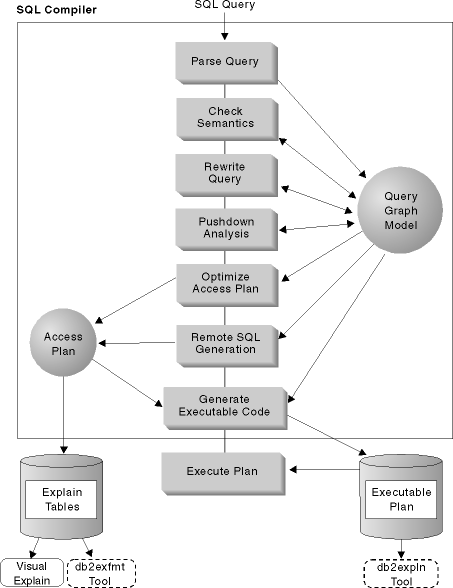

The SQL compiler performs several steps before producing an access plan that you can execute. These steps are shown in Figure 73.
Figure 73. Steps performed by SQL Compiler
|
This diagram shows that the Query Graph Model is a key component of the SQL compiler. The query graph model is an internal, in-memory database that is used to represent the query throughout the query compilation process as described below:
The first task of the SQL compiler is to analyze the SQL query to validate the syntax. If any syntax errors are detected, the SQL compiler stops processing and the appropriate SQL error is returned to the application attempting to compile the SQL statement. When parsing is complete, an internal representation of the query is created.
The second task of the compiler is to further validate the SQL statement by checking to ensure that the parts of the statement make sense given the other parts. A simple example of this semantic checking ensures that the data type of the column specified for the YEAR scalar function is a datetime data type. Also during this second stage, the compiler adds the behavioral semantics to the query graph model, including the effects of referential constraints, table check constraints, triggers, and views.
The query graph model contains all of the semantics of queries, including query blocks, subqueries, correlations, derived tables, expressions, data types, data type conversions, code page conversions, and partitioning keys.
The third phase of the SQL compiler uses the global semantics provided in the query graph model to transform the query into a form that can be optimized more easily. For example, the compiler might move a predicate, altering the level at which it is applied and potentially improving query performance. This type of operation movement is called general predicate pushdown. See Rewrite Query by the SQL Compiler for more information.
Working in a partitioned database environment, some query operations are more computationally intensive like those involving:
In this environment, with some queries, decorrelation can occur as part of the rewrite of the query.
Any transformations that occur on a query are written back to the query graph model. That is, the query graph model represents the rewritten query.
The major task of this step is to recommend to the DB2 optimizer whether an operation can be remotely evaluated ("pushed-down") at a data source. This type of pushdown activity is specific to data source queries and represents an extension to general predicate pushdown operations.
This step is bypassed unless you are executing federated database queries. See Pushdown Analysis for more information.
The SQL optimizer portion of the SQL compiler uses the query graph model as input, and generates many alternative execution plans for satisfying the user's request. It estimates the execution cost of each alternative plan, using the statistics for tables, indexes, columns and functions, and chooses the plan with the smallest estimated execution cost. The optimizer uses the query graph model to analyze the query semantics and to obtain information about a wide variety of factors, including indexes, base tables, derived tables, subqueries, correlations and recursion.
The optimizer portion can also consider a third type of pushdown operation: aggregation and sort, which can improve performance by pushing the evaluation of these operations to the Data Management Services component. See Aggregation and Sort Pushdown Operators for more information.
The optimizer also considers whether there are different sized buffer pools when determining page size selection. That the environment includes a partitioned database is also considered as well as the ability to enhance the chosen plan for the possibility of intra-query parallelism in a symmetric multi-processor (SMP) environment. This information is used by the optimizer to help select the best access plan for the query. See Data Access Concepts and Optimization for more information.
The output from this step of the SQL compiler is an "access plan". This access plan provides the basis for the information captured in the Explain tables. The information used to generate the access plan can be captured with an explain snapshot. (See Chapter 22, SQL Explain Facility for more information on Explain topics.)
The final plan selected by the DB2 optimizer can consist of a set of steps that might operate on a remote data source. For those operations that will be performed by each data source, the remote SQL generation step creates an efficient SQL statement based on the data source SQL dialect.
This step is bypassed unless you are executing federated database queries. See Remote SQL Generation and Global Optimization for more information.
The final step of the SQL Compiler uses the access plan and the query graph model to create an executable access plan, or section, for the query. This code generation step uses information from the query graph model to avoid repetitive execution of expressions that only need to be computed once for a query. Examples for which this optimization is possible include code page conversions and the use of host variables.
Information about access plans for static SQL is stored in the system catalog tables. When the package is executed, the database manager will use the information stored in the system catalog tables to determine how to access the data and provide results for the query. It is this information that is used by the db2expln tool. (See Chapter 22, SQL Explain Facility for more information on Explain topics.)
It is recommended that RUNSTATS be done periodically on tables used in queries where good performance is desired. The optimizer will then be better equipped with relevant statistical information on the nature of the data. If RUNSTATS is not done (or the optimizer suspects that RUNSTATS was done on empty or near empty tables), the optimizer may either use defaults or attempt to derive certain statistics based on the number of file pages used to store the table on disk (FPAGES).