, and so on.
The number of records contained within each data page can vary based on the size of the data page and the size of the records. A maximum of 255 records can fit on one page. Most pages contain only user records. However, a small number of pages include special internal records, that are used by DB2 to manage the table. For example, there is a Free Space Control Record (FSCR) on every 500th data page. These records map out how much free space for new records exists on each of the following 500 data pages (until the next FSCR). This available free space is used when inserting records into the table.
Logically, index pages are organized as a B-tree which can efficiently locate records in the table data which have a given key value. The number of entities on an index page is not fixed but depends on the size of the key. For tables in DMS table spaces, record identifiers (RIDs) in the index pages use table space-relative page numbers, not object-relative page numbers. This allows an index scan to directly access the data pages without requiring an Extent Map page (EMP) for mapping.
Each data page has the following format: A page header begins each data page. After the page header there is a slot directory. Each entry in the slot directory corresponds to a different record on the page. The entry itself is the byte-offset into the data page where the record begins. Entries of minus one (-1) correspond to deleted records.
Record identifiers (RIDs) are a three-byte page number followed by a one-byte slot number. Once the index is used to identify a RID, the RID is used to get to the correct data page and slot number on that page. The contents of the slot is the byte-offset within the page to the beginning of the record being sought. Once a record is assigned a RID, it does not change until a table reorganization.
Figure 71. Data Page and RID Format
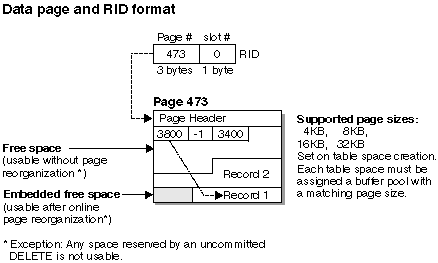 |
When a table is reorganized, embedded free space that is left on the data page following the deletion of a record is converted to usable free space. RIDs are redefined based on movement of records on a data page to take advantage of the usable free space.
DB2 supports different page sizes. Use larger page sizes for workloads that tend to access rows sequentially. For example, sequential access is used for Decision Support applications or where temporary tables are extensively used. Use smaller page sizes for workloads that tend to be more random in their access. For example, random access is used in OLTP-environments.
For more information on reorganizing a table, see Reorganizing Catalogs and User Tables.
You use the SQL INSERT statement to place new information into a table. When you do this, there is an INSERT search algorithm that is followed to complete the work. First the Free Space Control Records (FSCRs) are used to find a page with enough space. However, even when the FSCR says a page has enough free space, the space may not be usable because it is "reserved" by an uncommitted DELETE from another transaction. As a result, you should ensure that all transactions COMMIT frequently otherwise uncommitted freed space will not be usable.
Not all FSCRs in a table are searched. The DB2MAXFSCRSEARCH registry variable limits the number of FSCRs considered when attempting an INSERT. The default value for this registry variable is five. If no space is found within five FSCRs, then the record being inserting is appended to the end of the table. And, to optimize INSERT speed, subsequent records are also appended to the end of the table until two extents are filled. Once the two extents are filled, the next INSERT resumes searching at the FSCR where the last search ended.
| Note: | The value of DB2MAXFSCRSEARCH is important. To optimize for INSERT speed (at the possible expense of quicker table growth), set this registry variable to a small value. To optimize for space reuse (at the possible expense of INSERT speed), set this registry variable to a large value. |
Once the entire table is searched, the record to be inserted will be appended without additional searching. Searching using the FSCRs is not done again until space is created some where in the table (following a DELETE, for example).
There are two other search algorithm options. The first is APPEND MODE. In this mode, new rows are always appended to the end of the table. No searching or maintenance of FSCRs takes places. This option is enabled using the ALTER TABLE APPEND ON statement, and can increase performance for tables that only grow, like journals. The second choice is to define a clustering index on the table. In this case, the database manager attempts to insert records on the same page as other records with similar index key values. If there is no space on that page, the attempt is made to put the record into the surrounding pages. If there is still no success, the FSCR search algorithm, described above, is used - with one small difference: a worst-fit approach is used rather than a first-fit approach. This worst-fit approach tends to choose pages with more free space. This is done to establish a new clustering area for rows with this key value.
When you define a clustering index on a table, use ALTER TABLE... PCTFREE before either loading or reorganizing the table. The PCTFREE clause leaves the percentage value given as free space on that table's data page after loading and reorganizing. This increases the likelihood that the cluster index operation will find free space on the desired page.
