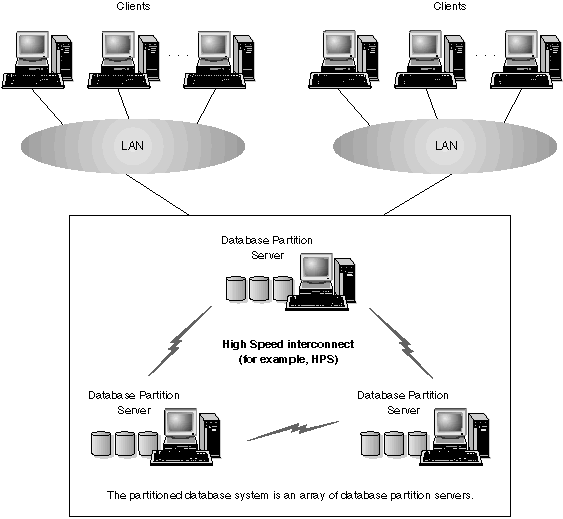
Figure 1 shows an example of a DB2 Enterprise - Extended Edition (DB2 EEE) hardware configuration.
Figure 1. DB2 Enterprise - Extended Edition Hardware Configuration
|
DB2 EEE can run on a cluster of individual CPUs interconnected by shared memory (symmetric multiprocessors (SMP)), a dedicated high-speed communications switch (for example, High Perfomance Switch (HPS)), or a LAN. The number of database partition servers in a configuration varies by platform. You should limit the number of database partition servers that communicate over a LAN to 16.
In practice, the number of database partition servers in a confuguration is determined by the platform and the management tools available on each platform. For more information about configuration, refer to the Administration Guide.
For example, in an IBM RISC System/6000 Scalable POWER Parallel Systems (RS/6000 SP) environment that is running AIX, the number of database partition servers is only limited by the possible size of an AIX RISC System/6000 SP system.
For an HP-UX environment, the number of database partition servers is limited by the size of the machines and the number of those machines that are clustered together. For example, 24 database partition servers could run on a cluster of 4 K580 Enterprise Servers with 6 CPUs each.
In a PTX environment, the number of database partition servers is limited by the number of quads in a machine. We recommend that you run one database partition server per NUMA-Q quad. For example, five multiple logical nodes on a five quad system, with each logical node having four processors.
In a Solaris** Operating Environment**, the number of database partition servers is limited by the size of the machines and the number of those machines that are clustered together. Forty database partition servers could be run on a clustered system of four Ultra Enterprise 6000s with ten CPUs each.
The following sections provide information that you should be familiar with before you configure your partitioned database system. Specifically, they describe:
DB2 Enterprise - Extended Edition implements a shared-nothing architecture, therefore each database partition server is the equivalent of a single-partition database system. Thus, the database storage capacity for the partitioned database system is equal to that provided by a single-partition database system multiplied by the number of database partition servers. You can store tables of up to 512 GB (gigabytes) per database partition. For example, in a database that has 128 partitions, the maximum size of one table is approximately 64 TB (terabytes).
You can define named subsets of one or more database partitions in a database. Each subset you define is known as a nodegroup. Each subset that contains more than one database partition is known as a multipartition nodegroup. Multipartition nodegroups can only be defined within database partitions that belong to the same database.
Three default nodegroups are created when you create a database: IBMDEFAULTGROUP, IBMCATGROUP, and IBMTEMPGROUP.
If you want, you can create table spaces in the default nodegroups IBMDEFAULTGROUP and IBMCATGROUP, and then create tables within those table spaces.
The IBMDEFAULTGROUP nodegroup contains all the database partitions for the database. When you create a database, a database partition is created at each database partition server (node) that is defined in the node configuration file (db2nodes.cfg).
The IBMCATGROUP nodegroup for the database is created at the database partition server where you enter the create database command. This nodegroup only contains the database partition that is local to the database partition server where the command was entered. This database partition server is referred to as the catalog node of the database because the IBMCATGROUP nodegroup contains the catalog tables for the database.
You cannot directly work with the third default nodegroup, IBMTEMPGROUP. Like the IBMDEFAULTGROUP nodegroup, it also contains all the database partitions of a database. This nodegroup is used to contain all temporary table spaces.
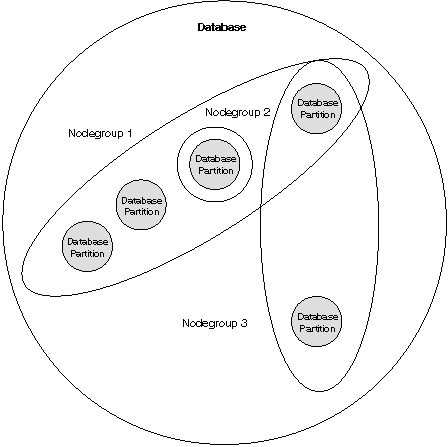
Figure 2 shows an example of a database in which there are three nodegroups. Nodegroup 1 is a multipartition nodegroup made of four database partitions, nodegroup 2 is a single-partition nodegroup, and nodegroup 3 is a multipartition nodegroup.
Figure 2. Nodegroups in a Database
 |
When you want to create table spaces for a database, you first create the nodegroup where the table spaces will be stored, then create a table space in the nodegroup. After this, you create the tables in the table space.
You can drop database partitions from a nodegroup, or if new nodes have been defined in the db2nodes.cfg file, you can add them to a nodegroup in a database. For information about adding and dropping nodes in nodegroups, refer to the Administration Guide.
