
You import metadata into the Data Warehouse Center so that the Data Warehouse Center can extract and transform data for the warehouse or run partner applications that extract and transform data.
Importing metadata into the Data Warehouse Center involves the following tasks:
To build the tag language file:
You can import metadata for the following types of objects into the Data Warehouse Center:
A warehouse agent performs the actual transfer of data between the source database or file (warehouse source), and the target database (warehouse target). It also performs any transformation of that data. The warehouse agent receives commands from the warehouse server. Then, the agent issues SQL commands, starts a partner application, or starts a Data Warehouse Center program that starts a partner application. A warehouse agent can also import table definitions.
An agent site is the machine on which an agent runs. The agent site must have access to the machine that contains the source database and the target database.
A warehouse target or target file is the database or file to which the Data Warehouse Center or a partner application writes the data after processing it. The generic term target means a database or a group of one or more files. A target is associated with one or more tables or files. A table or file is associated with one or more columns or fields. A warehouse target is a subset of tables, or a set of files, that are managed by the Data Warehouse Center.
A warehouse target is the database that contains the warehouse that users will use to run queries and reports.
To define objects that you want to import into the Data Warehouse Center, you build a tag language file from one or more Data Warehouse Center metadata templates.
Each template corresponds to an object, such as a table, or a subset of an object, such as a column. You combine templates to define all the details about an object. For example, if you want to define a source database, you combine database, table, and column templates.
You must write a program that obtains values from the partner metadata store and use these values to replace tokens in the template. This book calls this type of program an interchange program.
Each template contains tokens for which your interchange program must specify values. For example, the token *TableDescription represents the description of a table. Your interchange program would search for *TableDescription and change it to the string that contains the description of the table specified in the relational catalog. For a DB2(TM) Universal Database table, the description is in the REMARKS field of the syscat.tables table of the system catalog. Because your interchange program replaces the tokens with a value, you do not need to know the syntax of the underlying tag language that identifies metadata in the file.
You can choose to install the templates when you install the Application Development Client.
To install the templates:
The default directory for the ISV Toolkit is x:\sqllib\templates. The Data Warehouse Center sets the VWS_TEMPLATES environment variable to the location of the ISV Toolkit. Your program can query the value of VWS_TEMPLATES to locate the templates.
The Data Warehouse Center installs the files in subdirectories of the
directory that is set by VWS_TEMPLATES. Table 2 lists the types of files that are installed and the
subdirectories in which the files are installed.
Table 2. File types and subdirectories for templates
| Type of file | Subdirectory |
|---|---|
| Templates | ISV |
| Samples | Samples |
| Header files | Include |
When you write an interchange program, you need to:
You can also log processing messages in the same directory that the Data Warehouse Center uses to log processing messages.
Use of the ISV_Defines.h header file allows your program logic to stay the same even if the template's tokens change. You simply need to recompile your program.
Your program must use the following procedure to work with the templates:
Use a search and replace methodology, rather than programming to the format of the tag language file. Use of the tokens enables your program to be independent of changes to the tag language that is used in the template file.
In the templates, each token is enclosed in parentheses; the closing parenthesis identifies the end of the value. Your program should substitute values for only the token and not remove the parentheses.
Any string that is to replace a token value must follow the following rules:
For example, if you want to replace the *DatabaseNotes token with the value:
This is my database (managed by the Finance group).
You must change the value to:
This is my database '('managed by the Finance group')'.
If your interchange program does not have a value for a token, it should replace the token with the constant ISV_DEFAULTVALUE (defined in ISV_defines.h). However, you must specify a value other than ISV_DEFAULTVALUE for any token that is required.
Because there is no template for security groups, your program must specify the value ISV_DEFAULTSECURITYGROUP for any instances of the *SecurityGroup token.
The templates use default values for Data Warehouse Center specific metadata. For example, retry count and retry interval for warehouse sources and warehouse targets are set to their Data Warehouse Center default values.
