Da der Server für generische Suche die Suchabfragen nicht in den Livedaten selbst ausführt, sondern in einem Index, der aus diesen Daten erstellt wird, müssen Aktualisierungen der Anwendungsdaten in dem Index repliziert werden. In Cúram-Implementierungen ist es unerlässlich, dass Aktualisierungen durchsuchbarer Daten zeitgerecht und vorhersehbar in die relevanten Indizes übernommen werden. Beim Server für generische Suche ist der zeitliche Abstand kurz (und konfigurierbar).
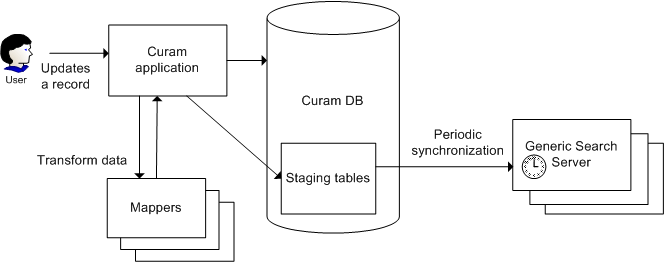
Ähnlich wie beim oben beschriebenen Erstimport der Daten gibt es beim Synchronisationsprozess zwei Schritte.
Der erste Schritt in dem Prozess erfolgt, wenn die Anwendungsdaten (die in einem Index verwendet werden) geändert werden, in der Regel aufgrund eines Einfügungs-, Aktualisierungs- oder logischen Löschvorgangs. Wenn dies geschieht, muss die Anwendung Informationen zu dieser Datenänderung in die Staging-Tabellen des Servers für generische Suche schreiben. Alle neuen und aktualisierten Elemente werden mit einer Zeitmarke markiert.
Im zweiten Schritt (der in regelmäßigen Intervallen erfolgt) synchronisiert der Server für generische Suche seine Indizes mit dem aktuellen Inhalt der Staging-Datenbank. Dazu liest er alle Elemente, die nach der Synchronisation geändert wurden, und importiert sie in die Indizes. Konkret wird dies erreicht, indem die Zeitmarke des jeweils geänderten Elements mit der letzten Zeitmarke verglichen wird, die beim letzten Synchronisationsschritt verwendet wurde.