To effectively protect your data and recover it in the event of failure, you need to understand the measures built into this product. Protecting against system failures involves the LUW, the log, and the checkpoint. Protecting against DASD failures entails two types of archive: the database archive and the log archive.
The data in your database is in a consistent state if no changes are left only partially completed.
Some data changes cannot be expressed in only one SQL statement. For example, suppose you have a banking program to transfer money between accounts, and want to transfer $100 from a SAVINGS to a CHECKING account. The program makes this transfer in two steps:
If the second step fails (for example, because of a system failure), the data is in an inconsistent state. That is, a deposit has been made to the CHECKING account, but no withdrawal has been made from the SAVINGS account.
The logical unit of work (LUW) prevents such inconsistencies. An LUW is a sequence of SQL statements that the system treats as a single entity. Either all the data changes made during an LUW are performed, or none is performed. In the example above, the two updates should be placed within a single LUW.
To group several SQL statements into one LUW, one uses the COMMIT WORK and ROLLBACK WORK commands.
If no problems or errors occur, the user issues the COMMIT WORK command to save all the changes made. If a problem occurs in the middle of an LUW, the user can issue the ROLLBACK WORK command to undo all the changes made since the last COMMIT WORK command.
An LUW can be as small as one SQL statement, or as large as an entire ISQL session or application execution. ISQL, by default, treats each command as an LUW, and issues a COMMIT WORK command after each SQL statement that modifies the database. Users can change this default by issuing the SET AUTOCOMMIT OFF command. For more information on the use of the AUTOCOMMIT, COMMIT, and ROLLBACK commands, refer to the DB2 Server for VSE & VM SQL Reference manual.
The log is a file maintained on DASD that records all the changes completed by each LUW. For each change, the log records the old and new values of the updated object. If any changes to the database must be undone or redone, you can use the log to restore the data to its proper state.
In addition to the changes made by each logical unit of work, the log also records when each logical unit of work started and stopped. (It does not record logical units of work that only read information from the database).
A database must have at least one log. Optionally, you can define a second log. If there are two logs, they are exact duplicates: then, if a DASD failure occurs on one log, the database manager can continue, using the other copy. If there are damaged tracks on each copy, processing can continue as long as a complete copy of the log can be pieced together from both data sets. For more information, see Using Dual Logging.
Larger logs may be needed for tables that are being captured for DataPropagator because of the increased amount of log data written for UPDATEs to those tables which specify DATA CAPTURE CHANGES. Tables being captured will log the entire original row (not just the data that was changed), and the new data that replaces the old changed data. You should consider increasing the size of the log dbextent(s) when planning to make extensive use of this function.
Checkpoints are taken periodically. During a checkpoint the database manager stops servicing users, and takes a "snapshot" of the database that includes updates from completed LUWs as well as from those that are still in progress, and writes them to DASD. In addition, a special checkpoint record is written to the log to synchronize the log with the state of the database.
If your system fails, as long as the current log is available, the database will be automatically recovered to a consistent state when you restart the application server. This process, called restart recovery, uses the log to ensure that changes made by LUWs are either committed (if they had successfully finished) or backed out (if they had not finished successfully).
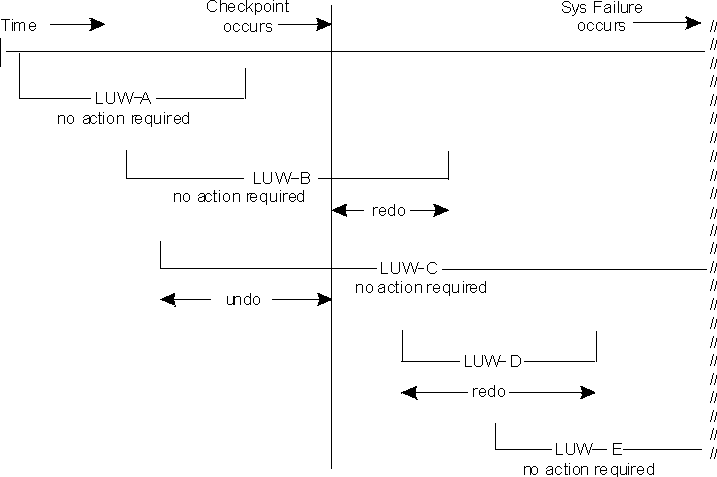
The recovery process determines the state of each LUW; both at the time of failure and at the time of the last checkpoint before the failure. The following scenarios are shown in Figure 68:
The following diagram illustrates the LUW Recovery process for the five cases described above:
Figure 68. LUW Recovery Actions
|
If the application server must be restarted without a log (due to the log either being lost, reformatted, or reconfigured immediately after the failure), the database cannot be adjusted to complete committed logical units of work or to back out uncommitted ones. In this situation, to recover the database you will have to restore a previous database archive, together with any applicable log archives.
