Because the Generic Search Server searches not on the live data itself but on an Index that is built from that data, updates to application data need to be replicated on the Index. In Cúram implementations, it is essential that updates to searchable data be reflected in the relevant Indices in a timely and predictable fashion. With the Generic Search Server, the time lag is short (and configurable).
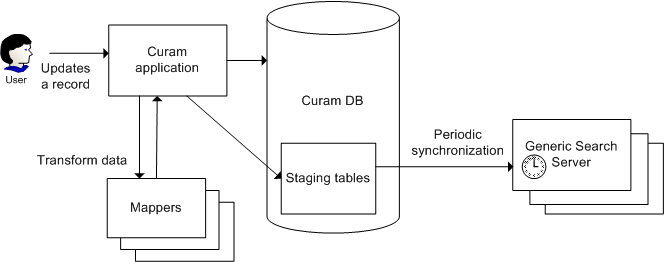
Similar to the initial import of data described above, there are two steps to the synchronization process.
The first step in the process occurs when the application data (which is used in an Index) changes, typically as a result of an insert, update or logical delete. When this occurs, the application must write information about this data change to the Generic Search Server staging tables. All new and updated items are marked with a timestamp.
In the second step (which happens on a periodic basis), the Generic Search Server synchronizes its Indices against the current contents of the staging database. To do this, it reads all newly changed items since the last time it synchronized, and imports these into the Indices; specifically, this is achieved by comparing timestamps associated with each changed item to the latest timestamp used during the last synchronization step.