Debido a que el Servidor de búsqueda genérico busca no en los propios datos activos sino en un índice que se crea a partir de dichos datos, las actualizaciones de los datos de aplicación deben replicarse en el índice. En las implementaciones de Cúram, resulta esencial que las actualizaciones de los datos en los que se puede buscar se reflejen en los índices relevantes de forma oportuna y predecible. Con el Servidor de búsqueda genérico, el retardo de tiempo es breve (y configurables).
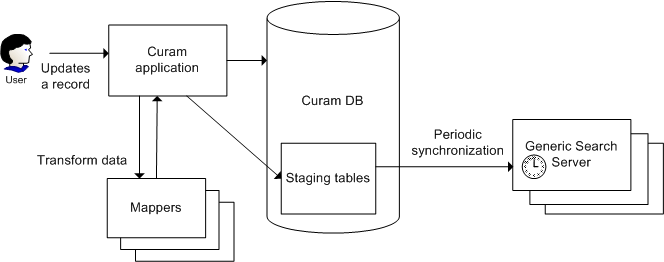
De forma similar a la importación inicial de datos descrita anteriormente, hay dos pasos para el proceso de sincronización.
El primer paso del proceso se produce cuando los datos de la aplicación (que se utilizan en un índice) cambian, normalmente como resultado de una inserción, actualización o supresión lógica. Cuando esto ocurre, la aplicación debe escribir información acerca de este cambio de datos en las tablas del Servidor de búsqueda genérico. Todos los elementos nuevos y actualizados están marcados con una indicación de fecha y hora.
En el segundo paso (que se produce periódicamente), el Servidor de búsqueda genérico sincroniza sus índices sobre el contenido actual de la base de datos de transferencia. Para hacerlo, lee todos los elementos cambiados recientemente modificados desde la última vez en que se sincronizó y los importa en los índices; concretamente, esto se lleva a cabo comparando las indicaciones de fecha y hora asociadas con cada elemento modificado con la última indicación de fecha y hora utilizada durante el paso de la última sincronización.