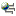 This example builds on the access plan described in Query 2 by creating
indexes on the DEPT column on the STAFF table and on the DEPTNUMB column on
the ORG table. You can follow along
interactively using the sample snapshots provided.
This example builds on the access plan described in Query 2 by creating
indexes on the DEPT column on the STAFF table and on the DEPTNUMB column on
the ORG table. You can follow along
interactively using the sample snapshots provided.
This example builds on the access plan described in Query 2 by creating
indexes on the DEPT column on the STAFF table and on the DEPTNUMB column on
the ORG table. You can follow along
interactively using the sample snapshots provided.
1. What has changed in the access plan with indexes?
A nested loop join, NLJOIN (4), has replaced the merge scan join MSJOIN (4) that was used in Query 2. Using a nested loop join resulted in a lower estimated cost than a merge scan join, because this type of join does not require any sort or temporary tables.
A new diamond-shaped node, I_DEPTNUMB, has been added just above the ORG table. This node represents the index that was created on DEPTNUMB, and shows that the optimizer used an index scan instead of a table scan to determine which rows to retrieve.
2. Does this access plan use the most effective methods of accessing data?
As a result of adding indexes, an IXSCAN node, IXSCAN (18), was used to access the ORG table. Query 2 did not have an index; therefore, a table scan was used in that example.
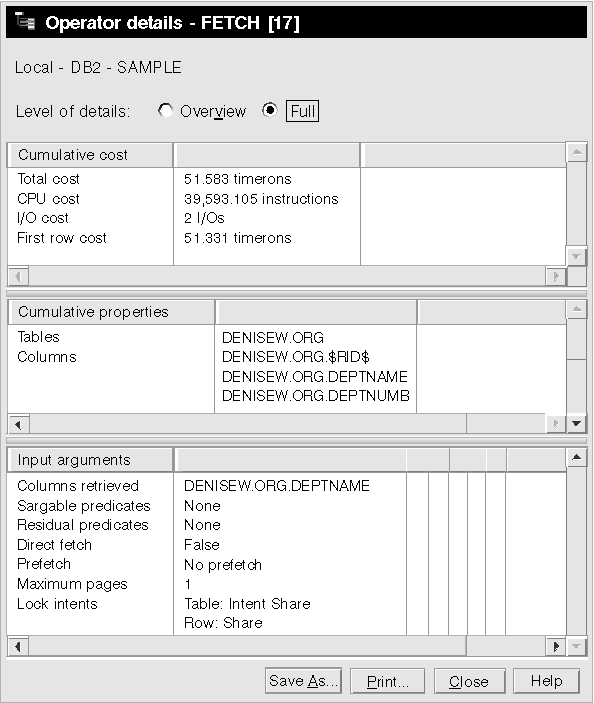
The FETCH node, FETCH (17), shows that in addition to using the index scan to retrieve the column DEPTNUMB, the optimizer retrieved additional columns from the ORG table using the index as a pointer. In this case, the combination of index scan and fetch was calculated to be less costly than the full table scan used in the previous access plans.
Note that the node for the ORG table appears twice, to show its relationship both to the index for DEPTNUMB and to the FETCH operation.
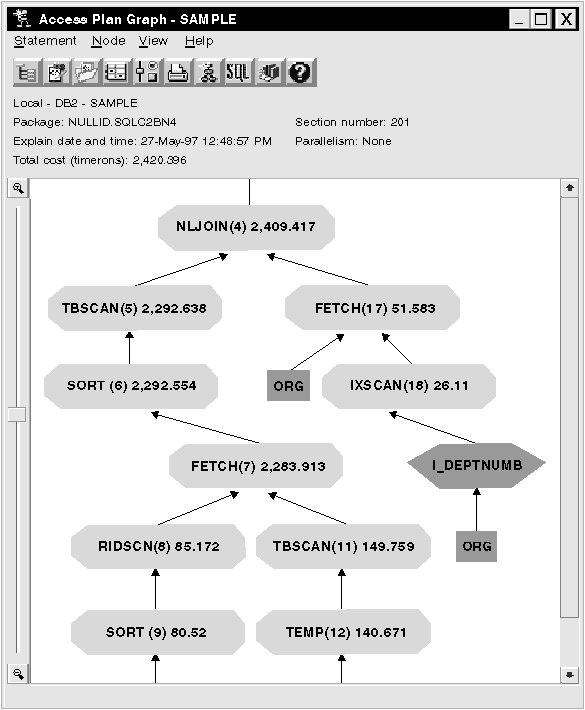
In the next portion of the access plan graph, notice that a new index (I_DEPT) was created on the DEPT column and IXSCAN (10) was used to access the STAFF table. In Query 2, a table scan was used to access the STAFF table.
