One implication of using an indexing technology is that, before being able to search an Index, it must first be created. Because a lot of the hard work of searching is essentially done up-front in Index construction, runtime searches become fast; however, it is worth noting that the indexing process itself may take some time, and this time increases proportionally with the amount of data to be indexed.
Initialization of the Generic Search Server is done in two phases.
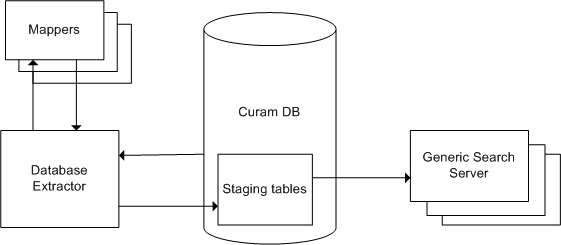
In the first phase, existing application data is exported from the application into a set of database tables used by the Generic Search Server - the staging tables. This export has been implemented as a batch process, called the Database Search Extractor, and is provided as part of the Generic Search Server distribution. The export only needs to be performed once, when the Generic Search Server is first being used. Special helper classes called Mappers are needed for each Search Service; these assist the extractor in preparing the data to be imported into the Staging Tables.
In the second phase, an Index is constructed for every defined Search Service. When the Generic Search Server is started up, a process is run to read the appropriate data from the staging database tables and construct the Indices and other data structures to be used to perform searches. Once the Indices are constructed, the server will be in a position to respond to search requests. Information on optimizing this performance is available in Performance