L'utilisation d'une technologie d'index implique qu'avant de pouvoir effectuer une recherche d'index, il faut d'abord créer ce dernier. Etant donné qu'une grande partie du travail de recherche est s'effectue en amont dans la génération d'index, les recherches d'exécution s'accélèrent. Toutefois, il est intéressant de remarquer que le processus d'indexation lui-même peut durer un moment et cette durée augmente proportionnellement à la quantité de données à indexer.
L'initialisation de Generic Search Server s'effectue en deux phases.
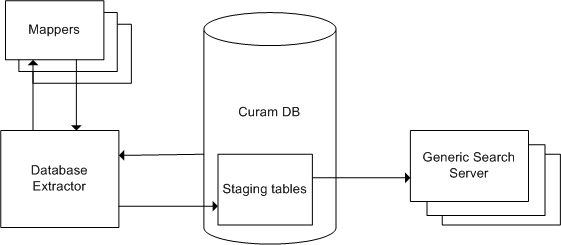
Lors de la première phase, les données d'application existantes sont exportées à partir de l'application dans un ensemble de tables de base de données utilisées par Generic Search Server (les tables de transfert). Cette exportation a été implémentée comme un traitement par lots, appelé Database Search Extractor, et elle est fournie dans le cadre de la distribution de Generic Search Server. L'exportation nécessite seulement d'être exécutée une fois, lorsque Generic Search Server est utilisé en premier. Des classes auxiliaires spéciales appelées "Associateurs" sont nécessaires pour chaque service de recherche : celles-ci aident l'extracteur à préparer les données pour l'importation dans les tables de transfert.
Durant la seconde phase, un index est généré pour chaque service de recherche défini. Lorsque Generic Search Server est démarré, un processus s'exécute pour lire les données appropriées à partir des tables de base de données de transfert et générer les index et les autres structures de donnés à utiliser pour effectuer les recherches. Lorsque les index sont générés, le serveur est en mesure de rechercher les requêtes. Des informations relatives à l'optimisation de ces performances sont disponibles dans le Performances