The access plan for this query shows the effect of creating indexes on columns involved in join predicates. Indexes can also speed up the application of local predicates. Let's look at the local predicates for each table in this query to see how adding indexes to columns referenced in local predicates might affect the access plan.
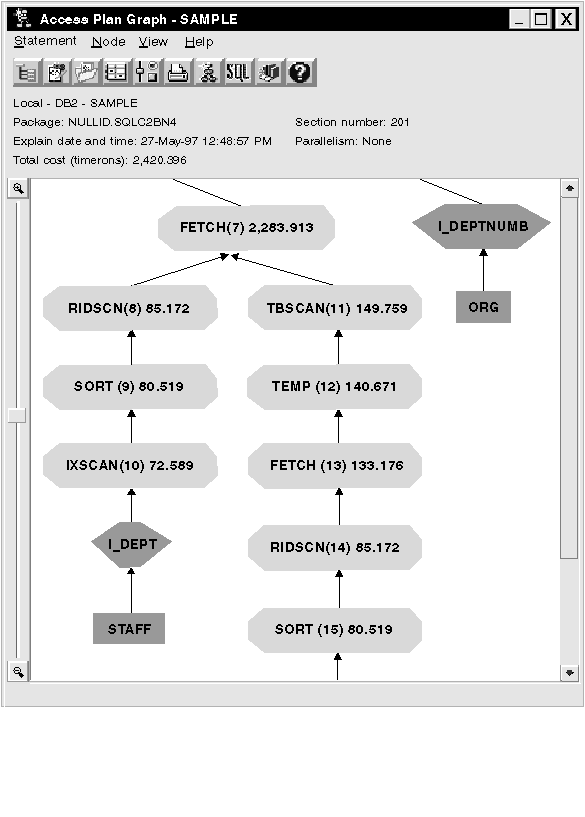
In the Operator Details window for the FETCH (13) operator, look at the columns under Cumulative Properties. The column used in the predicate for this fetch operation is JOB, as shown in the Predicates section. Note that the selectivity of this predicate is .25. This means that with this predicate, only 25% of the rows will be selected for further processing.
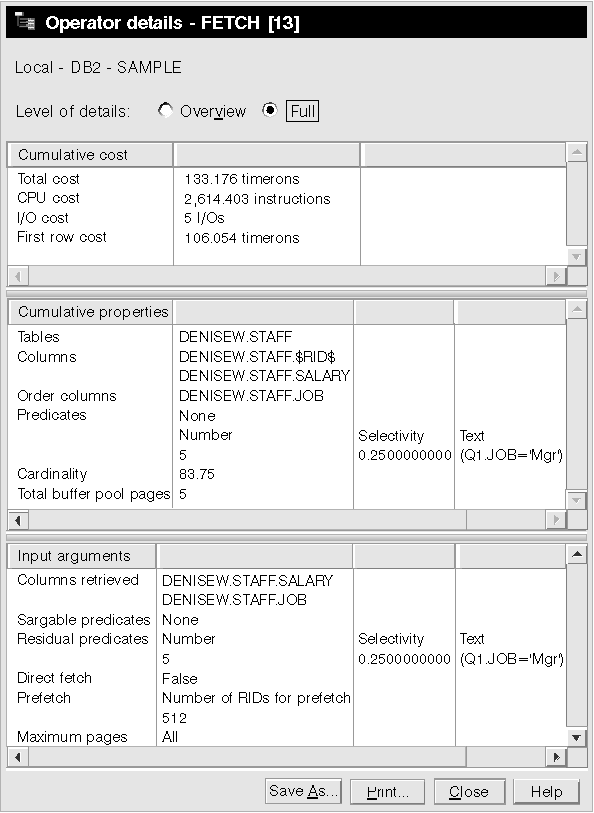
The Operator Details window for the FETCH (17) operator shows the columns being used in this operation. You can see that DEPTNAME is listed in the first row beside Columns retrieved under Input arguments.
3. How effective is this access plan?
This access plan is more cost effective than the one from the previous example. The cumulative cost has been reduced from approximately 2,643 timerons in Query 2 to approximately 2,420 timerons in Query 3.
However, the access plan for Query 3 shows an index scan IXSCAN (18) and a FETCH (17) for the ORG table. While an index scan combined with a fetch operation is less costly than a full table scan, it means that for each row retrieved, the table is accessed once and the index is accessed once. Let's try to reduce this double access on the ORG table.
How to further refine this access plan
Create additional indexes in an attempt to reduce the estimated cost for the access plan.
The next example reduces the fetch and index scan to a single index scan without a fetch. We'll add DEPTNAME to the index we created previously on the ORG table. (Adding a separate index could cause an additional access.) On the STAFF table, we'll create a new index on the JOB column.