When the database manager folds keywords and identifiers from lowercase to uppercase, or folds user-supplied data using the default TRANSLATE scalar function,
it bases the folding on the default character set specified on the SQLSTART initialization parameter. For information on setting the default character set, refer to Choosing an Application Server Default CHARNAME.
Some characters in other national languages must be delimited by double quotation marks (") before they can be accepted in identifiers. The double quotation marks indicate that special characters are within the identifier. No characters within delimited identifiers are folded from lowercase to uppercase. To get proper folding of these characters and to allow them as part of an unquoted identifier, you can specify your own character set, which includes both classification and folding tables. Specify the CHARNAME parameter at startup to have the database manager use your character set as the default. You can then use characters such as o-umlaut or n-tilde in identifiers without the use of double quotation marks.
For information on how to define your own character set, see Appendix E, Defining Your Own Character Set.
You will probably be able to use one of the IBM-supplied sample character sets without modification. This section shows the hexadecimal value that is used to represent each valid character. If your devices use those hexadecimal values for the indicated characters, you can use the IBM-supplied samples.
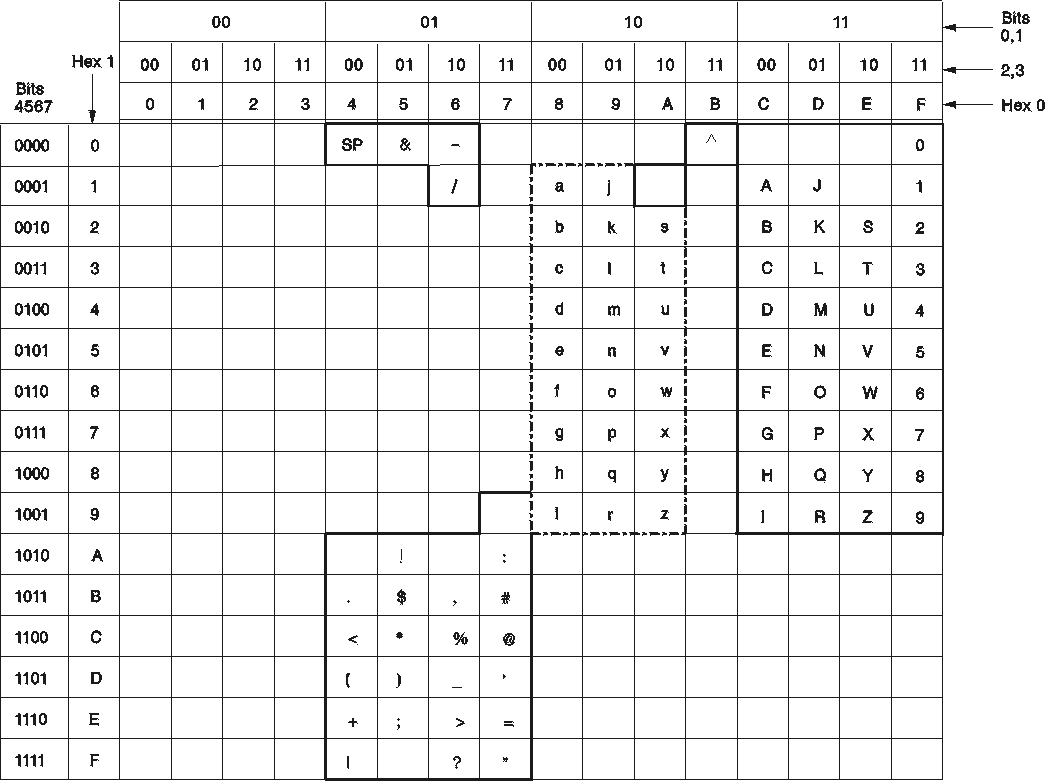
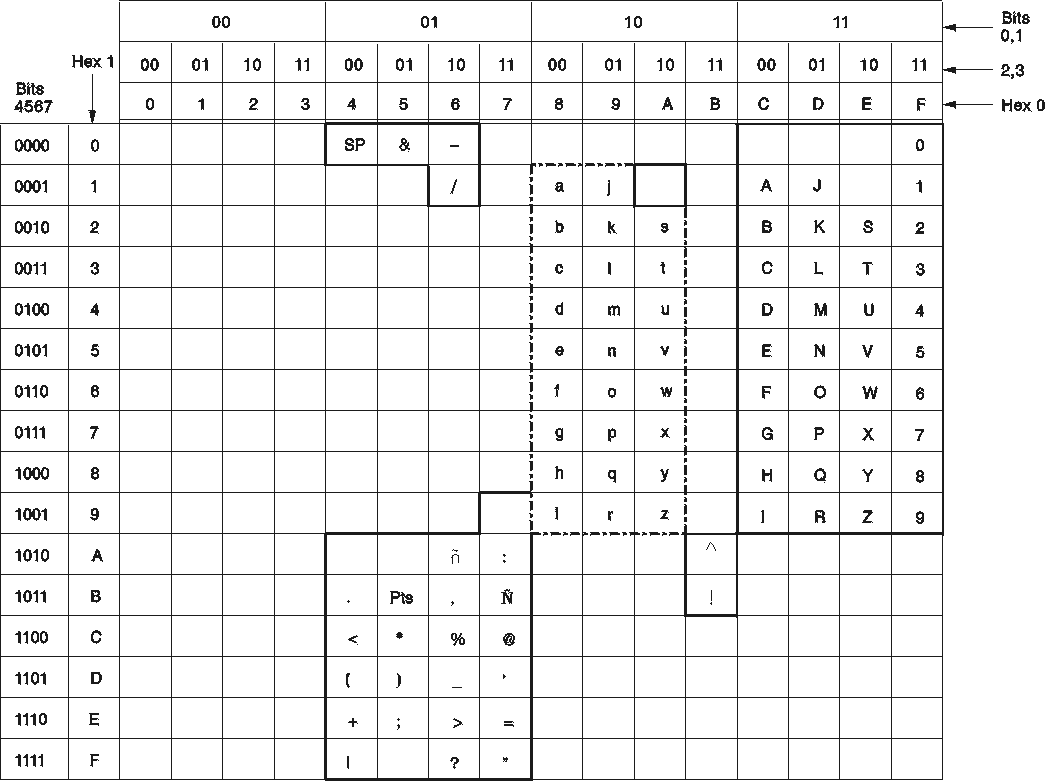
