El estándar de Unicode es un esquema de codificación de caracteres universal para caracteres y texto escrito. Define con mucha precisión un juego de caracteres, así como un pequeño número de codificaciones para éste. Define un modo coherente de codificar texto en varios idiomas que permite el intercambio de datos de texto internacionalmente y crea las bases para el software global.
Dos de los esquemas de codificación proporcionados por Unicode son UTF-16 y UTF-8.
El esquema de codificación por omisión es UTF-16, que es un formato de codificación de 16 bits. UCS-2 es un subconjunto de UTF-16 que utiliza dos bytes para representar un carácter. UCS-2 se acepta normalmente como la página de códigos universal capaz de representar todos los caracteres necesarios de todas las páginas de códigos existentes de un sólo byte y de doble byte. UCS-2 está registrado en IBM como página de códigos 1200.
El otro formato de codificación de Unicode es UTF-8, que está orientado a byte y que ha sido diseñado para que se utilice con facilidad con los sistemas existentes basados en ASCII. UTF-8 utiliza un número variable de bytes (normalmente 1-3, a veces 4) para almacenar cada uno de los caracteres. Los caracteres de ASCII invariables se almacenan como bytes únicos. Todos los demás caracteres se almacenan utilizando varios bytes. En general, los datos de UTF-8 pueden tratarse como datos ASCII ampliados por medio de un código que no ha sido diseñado para páginas de códigos de varios bytes. UTF-8 está registrado en IBM como página de códigos 1208.
Es importante que las aplicaciones tengan en cuenta los requisitos de la conversión de los datos entre la página de códigos local, UCS-2 y UTF-8. Por ejemplo, 20 caracteres necesitarán exactamente 40 bytes en UCS-2 y entre 20 y 60 bytes en UTF-8, en función de la página de códigos original y de los caracteres utilizados.
Puede utilizarse una base de datos universal de DB2 para Unix, Windows u OS/2 creada especificando un conjunto de códigos UTF-8 para almacenar datos en formatos UCS-2 y UTF-8. A dicha base de datos se la denomina base de datos Unicode. Los datos de tipo carácter SQL se codifican utilizando UTF-8 y los datos gráficos SQL se codifican utilizando UCS-2. Esto significa que los caracteres MBCS, incluidos los caracteres de un solo byte y de byte doble, se almacenan en columnas de caracteres, y que los caracteres DBCS se almacenan en columnas de gráficos.
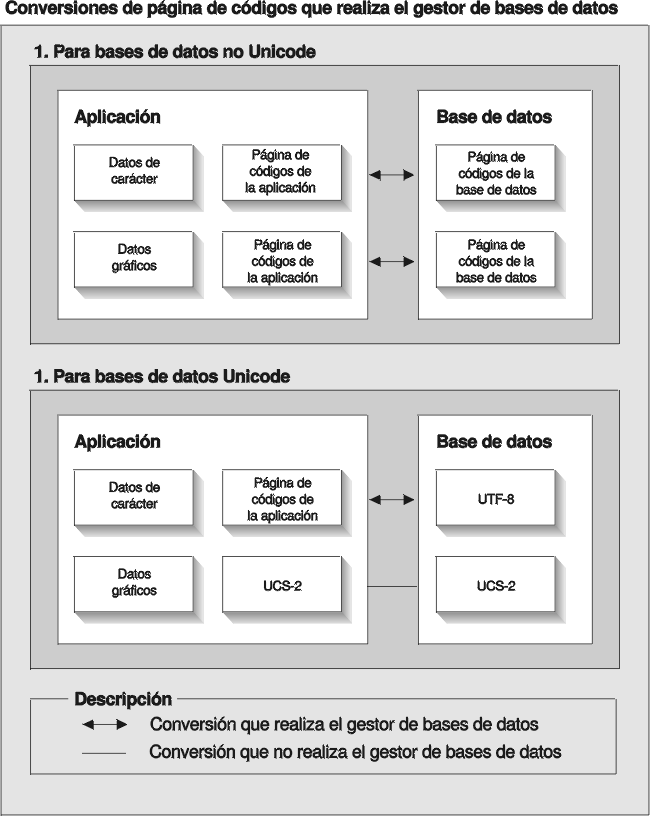
Es posible que la página de códigos de una aplicación no coincida con la página de códigos que utiliza DB2 para almacenar datos. En una base de datos no Unicode, cuando las páginas de códigos no sean las mismas, el gestor de la base de datos convierte los datos de carácter y de gráfico (DBCS puro) que se transfieren entre el cliente y el servidor. En una base de datos Unicode, la conversión de datos de carácter entre la página de códigos de cliente y UTF-8 la efectúa automáticamente el gestor de la base de datos, pero todos los datos gráficos (UCS-2) se pasan sin conversión alguna entre el cliente y el servidor.
Figura 1. Conversiones de página de códigos que efectúa el gestor de la base de datos
Notas:
Para una aplicación es posible especificar una página de códigos UTF-8, indicando que todos los datos gráficos se enviarán y recibirán en UCS-2 y los datos de tipo carácter en UTF-8. Esta página de códigos de aplicación sólo está soportada para bases de datos Unicode.
Otros puntos a tener en cuenta al utilizar Unicode:
CREATE DATABASE unidb USING CODESET UTF-8 TERRITORY US
db2set DB2CODEPAGE=1208
SELECT * FROM mytable WHERE mychar = 'utf-8 data'
AND mygraphic = G'ucs-2 data'
Estas notas del release incluyen actualizaciones de la información siguiente sobre la utilización de Unicode con DB2 Versión 7.1:
Capítulo 3. Elementos de lenguaje
Capítulo 4. Funciones
Capítulo 6. Sentencias de SQL
Capítulo 3. Using Advanced Features
Apéndice C. DB2 CLI and ODBC
Para obtener más información sobre la utilización de Unicode con DB2, consulte el manual Administration Guide, apéndice de Soporte de idioma nacional (NLS): "Soporte de Unicode en DB2 UDB".