Each template contains a *CurrentCheckPointID++ token, which you can use to track progress when you import the tag language file. When your program sets values for the tokens, it should set the first occurrence of *CurrentCheckPointID++ to 0. Your program should increase the value of *CurrentCheckPointID++ by 1 each time it appears. The Data Warehouse Center will write these checkpoints to the log file as the tag language file is being imported.
Tables Table 3, Table 4, and Table 5 list the order in which your program must append templates to the tag language file. They also provide the conditions under which the template is required or optional.
Except for the header, you can define as many copies of each template as
you need. You must define only one copy of the header in each tag
language file.
Table 3. Relationships between templates and conditions
| Order | Template | Required or optional |
|---|---|---|
| 1 | HeaderInfo.tag | Always required |
| 2 | AgentSite.tag | Required if you do not use the default agent site |
| 3 | VWPGroup.tag | Required if you are defining Data Warehouse Center programs |
| 4 | VWPProgramTemplate.tag | Required if you are defining Data Warehouse Center programs |
| 5 | VWPProgramTemplateParameter.tag | Required if you are defining Data Warehouse Center programs |
| 6 | SourceDataBase.tag
WarehouseDataBase.tag | Required if you are defining warehouse sources or warehouse targets |
| 7 | Table.tag | Required if you are defining warehouse sources or warehouse targets |
| 8 | Column.tag | Required if you are defining warehouse sources or warehouse targets |
After you append the Column.tag template to the tag language file, the series of templates and the order in which the templates are appended to the tag language file depend on whether you want to define a step or a star schema.
If you are defining a step, append the following templates to the tag
language file in the order shown in Table 4.
Table 4. Relationships between templates and conditions when defining a step
| Order | Template | Required or optional |
| 9 | SubjectArea.tag | Required if you are defining steps. |
| 10 | Process.tag | Required if you are defining steps. |
| 11 | Step.tag | Required if you are generating SQL transformations between source and target data or defining programs that the Data Warehouse Center is to execute. |
| 12 | StepInputTable.tag | Required if you are defining a step of type:
ISV_StepType_Editioned_Append ISV_StepType_Full_Replace ISV_StepType_Uneditioned_Append Optional if you are defining a step of type: ISV_StepType_VWP_Population |
| 13 | StepOutputTable.tag | Required if you are defining a step of type:
ISV_StepType_Editioned_Append ISV_StepType_Full_Replace ISV_StepType_Uneditioned_Append
StepOutputTable cannot be used for steps of type: ISV_StepType_VWP_Population |
| 14 | StepVWPOutputTable.tag |
Optionalif you are defining a step of type: ISV_StepType_VWP_Population
|
| 15 | StepCascade.tag | Required in order to link steps in a cascaded relationship |
| 16 | StepVWPProgramInstance.tag | Required if the step uses a Data Warehouse Center program |
| 17 | VWPProgramInstanceParameter.tag | Required if the step uses a Data Warehouse Center program which expects parameters to be passed and has parameters. |
If you are defining a star schema, append the following templates to the
tag language file in the order shown in Table 5.
Table 5. Relationships between templates and conditions for defining a star schema
| Order | Template | Required or optional |
| 9 | StarSchema.tag | Required if you are defining a star schema. |
| 10 | StarSchemaInputTable.tag | Required if you are defining a star schema. |
For detailed information about these templates, see Metadata templates.
Your interchange program can write log processing messages or trace files to the directory that the VWS_LOGGING environment variable specifies. The Data Warehouse Center uses this directory for its log files and its trace files.
To define the objects that a tag language file can contain, you must define the header.
To define the header:
Your program must copy and change the HeaderInfo.tag template file.
Your program must supply the following values:
For information about the tokens in the template, see HeaderInfo.tag.
Figure 3 is a pseudocode example of the logic that your program can use to build the header portion of the tag language file.
Figure 3. Pseudocode for adding the header to the tag language file
Initialize native metadata environment (need to include ISV_defines.h) Read a copy of the HeaderInfo.tag template (from the templates directory) Search for and replace tokens with the metadata from your native metadata store (or defaults) Write the output to a target file |
The ISV_Sample program provides an example of the header portion of the tag language file. You can find the source code for the program in the Samples subdirectory of the directory that is set by the VWS_TEMPLATES environment variable.
