색인화 기술 사용이 암시하는 한 가지는 색인을 사용하려면 우선 작성해야 한다는 것입니다. 검색의 많은 힘든 작업은 기본적으로 색인 작성보다 앞서 수행되므로 런타임 검색은 빠릅니다. 그러나 색인화 프로세스 자체에는 시간이 걸리며 이 시간은 색인화할 데이터의 양에 비례해서 증가합니다.
일반 검색 서버의 초기화는 두 단계로 수행됩니다.
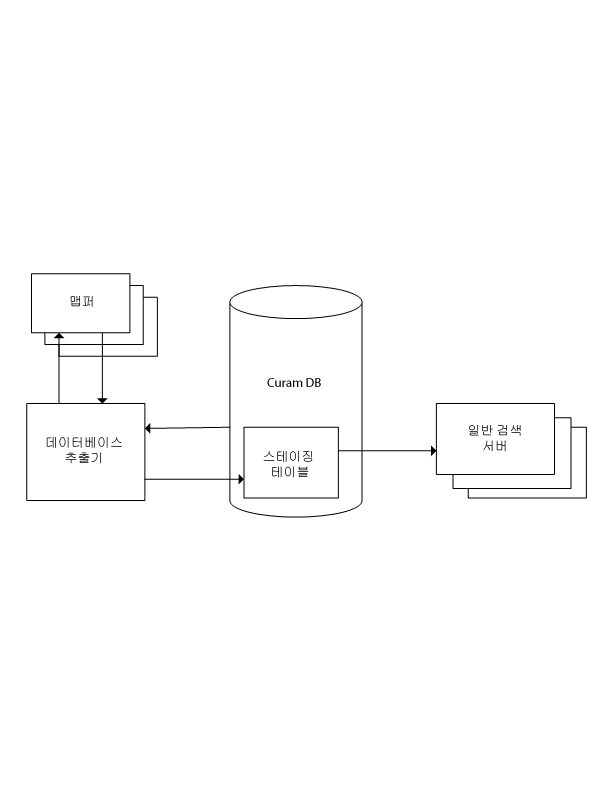
첫 번째 단계는 기존 애플리케이션 데이터를 애플리케이션에서 일반 검색 서버에 사용된 데이터베이스 테이블 세트(스테이징 테이블)로 내보냅니다. 이 내보내기는 데이터베이스 검색 추출기라는 일괄처리 프로세스로 구현되며, 일반 검색 서버 배포의 일부로 제공됩니다. 내보내기는 일반 검색 서버를 처음 사용할 때 한 번만 수행하면 됩니다. 각 검색 서비스에는 맵퍼라는 특수한 헬퍼 클래스가 필요합니다. 이들은 추출기에서 스테이징 테이블로 가져올 데이터 준비를 지원합니다.
두 번째 단계에서는 정의된 모든 검색 서비스에 대해 색인이 작성됩니다. 일반 검색 서버가 시작될 때 스테이징 데이터베이스 테이블에서 적절한 데이터를 읽어서 검색을 수행하는 데 사용되는 색인과 기타 데이터 구조를 작성하는 프로세스가 실행됩니다. 일단 색인이 작성되면 서버는 검색 요청에 응답할 수 있는 위치에 있게 됩니다. 이 성능의 최적화에 대한 정보는 성능에 있습니다.
그림 1. 데이터베이스 추출기와 일반 검색 서버 시작 프로세스