The ENGLISH character set is shown in Figure 100. Only those characters that are identifiable by the database manager are shown. Any hexadecimal code that does not have a character assigned to it is unusable for DB2 Server for VM keywords or unquoted identifiers. Such characters are usable in quoted identifiers and in constants and, of course, can be stored in the database.
For example, many display devices using an English character set assign a cent sign (¢) to X'4A'. In Figure 100, however, no character is shown for the value X'4A' meaning that X'4A' is unusable for DB2 Server for VM keywords or unquoted identifiers. If you want to put a cent sign in an identifier, you must use a delimited identifier.
Another example is the tilde (~). In most ENGLISH character sets, the tilde is represented by X'A1'. The matrix shows no entry for X'A1'. So, regardless of what X'A1' represents in your character set, you must use a delimited identifier.
These rules apply to the matrices for the other character sets as well. An important point to remember is that the absence of a character in one of the matrices does not prevent you from using that character set. The characters are not undefined to the database manager; they merely have limited use (as described above). Often, this limited use is exactly how you want the hexadecimal code to be handled. Independent of this qualification, you should almost always be able to find a CCSID that you can use at your installation. When you decide on a CCSID, try to avoid using a non-standard CCSID to prevent possible problems in the future (such as the inability to connect to other application servers because they do not support your CCSID). If you require a CCSID that is not supplied in the catalog tables, check the Character Data Representation Architecture Level 1, Registry manual for other predefined registered CCSIDs.
