This section provides an overview of the following key database objects:
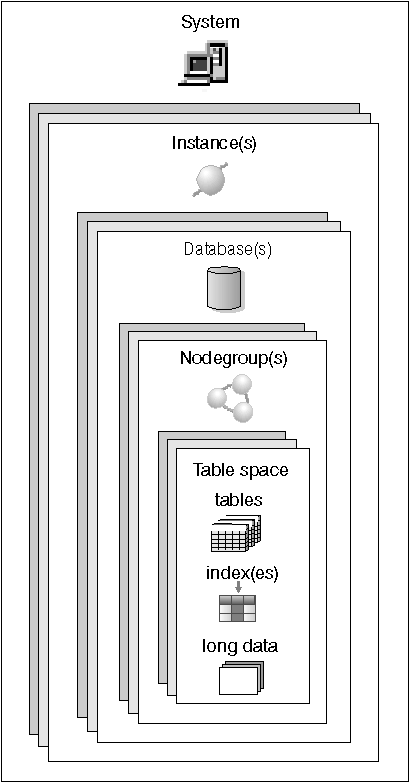
Figure 1 illustrates the relationship among some of these objects. It also shows that tables, indexes, and long data are stored in table spaces.
Figure 1. Relationships Among Some Database Objects
|
An instance (sometimes called a database manager) is DB2 code that manages data. It controls what can be done to the data, and manages system resources assigned to it. Each instance is a complete environment. It contains all the database partitions defined for a given parallel database system (see Chapter 4, Parallel Database Systems). An instance has its own databases (which other instances cannot access), and all its database partitions share the same system directories. It also has separate security from other instances on the same machine (system).
A relational database presents data as a collection of tables. A table consists of a defined number of columns and any number of rows. Each database includes a set of system catalog tables that describe the logical and physical structure of the data, a configuration file containing the parameter values allocated for the database, and a recovery log with ongoing transactions and archivable transactions.
A nodegroup is a set of one or more database partitions. When you want to create tables for the database, you first create the nodegroup where the table spaces will be stored, then you create the table space where the tables will be stored. See Nodegroups and Data Partitioning for more information about nodegroups. See Chapter 4, Parallel Database Systems for the definition of a database partition. See Table Spaces for more information about table spaces.
A relational database presents data as a collection of tables. A table consists of data logically arranged in columns and rows. All database and table data is assigned to table spaces. See Table Spaces for more information about table spaces. The data in the table is logically related, and relationships can be defined between tables. Data can be viewed and manipulated based on mathematical principles and operations called relations.
Table data is accessed through Structured Query Language (SQL, see the SQL Reference), a standardized language for defining and manipulating data in a relational database. A query is used in applications or by users to retrieve data from a database. The query uses SQL to create a statement in the form of
SELECT <data_name> FROM <table_name>
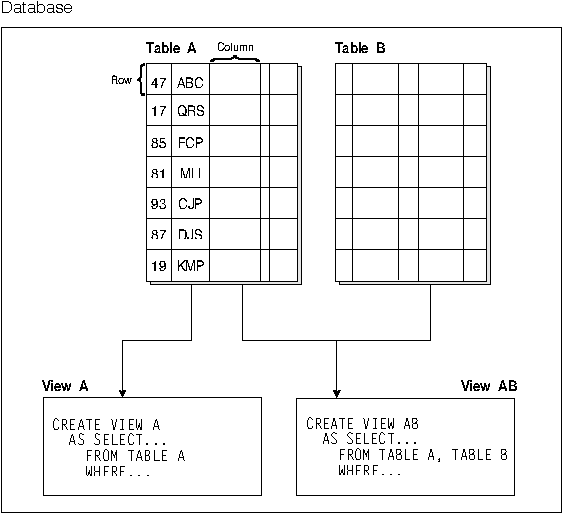
A view is an efficient way of representing data without needing to maintain it. A view is not an actual table and requires no permanent storage. A "virtual table" is created and used.
A view can include all or some of the columns or rows contained in the tables on which it is based. For example, you can join a department table and an employee table in a view, so that you can list all employees in a particular department.
Figure 2 shows the relationship between tables and views.
Figure 2. Relationship Between Tables and Views
 |
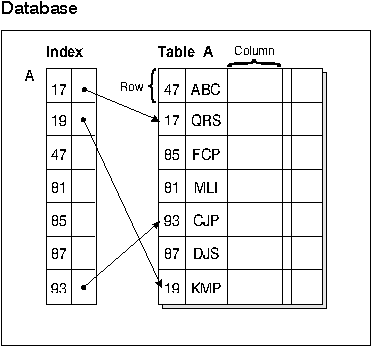
An index is a set of keys, each pointing to rows in a table. For example, table A in Figure 3 has an index based on the employee numbers in the table. This key value provides a pointer to the rows in the table: employee number 19 points to employee KMP. An index allows more efficient access to rows in a table by creating a direct path to the data through pointers.
The SQL optimizer automatically chooses the most efficient way to access data in tables. The optimizer takes indexes into consideration when determining the fastest access path to data.
Unique indexes can be created to ensure uniqueness of the index key. An index key is a column or an ordered collection of columns on which an index is defined. Using a unique index will ensure that the value of each index key in the indexed column or columns is unique. Business Rules for Data describes keys and indexes in more detail.
Figure 3 shows the relationship between an index and a table.
Figure 3. Relationship Between an Index and a Table
 |
A schema is an identifier, such as a user ID, that helps group tables and other database objects. A schema can be owned by an individual, and the owner can control access to the data and the objects within it.
A schema is also an object in the database. It may be created automatically when the first object in a schema is created. Such an object can be anything that can be qualified by a schema name, such as a table, index, view, package, distinct type, function, or trigger. You must have IMPLICIT_SCHEMA authority if the schema is to be created automatically, or you can create the schema explicitly.
A schema name is used as the first part of a two-part object name. When an object is created, you can assign it to a specific schema. If you do not specify a schema, it is assigned to the default schema, which is usually the user ID of the person who created the object. The second part of the name is the name of the object. For example, a user named Smith might have a table named SMITH.PAYROLL.
Each database includes a set of system catalog tables, which describe the logical and physical structure of the data. DB2 creates and maintains an extensive set of system catalog tables for each database. These tables contain information about the definitions of database objects such as user tables, views, and indexes, as well as security information about the authority that users have on these objects. They are created when the database is created, and are updated during the course of normal operation. You cannot explicitly create or drop them, but you can query and view their contents using the catalog views.