Figure 72. Data Page and Overflow Records
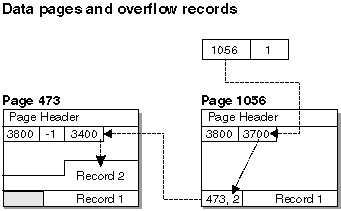 |
Overflow records are possible when an update request enlarges an existing record so that it cannot fit into the current page. The enlarged record is inserted on another page, where there is sufficient room, as an overflow record. The original RID is converted to a pointer record which contains the new RID of the overflow record. The indexes for the table keep the original RID and an extra page read is required to get to the data record requested. Many overflow records means many extra page reads and slower performance accessing the table. Reorganization of the table eliminates overflow records. Whenever possible, however, you should avoid update requests that enlarge records and so avoid overflow records.
DB2 indexes are an optimized B-tree implementation based on an efficient and high concurrency index management method using write-ahead logging.
The optimized B-tree implementation has bi-directional pointers on the leaf pages that allows a single index to support scans in either forward or reverse direction (but not both at the same time). Index page splits are normally right in half except at the high-key page where a 90/10 split is used. That is, the high ten percent of the index keys are placed on a new page. This type of index page split is useful for workloads where INSERT requests are often completed with new high-keys.
Pages in the index are freed when the last index key on the page is removed. The exception to this rule occurs when the MINPCTUSED clause is selected when creating the index. The use of this clause indicates that the index can be reorganized online; and that the value given with this clause is the threshold for the minimum percentage of space used on the index leaf pages. If, after a key is deleted from an index page, the percentage of space used on the page is at or below the value given then an attempt is made to merge the remaining keys with those of a neighboring page. If there is sufficient room, the merge is performed and an index leaf page is deleted. Use of this clause can improve space reuse; however, if the value used is too high then the time taken to attempt a merge increases but also becomes less likely to succeed. It is recommended that the value for this clause always be less than fifty percent.
The INCLUDE clause of the CREATE INDEX statement allows for the inclusion of the specified column(s) on the index leaf pages in addition to the key columns. This can increase the number of queries that are eligible for index-only access. However, this can also increase the index space requirements and, possibly, index maintenance costs if the included columns are updated frequently. Ordering the index B-tree is only done using the key columns and not the included columns.
The database manager provides concurrency control and prevents uncontrolled access to resources and data by means of locks. A lock associates an application with a database manager resource or data record. The lock controls how other applications can access the same resource or data record.
The database manager uses record-level locking or table-level locking as appropriate based on:
Ensure all transactions COMMIT frequently to free held locks.
In general, record-level locking is used unless one of the following is the case:
A lock escalation is the conversion of one or more record locks to a table lock. An exclusive lock escalation is a lock escalation where the table lock acquired is an exclusive lock. Lock escalations reduce concurrency and should be avoided.
The duration of record locking varies with the isolation level being used:
See Locking for more information on this topic.
There are two logging strategy choices:
No matter which choice is made, all changes to regular data and index pages are written to the log buffer. The data in the log buffer is only forced to disk:
| Note: | At the time the transaction completes by using the COMMIT statement, all changed pages are flushed to disk to ensure recoverability. |
When transactions are short, the log I/O can become a "bottleneck" due to the frequency of the flushing of the log at COMMIT time. In such environments, setting the mincommit configuration parameter to a value greater than one can remove the "bottleneck". When a value greater than one is used, the COMMITs for several transactions are held or "batched". The first transaction to COMMIT waits until (mincommit - 1) more transactions COMMIT; and then the log is forced to disk and all transactions respond to their applications. The result is only one log I/O instead of several individual log I/O's.
In order to avoid an excessive degradation in response time, each transaction only waits up to one second for the (mincommit - 1) other transactions to COMMIT. If the one second of time expires, the waiting transaction will force the log itself and respond to its application. This allows you to set mincommit and yet not be too concerned with performance during times of fewer transactions being processed.
Changes to Large Objects (LOBs) and LONG VARCHARs are tracked through shadow paging. LOB column changes are not logged unless log retain is used and the LOB column is defined on the CREATE TABLE statement as not using the NOT LOGGED clause. Changes to allocation pages for LONG or LOB data types are logged like regular data pages.
What happens to the log and to the data page when an agent updates a page? The protocol described here minimizes the I/O required by the transaction and also ensures recoverability.
First, the page to be updated is pinned and latched with an exclusive lock. A log record is written to the log buffer describing how to redo and undo the change. As part of this action, a log sequence number (LSN) is obtained and is stored in the page header of the page being updated. The change is then made to the page. Finally, the page is unlatched and unfixed. The page is considered to be "dirty" because there are changes to the page that have not been written out to disk. The log buffer has also been updated.
Both the data in the log buffer and the "dirty" data page will need to be forced to disk. For the sake of performance, these I/Os are delayed until a convenient point (for example, during a lull in the system load), or until necessary to ensure recoverability, or to bound recovery time. More specifically, a "dirty" page is forced to disk:
A log buffer is forced to disk by the logger engine dispatchable unit (EDU):