Figure 100. ENGLISH Character Set (CCSID=37)
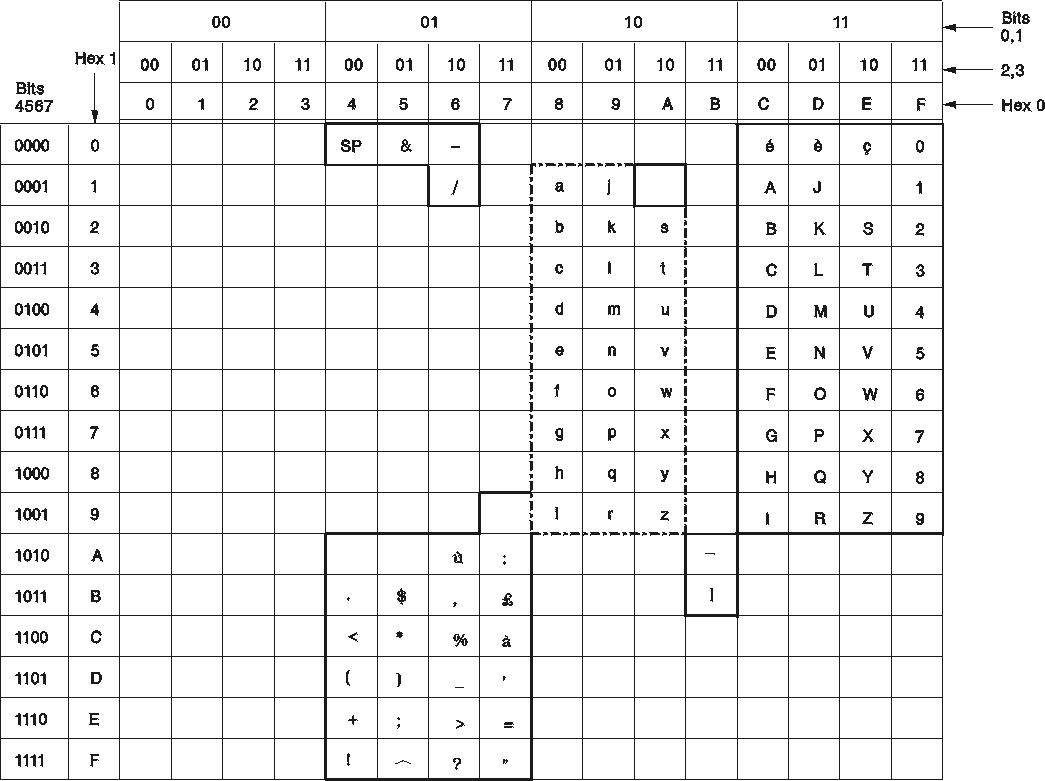
The sample FRENCH character set is shown in Figure 101. Translation from lowercase to uppercase is done as
follows:
X'6A' is translated to X'E4'
X'7C' X'C1'
X'C0' X'C5'
X'D0' X'C5'
X'E0' X'C3'
These characters can be used in unquoted identifiers.
When evaluating the character set for use in your installation, remember that hexadecimal values that do not have characters assigned to them in Figure 101 can be used in quoted identifiers.