If the database manager had been running in single user mode with LOGMODE=N, the changes made by the application are not logged. However, a checkpoint would have been taken each time the application issued a COMMIT WORK (or one was issued for the application), so most changes will have been effectively committed. Any that were uncommitted at the time of failure will be discarded when you restart the application server and will need to be re-entered.
Archiving facilities enable you to recover your database directory and storage pools from DASD failures. There are two kinds of archives: database archives and log archives.
A database archive is a tape copy of the database directory and dbextents. It can be taken using two types of facilities:
If database manager facilities are used, the database manager takes a checkpoint (the begin-archive checkpoint) and writes a copy of the database directory and the database to tape, as they were at the checkpoint. (A database archive does not include a copy of the log.) Users continue to receive service while the archive is being done.
A user archive can only be done while the application server is shut down. A user archive generally takes less time than a database manager archive.
You are not restricted to using one kind of archive for a given database; you can switch between database manager archives and user archives as often as you like. There are two situations in which the former facility is required:
Experience helps you determine which method is best for you. When using any backup method, the performance improvement will be related to how full your database is. The fewer pages in your database that are allocated, the less time a database manager archive takes.
In fact, if the percent of allocated pages is low enough, a database manager archive will outperform a user archive, because the database manager only archives pages that actually contain data. User facilities archive all pages, so the time taken does not vary with the number of pages allocated.
Aside from the performance advantage that user archiving facilities may offer because they exploit particular device characteristics, consider whether your facility provides other advantages such as archiving multiple dbextents simultaneously.
For a description of how to carry out these archives, see Performing Database Archives With Database Manager Facilities and Performing Database Archives With User Facilities.
A log archive is a copy of the log on tape. Only database manager archive facilities can be used to archive the log. Log archives can be taken either when the database manager is running or at shutdown. Because the log is usually much smaller than the database, this archive takes less time than a full database archive. For a description of how to carry it out, refer to Performing Log Archives.
If a DASD failure occurs on one of your database devices, you can restore the database by replacing the damaged volume with a working volume (see Replacing a Dbextent), redefining (or restoring) the data sets on the volume, and then restoring the data from the archived database and logs (if applicable.)
There are two ways to do this. One way is to use the database archive and the current log. By loading the archive and re-applying the changes in the log, you can bring the database up-to-date because all changes made to the database since the archive are recorded in the current log. If the restore set for the database archive includes the current log, you can recover the damaged storage pools instead of the entire database using the Data Restore Feature. See the DB2 Server for VSE & VM Data Restore manual for more information on storage pool level recovery.
Alternatively, if you archived the log, you can use the database archive, the log archives you created since the last database archive, and your current log, to recreate the database. You would load the database archive, and reapply the changes in the log archives and the current log. If the restore set for the database archive includes the current log, you can recover the damaged storage pools instead of the entire database using the Data Restore Feature. See the DB2 Server for VSE & VM Data Restore manual for more information on storage pool level recovery.
The relationships among the different archives, the current log, and the current database are shown in Figure 69. For more details, see Restoring the Database.
If a DASD failure, such as an unresolvable I/O error, occurs on one of the log devices, there are two possibilities for recovery:
If a DASD failure occurs on both a database device and a log device, you can restore the database by replacing the damaged dbextent with a working data set (see Replacing a Dbextent), replacing the damaged log data set with a working data set (see Replacing a Log), and then restoring the data from the archived database and logs (if applicable) (see Restoring the Database).