You can use one of the following agent site types:
To use an existing agent site, replace all occurrences of the *AgentSite token with the agent site name.
To use the default agent site, replace all occurrences of the *AgentSite token with ISV_DEFAULTAGENTSITE.
To define a new agent site, specify values for the tokens in the AgentSite template. Replace all occurrences of the *AgentSite token with the name of the new agent site.
To define a new agent site:
Your program must copy and change the AgentSite.tag template file. The AgentSite.tag template requires the HeaderInfo.tag template as a prerequisite.
To define a new agent site, your program must obtain metadata about the workstation on which the warehouse agent is installed. Your program must substitute the values that it obtains for the appropriate tokens in the template.
Figure 4 shows a pseudocode example of the logic your program can use to add a new agent site to the tag language file.
Figure 4. Pseudocode example of modifying the AgentSite.tag template
If the ISV wants to create an AgentSite specific to the ISV: Read a copy of the AgentSite.tag template from the template directory Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file Else Set AgentSite token to default agentsite value |
The ISV_Sample program provides an example of adding an agent site that is specific to a partner tool to the tag language file. You can find the source code for the program in the Samples subdirectory of the directory that is set by the VWS_TEMPLATES environment variable.
You define sources if you want the Data Warehouse Center or a partner application to read data from those sources. Similarly, you define targets if you want the Data Warehouse Center or a partner application to write data to those targets. You must define any sources and targets that are used, except under the following conditions:
To define sources and targets:
You can define the following types of source objects:
You can define relational databases as target objects.
Tables Table 6 and Table 7 list the templates that your program must copy and change to define each type of source and target object.
Table 6 lists the templates that your program must copy to
define a relational database.
Table 6. Templates for relational source and target definitions
| Source or target definition | Number of copies of template | Template to copy | Prerequisite template |
|---|---|---|---|
| Database | One copy for each database you want to use | "SourceDataBase.tag" (see page "SourceDataBase.tag")
"WarehouseDataBase.tag" (see page "WarehouseDataBase.tag") | "HeaderInfo.tag" (see page "HeaderInfo.tag")
"AgentSite.tag" (see page "AgentSite.tag") if you are not using the default agent |
| Table | One copy for each table that you want to define in the database | "Table.tag" (see page "Table.tag") | "SourceDataBase.tag" (see page "SourceDataBase.tag")
"WarehouseDataBase.tag" (see page "WarehouseDataBase.tag") |
| Column | One copy for each column that you want to define in each table | "Column.tag" (see page "Column.tag") | "Table.tag" (see page "Table.tag") |
You relate the templates for the tables to the template for the database by specifying common values in the templates. Similarly, you relate templates for the columns to the template for the table by specifying common values in the templates.
Figure 5 shows the relationship between the database, table, and column templates. The 1 to m notation indicates a one to many relationship, where many is inclusive of zero.
Figure 5. Relationship between the DataBase.tag, Table.tag, and Column.tag templates
|
Table 7 lists the templates that your program must copy to
define an IMS database. You must use the Data Warehouse Center ODBC
drivers to access these IMS objects.
Table 7. Templates for IMS source definitions
| Source or target definition | Number of copies of template | Template to copy | Prerequisite template |
|---|---|---|---|
| Database | One copy for each database you want to use | "SourceDataBase.tag" (see page "SourceDataBase.tag") | "HeaderInfo.tag" (see page "HeaderInfo.tag")
"AgentSite.tag" (see page "AgentSite.tag") if you are not using the default agent |
| Segment | One copy for each segment that you want to use in the database | "Table.tag" (see page "Table.tag") | "SourceDataBase.tag" (see page "SourceDataBase.tag") |
| Field | One copy for each field that you want to use in each segment | "Column.tag" (see page "Column.tag") | "Table.tag" (see page "Table.tag") |
You define relationships between the templates for the database, segments, and fields in the same manner that you define relationships for tables. (See Figure 5.)
Table 7 lists the templates that your program must copy to
define either a file system and its associated files, or a single file.
