ユニコード標準は、書かれた文字とテキストのための汎用文字エンコード・スキームです。文字セットを非常に正確に定義すると同時に、少数のエンコードも定義します。テキスト・データの国際的な交換と、グローバル・ソフトウェアの基礎の作成を可能にするエンコード・マルチリンガル・テキストの一貫性のある方法を定義します。
ユニコードには 2 つのエンコード・スキーム、UTF-16 および UTF-8 が備えられています。
デフォルトのエンコード・スキームは UTF-16 で、これは 16 ビットのエンコード・スキームです。 UCS-2 は UTF-16 のサブセットで、これは文字を表すために 2 バイトを使用します。 UCS-2 は一般に、既存のすべての 1 バイトおよび 2 バイト・コード・ページからすべての必要な文字を表現可能な汎用コード・ページとして受け入れられています。 UCS-2 は、IBM ではコード・ページ 1200 として登録されています。
他のユニコード・エンコード形式には UTF-8 があり、これはバイト単位で扱われ、 ASCII をベースとする既存のシステムで容易に使用できるように設計されています。 UTF-8 は、各文字を保管するために可変のバイト数 (通常 1-3、4 の場合あり) を使用します。変化しない ASCII 文字は単一バイトとして保管されます。それ以外の文字はすべて複数バイトを使用して保管されます。一般に UTF-8 データは、マルチバイト・コード・ページのために設計されていないコードによって、拡張 ASCII データとして扱うことができます。UTF-8 は、IBM ではコード・ページ 1208 として登録されています。
アプリケーションは、データがローカル・コード・ページ、UCS-2 および UTF-8 の間で変換されるときにデータの要件を考慮に入れることが重要になります。例えば 20 文字は、UCS-2 ではちょうど 40 バイト、UTF-8 ではオリジナルのコード・ページと使用される文字に応じて 20 から 60 バイトを必要とします。
UTF-8 のコード・セットを指定して作成された DB2 ユニバーサル・データベース Unix 版、Windows 版、および OS/2 版を使用すれば、UCS-2 と UTF-8 の両方のフォーマットのデータを保管できます。このようなデータベースは、ユニコード・データベースと呼ばれます。 SQL 文字データは UTF-8 を使用してエンコードされ、SQL 漢字データは UCS-2 を使用してエンコードされます。つまり、MBCS 文字は、単一バイト文字および 2 バイト文字の両方を含めて文字列に保管され、DBCS 文字は、漢字の列に保管されます。
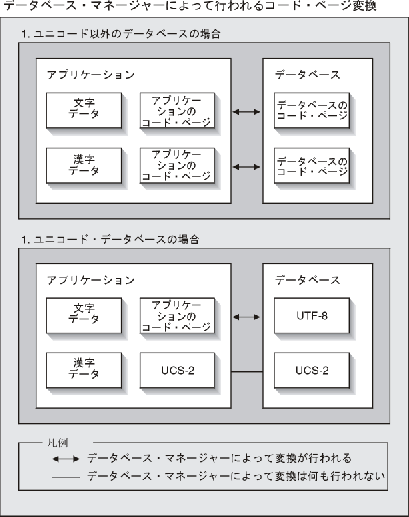
アプリケーションのコード・ページは、DB2 がデータの保管に使用するコード・ページに一致しない場合があります。非ユニコード・データベースでは、コード・ページが同じでない場合、データベース・マネージャーがクライアントとサーバーの間で転送される文字および漢字 (純粋な DBCS) データを変換します。ユニコード・データベースでは、クライアント・コード・ページと UTF-8 間のデータの変換はデータベース・マネージャーによって自動的に実行されますが、漢字 (UCS-2) データはクライアントとサーバーの間で変換されずに渡されます。
図 1. データベース・マネージャーによって実行されるコード・ページ変換
注:
UTF-8 コード・ページをアプリケーションが指定するのは可能であり、この場合、漢字データはすべて UCS-2 で、文字データは UTF-8 で送受信されます。このアプリケーション・コード・ページはユニコード・データベースでのみサポートされます。
ユニコード使用時のその他の考慮事項には以下があります。
CREATE DATABASE unidb USING CODESET UTF-8 TERRITORY US
db2set DB2CODEPAGE=1208
SELECT * FROM mytable WHERE mychar = 'utf-8 data'
AND mygraphic = G'ucs-2 data'
これらのリリース情報には、DB2 バージョン 7.1 でユニコードを使用する際の次の情報に対する更新が含まれています。
第 3 章 言語エレメント
第 4 章 関数
|第 6 章 SQL ステートメント
第 3 章 拡張フィーチャー
付録 C DB2 CLI および ODBC
DB2 でのユニコードの使用法については、「管理の手引き」の各国語サポート (NLS) の付録『DB2 UDB でのユニコード・サポート』を参照してください。