Figure 101. FRENCH Character Set (CCSID=297)
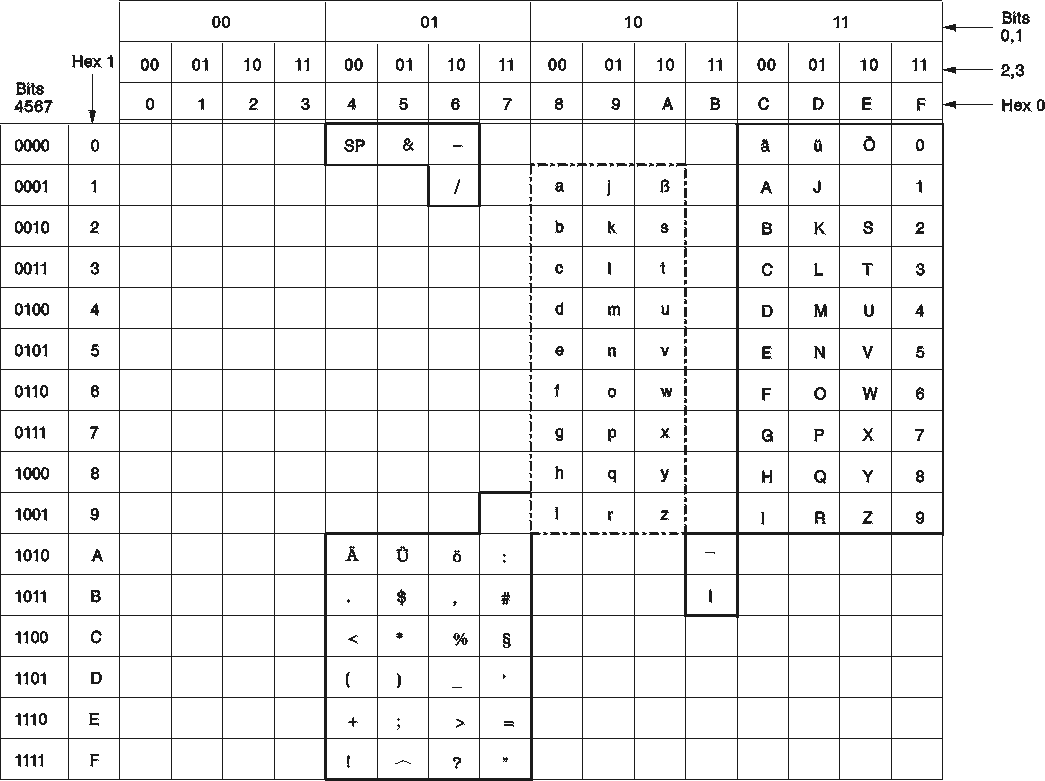
The sample GERMAN
character set is shown in Figure 102. Translation from lowercase to uppercase is done as
follows:
X'4A' is translated to X'4A'
X'5A' X'5A'
X'6A' X'E0'
X'A1' X'A1'
X'C0' X'4A'
X'D0' X'5A'
X'E0' X'E0'
These characters can be used in unquoted identifiers.
When evaluating the sample character set for use in your installation, remember that hexadecimal values that do not have characters assigned to them in Figure 102 can be used in quoted identifiers.
Some translation from lowercase to uppercase does not cause a change in the hexadecimal value. For more information, see Step 3: Determine Translation Characters.
Figure 102. GERMAN Character Set (CCSID=273)
The sample ITALIAN character set is shown in Figure 103. Translation from lowercase to uppercase is done as
follows:
X'5A' is translated to X'C5'
X'6A' X'D6'
X'79' X'E4'
X'A1' X'C9'
X'C0' X'C1'
X'D0' X'C5'
X'E0' X'C3'
These characters can be used in unquoted identifiers.
When evaluating the sample character set for use in your installation, remember that hexadecimal values that do not have characters assigned to them in Figure 103 can be used in quoted identifiers.