Table 8. Templates for file systems or a single file
| Source or target definition | Number of copies of template | Template to copy | Prerequisite template |
|---|---|---|---|
| File system | One copy for each file system | "SourceDataBase.tag" (see page "SourceDataBase.tag") | "HeaderInfo.tag" (see page "HeaderInfo.tag")
"AgentSite.tag" (see page "AgentSite.tag") if you are not using the default agent |
| File | One copy for each file that you want to use in the file system | "Table.tag" (see page "Table.tag") | "SourceDataBase.tag" (see page "SourceDataBase.tag") |
| Field | One copy for each field that you want to use in each file | "Column.tag" (see page "Column.tag") | "Table.tag" (see page "Table.tag") |
You define relationships between the templates for the file system, files, and fields in the same manner that you define relationships for tables. (See Figure 5.)
Your program must obtain values that describe databases or files from the partner metadata store. Your program must substitute the values that it obtains for the appropriate tokens in the template.
Your program must supply the following metadata about the source databases or the target databases:
Your program must supply the following metadata about the source files:
Figure 6 shows a pseudocode example of the logic that your program can use to create or update data resources for source or target definitions.
Figure 6. Pseudocode for creating or updating data resources for source and target definitions. Use this logic for each source or target definition that you want to create or update.
For each source or target to be defined:
Read a copy of the SourceDatabase.tag or WarehouseDatabase.tag template
Search for and replace tokens with the metadata from your native metadata source
(or defaults)
Append the output to a target file
For each table, file, or segment that is to be defined:
Read a copy of the Table.tag template
Search for and replace tokens with the metadata from your native metadata source
(or defaults)
Append the output to a target file
For each column or field that the table contains:
Read a copy of the Column.tag template
Search for and replace tokens with the metadata from your native metadata source
(or defaults)
Append the output to a target file
End (for each column)
End (for each table)
End (for each source or target data source)
|
The ISV_Sample program provides an example of creating or updating data sources for source or target definitions. You can find the source code for the program in the Samples subdirectory of the directory that is set by the VWS_TEMPLATES environment variable.
If you want the Data Warehouse Center to schedule and run a partner application, you must first define the application as a Data Warehouse Center program. Then you can schedule and run the program by using it in one or more steps.
If your tag language file is to contain Data Warehouse Center programs, you must define the following objects, in order:
You can change the parameters that are used in a particular step by defining an instance of the program parameters for the step. For more information about using a Data Warehouse Center program in a step, see Defining steps.
For information about writing a program for use with the Data Warehouse Center, see Appendix C, Writing your own program to use with the Data Warehouse Center.
To define a Data Warehouse Center program:
Table 9 lists the templates that your program must copy and change
to define Data Warehouse Center programs.
Table 9. Templates for Data Warehouse Center programs
| Definition | Number of copies of template | Template to copy | Prerequisite template |
|---|---|---|---|
| Data Warehouse Center program group | One copy for each program group to define | "VWPGroup.tag" (see page "VWPGroup.tag") | "HeaderInfo.tag" (see page "HeaderInfo.tag") |
| Data Warehouse Center program template | One copy for each Data Warehouse Center program in the program group | "VWPProgramTemplate.tag" (see page "VWPProgramTemplate.tag") | "VWPGroup.tag" (see page "VWPGroup.tag") |
| Data Warehouse Center program template parameter | One copy for each parameter passed to theData Warehouse Center program | "VWPProgramTemplateParameter.tag" (see page "VWPProgramTemplateParameter.tag") | "VWPProgramTemplate.tag" (see page "VWPProgramTemplate.tag") |
You relate the templates for the Data Warehouse Center program group to the template for the Data Warehouse Center program by specifying common values in the templates. Similarly, you relate templates for the parameters to the template for the Data Warehouse Center program by specifying common values in the templates.
Figure 7 shows the relationship between the Data Warehouse Center program group, the Data Warehouse Center program, and the Data Warehouse Center program parameters.