As your database increases in size, you can add database partition servers to the database system for improved performance. This is known as scaling the database system. When you add a database partition server, a database partition is created for each database that already exists in the database system. You then add the new database partition to an existing nodegroup that belongs to that database. Finally, you redistribute data in that nodegroup to utilize the new database partition. For information about scaling databases, refer to the Administration Guide.
Each table defined in a multipartition nodegroup has a partitioning key associated with it. The partitioning key is an ordered set of columns whose values are used in conjunction with a partitioning map to determine the database partition on which a row of a given table resides. The partitioning map is an array of 4 096 database partition numbers.
Columns of any data type (except LONG VARCHAR, LONG VARGRAPHIC, BLOB, or CLOB) can be used as the partitioning key. A table defined in a single-partition nodegroup may or may not have a partitioning key. Tables with only long-field columns can only be defined in single-partition nodegroups, and they cannot have a partitioning key. For more information about creating tables, refer to the SQL Reference.
The use of nodegroups and partitioning keys means that:
For more information about creating nodegroups, refer to the SQL Reference. For more information about using nodegroups, refer to the Administration Guide.
Typically, you configure DB2 Enterprise - Extended Edition to have one database partition server assigned to each machine. There are situations, however, in which it would be advantageous to have more than one database partition server assigned to each machine. If these database partition servers (nodes) participate in the same instance, this is referred to as a Multiple Logical Node (MLN) configuration.
A Multiple Logical Node (MLN) configuration is useful when the system runs queries on a machine that has symmetric multiprocessor (SMP) architecture. Another benefit is that multiple logical nodes can exploit SMP hardware configurations. In addition, because database partitions are smaller, you can obtain better performance when performing such tasks as backing up and restoring database partitions and table spaces, and creating indexes. As a general rule, we recommend that you run one MLN per 4 processors. Depending on the operating system where you are running DB2 EEE, this may vary for performance reasons.
For more information about setting up logical nodes, refer to the Administration Guide.
An instance has its own databases and instance directory. The instance directory contains the database manager configuration file, system database directories, node directories, and the node configuration file. For more information on instances in a partitioned database system, refer to the Administration Guide.
In DB2 Enterprise - Extended Edition (DB2 EEE), an instance is made up of all the database partition servers (nodes) that were defined to take part in a given partitioned database system. The database partition servers are defined in the db2nodes.cfg file as nodes.
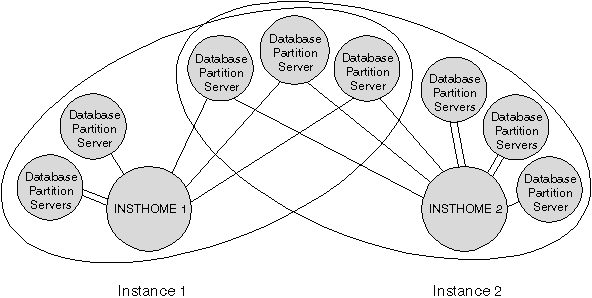
Each instance has different security from other instances on the same machine. This is shown in Figure 3, which shows two separate instances. Instance 1 contains six database partition servers and Instance 2 contains eight database partition servers. (Multiple database partition servers are indicated when more than one line is shown between a database partition server and the instance directory.) The two instances overlap, but this is due to the assignment of two database partition servers to each of the three machines in the middle of the figure.
The db2nodes.cfg file for Instance 1 will not list the database partition servers that belong to Instance 2, and the converse.
 |
You can have multiple instances on the same machine, with each configured differently:
Each instance is owned by a user known as the instance owner. For information about creating instances, refer to the Administration Guide.
The instance owner has System Administrative (SYSADM) authority for all databases that belong to the instance. Because the instance owner has almost complete control over the instance, this user ID can:
The instance owner cannot remove an instance. This requires root authority.
There is a one-to-one relationship between an instance and an instance owner; that is, a user cannot own more than one instance. (However, an instance owner may possess authorizations for other instances, up to, and including, SYSADM). In addition to this, each instance must have a separate home directory.
The Fast Communications Manager (FCM) provides communication support for DB2 Enterprise - Extended Edition. Each database partition server has one FCM daemon to provide communications between database partition servers to handle agent requests, and to deliver message buffers. It consists of:
The FCM daemon is started when you start the instance. When the daemon starts, it reads the node configuration file (INSTHOME/sqllib/db2nodes.cfg, where INSTHOME is the home directory of the instance owner) and defines a well-known address to use for communications.
If communications fail between database partition servers or if they
re-establish communications, the FCM daemon updates information (that you can
query with the database system monitor) and causes the appropriate action
(such as the rollback of an affected transaction) to be performed.
 | You can specify the number of FCM message buffers with the fcm_num_buffers database manager configuration parameter. For a description of this and other FCM parameters, refer to the Administration Guide. |
You can set up your partitioned database system so that if a machine fails, the database server on the failed machine can run on another machine.
On AIX, you implement failover support using IBM's High Availability Cluster Multi-Processing (HACMP). Failover capability allows for the automatic transfer of workload from one processor to another should there be a hardware or software failure. HACMP provides increased availability through a cluster of processors which share resources such as disks or network access.
On Solaris systems, you implement failover support using Sun Cluster 2.2. Sun Cluster 2.2 performs both failure detection and the restarting of resources in a clustered environment, as well as failover support for physical disks and IP addresses.
At this time, DB2 failover support for HP-UX or PTX operating systems is a manual process requiring you to restart the failing node manually on another node that has access to the failing node's disk.
For more information, refer to the Administration Guide.