Figure 103. ITALIAN Character Set (CCSID=280)

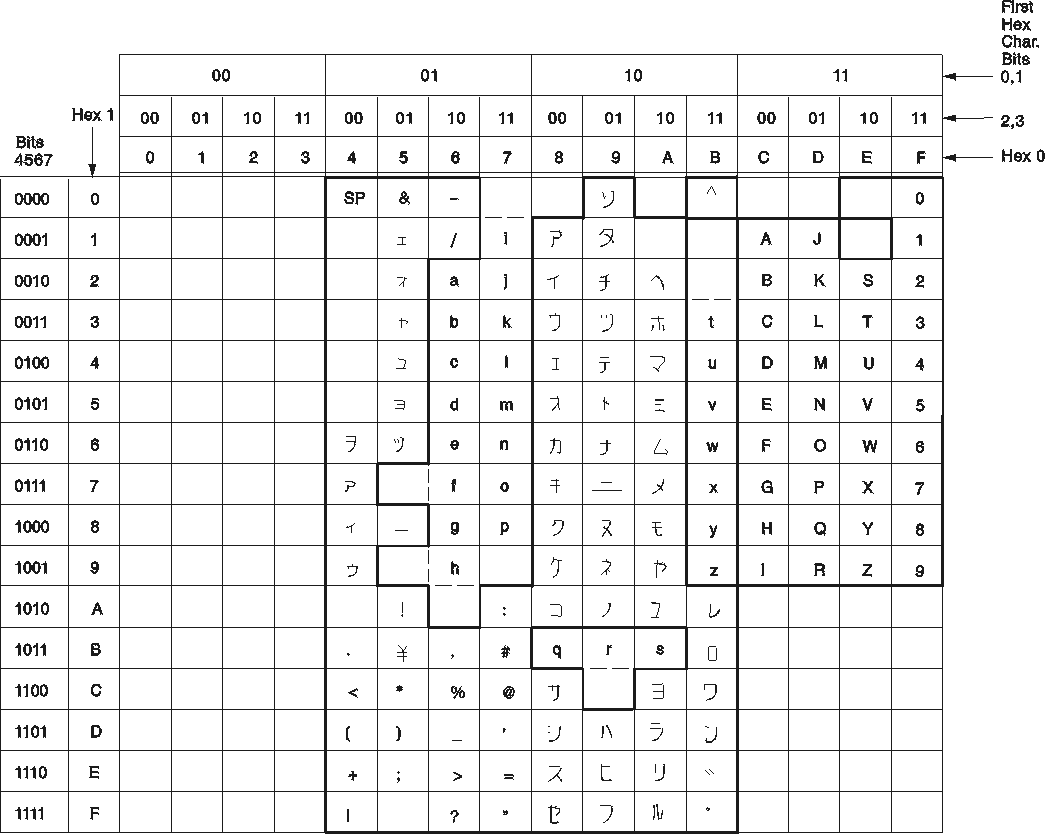
The sample KATAKANA character set is shown in Figure 104.
When evaluating the sample character set for use in your installation, remember that hexadecimal values that do not have characters assigned to them in Figure 104 can be used in quoted identifiers.
Figure 104. JAPANESE (Katakana) Character Set (CCSID=290, the SBCS Component of CCSID 5026)
The sample SPANISH character set is shown in Figure 105. Translation from lowercase to uppercase is done as
follows:
X'6A' is translated to X'7B'
These characters can be used in unquoted identifiers.
When evaluating the sample character set for use in your installation, remember that hexadecimal values that do not have characters assigned to them in Figure 105 can be used in quoted identifiers.
Figure 105. SPANISH Character Set (CCSID=284)
If the hexadecimal codes in one of the sample character sets matched those used by your devices, you can specify the character set at run time. To use a character set, specify the CHARNAME parameter when starting the application server. The CHARNAME parameter is valid in both single and multiple user mode. For information on how to specify the CHARNAME parameter, see Setting the Application Server Default CHARNAME and CCSIDs. Examples of IBM-supplied sample character sets are:
Figure 106 shows an example of starting the application server. The CHARNAME parameter indicates that the database manager is to use the FRENCH sample character set, and the default CCSID of 297.
Figure 106. Starting the Application Server to Use the FRENCH Character Set
SQLSTART DB(SQLDBA) ID(MYBOOT) PARM(PARMID=WARM1,CHARNAME=FRENCH) |
The default character sets ENGLISH (CCSID=37) and INTERNATIONAL (CCSID=500) are hardcoded into this product. For example, if you specify ENGLISH for the CHARNAME parameter, the database manager uses the ENGLISH character set that is coded internally. The internally coded character set is used even if a row exists in SYSTEM.SYSCHARSETS that has ENGLISH or INTERNATIONAL in its NAME column. (Neither the sample ENGLISH character set nor the sample INTERNATIONAL character set is used, although you can load either into SYSTEM.SYSCHARSETS. They are provided to make the definition of your own character sets easier.)
If you specify the name of a character set that is not defined in SYSTEM.SYSCHARSETS, the database manager displays an error message and uses the character set that was specified previously. If the character set is defined incorrectly in SYSTEM.SYSCHARSETS, an error message is displayed, and the database manager uses the character set that was previously specified.