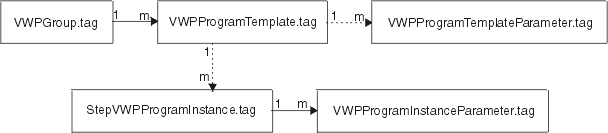 |
For information about relating a Data Warehouse Center program to a step, see Defining steps.
Your program must obtain values that describe the Data Warehouse Center programs from the partner metadata store:
Your program must substitute the values that it obtains for the appropriate tokens in the templates.
Figure 8 shows a pseudocode example of the logic that your program can use to define applications that will be managed and run by the Data Warehouse Center.
Figure 8. Pseudocode for defining Data Warehouse Center programs
Read a copy of the VWPGroup.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file For each application that is to be managed by the Data Warehouse Center: Read a copy of the VWPProgramTemplate.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file For each parameter the application needs passed: Read a copy of the VWPProgramTemplateParameter.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file End (for each parameter) End (for each application) |
The ISV_Sample program provides an example of adding Data Warehouse Center programs to the tag language file. You can find the source code for the program in the Samples subdirectory of the directory that is set by the VWS_TEMPLATES environment variable.
A step is a single operation on data in a warehouse process. In most cases, a step includes a warehouse source, a transformation or movement of data, and a warehouse target. A step can be run according to a schedule, or it can cascade from another step. You use steps to define and schedule each step in the extraction, transformation, and writing of the data. You must define a step for each part of the transformation process that you want the Data Warehouse Center to manage. Use the information in this section to determine how to define your steps, rather than the information in the Data Warehouse Center online help. The templates require different relationships from steps that are defined using the user interface.
You must define a subject area for the steps. You can use subject areas to group steps that use a particular partner application.
If your tag language file contains steps, you must define the following objects, in order:
To define steps:
Table 10 lists the templates that your program must copy and change
to define steps.
| Definition | Number of copies of template | Template to copy | Prerequisite template |
|---|---|---|---|
| Subject area | One copy for each subject area | "SubjectArea.tag" (see page "SubjectArea.tag") | "HeaderInfo.tag" (see page "HeaderInfo.tag")
"AgentSite.tag" (see page "AgentSite.tag") if you are not using the default agent |
| Process | One copy for each process | "Process.tag" (see page "Process.tag") | "SubjectArea.tag"(see page "SubjectArea.tag") |
| Step | One copy for each step | "Step.tag" (see page "Step.tag") | "SubjectArea.tag" (see page "SubjectArea.tag")
"Process.tag" (see page "Process.tag") |
| Source table for the step | One copy for each source table for the step | "StepInputTable.tag" (see page "StepInputTable.tag") | "Table.tag" (see page "Table.tag")
"Step.tag" (see page "Step.tag") "Process.tag" (see page "Process.tag") |
| Target table for the step | One copy if the step has a target table | "StepOutputTable.tag" (see page "StepOutputTable.tag") | "Table.tag" (see page "Table.tag")
"Step.tag" (see page "Step.tag") "Process.tag" (see page "Process.tag") |
| Target table for a step which uses a Data Warehouse Center program | One copy to document each target table updated by the program | "StepOutputTable.tag"(see page "StepOutputTable.tag") | "Table.tag" (see page "Table.tag")
"Step.tag" (see page "Step.tag") |
| Data Warehouse Center program instance | One copy if the step uses a Data Warehouse Center program | "StepVWPProgramInstance.tag"(see page "StepVWPProgramInstance.tag") | "VWPProgramTemplate.tag" (see page "VWPProgramTemplate.tag")
"Step.tag" (see page "Step.tag") |
| Data Warehouse Center program instance parameters | One copy for each parameter used in the step | "VWPProgramInstanceParameter.tag" (see page "VWPProgramInstanceParameter.tag") | "StepVWPProgramInstance.tag"(see page "StepVWPProgramInstance.tag") |
You relate the templates for the subject area to the templates for the process by specifying common values in the templates. Similarly, you relate templates for the steps to the templates for input tables and output tables by specifying common values in the templates. You can also relate the template for the step to a template for the program instance by specifying common values in the templates.
Figure 9 shows the relationship between the subject area, step, stepinput table, stepoutput table, stepVWP program instance, and the VWP program instance parameter tags.
Figure 9. Relationship between the SubjectArea.tag, Process.tag, Step.tag, StepInputTable.tag, StepOutputTable.tag, StepVWPOutputTable.tag,StepVWPProgramInstance.tag, and VWPProgramInstanceParameter.tag templates. See Figure 7 to see how the Data Warehouse Center program instance templates relate to the other Data Warehouse Center program templates.
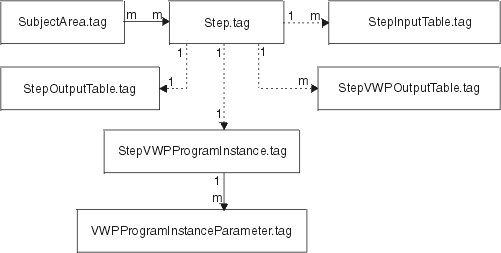 |
Your program must obtain values that describe the subject areas and steps from the partner metadata store:
Your program must substitute the values that it obtains for the appropriate tokens in the templates.
Figure 10 shows pseudocode of the logic that your program can use to define steps in the tag language file.
Figure 10. Pseudocode for defining steps in the tag language file
Read a copy of the SubjectArea.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file Read a copy of the process For each step to be defined: Read a copy of the Step.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file If the step is to execute your application: Read a copy of the StepVWPProgramInstance.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file For each parameter that your application needs: Read a copy of the VWPProgramInstanceParameter.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file End (for each parameter) If the step is to be related to its VWP output target data: Read a copy of the StepVWPOutputTable.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file End (step relation to its output) End (if step to execute your application) If the step is to be related to its input source data: Read a copy of the StepInputTable.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file End (step relation to its source) If the step is to be related to its output target data: Read a copy of the StepOutputTable.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file End (step relation to its target) End (for each step) |
The ISV_Sample program provides an example of adding steps to the tag language file. You can find the source code for the program in the Samples subdirectory of the directory that is set by the VWS_TEMPLATES environment variable.
In your tag language file, you can specify that steps start other steps:
To define the cascading steps:
Table 11 lists the templates that your program must copy and change
to define cascade relationships.
Table 11. Templates for cascade relationships
| Definition | Number of copies of template | Template to copy | Prerequisite template |
|---|---|---|---|
| Step cascade relationship | One copy for each relationship | StepCascade.tag | StepCascade.tag |
Your program must supply the name of a step and the name of another step to:
Your program must substitute the values it obtains for the appropriate tokens in the templates.
Figure 11 shows pseudocode of the logic that your program can use if you want your application to relate two steps together so that one step starts at the completion of another step.
Figure 11. Pseudocode for relating steps for cascaded processing
Read a copy of the StepCascade.tag template Search for and replace tokens with the metadata from your native metadata store (or defaults) Append the output to a target file End (relate steps for cascaded processing) |
The ISV_Sample program provides an example of how to relate steps for cascaded processing in the tag language file. You can find the source code for the program in the Samples subdirectory of the directory that is set by the VWS_TEMPLATES environment variable.
You can import metadata from the tag language file by using a command window or the user interface. This section describes how to use the command window. For information about using the user interface, see the Data Warehouse Center online help.
To import a tag language file, enter the following command at a DOS command prompt:
iwh2imp2 tag-filename log-pathname target-control-db userid password [PREFIX = schema]
If a prefix is not specified, the default value is IWH.
To get help for the import command parameters, enter the command only.
When the import utility imports metadata from a tag language file, it creates a log file with:
The import process records the return code and the last completed checkpoint at the end of the log file.
You can also code the return code into your interchange program by using the system() call or the rexec() call. The call to use depends on the operating system on which your program is running.
For more information about importing metadata into the Data Warehouse Center, see the Data Warehouse Center Administration Guide.
After you import the metadata into the Data Warehouse Center, you must complete the following procedure to set up an automated process for your warehouse:
If you need to make changes:
Be sure to update your program to account for these changes.
Your steps will now run on an automated schedule.