Unicode 標準是書寫字元及文字方面全球通用的字元編碼方法。 它非常精確地定義了字集,以及少數的 Unicode 編碼。 它定義了一種一致的方式來將多國語言文字編碼, 使得文字資料可在國際間交換,並創立世界級軟體的基礎。
Unicode 提供了兩種編碼方法:UTF-16 及 UTF-8。
預設的編碼方法是 UTF-16 (16 位元的編碼格式)。UCS-2 是 UTF-16 的子集, 它使用兩個位元組來表示一個字元。UCS-2 通常被認可為全球性的字碼頁, 它能夠表示目前所有單位元組字碼頁及雙位元組字碼頁的全部必需字元。UCS-2 在 IBM 中註冊為字碼頁 1200。
另一個 Unicode 編碼格式是 UTF-8,它是位元組導向的, 且是被設計來方便現有 ASCII 系統的使用。UTF-8 使用不定數目的位元組 (通常為 1-3,有時是 4) 來儲存每個字元。 無變化的 ASCII 字元就儲存為單位元組。所有其它字元就使用多個位元組來儲存。通常 UTF-8 資料可依據非設計為多位元組字碼頁的字碼來視為擴充的 ASCII 資料。 UTF-8 在 IBM 中註冊為字碼頁 1208。
應用程式要考慮到資料在區域字碼頁、UCS-2 和 UTF-8 之間做轉換時的需求, 這是很重要的。例如,20 個字元在 UCS-2 中需要完整的 40 個位元組, UTF-8 則介於 20 到 60 個位元組之間 (視原先使用的字碼頁及文字而定)。
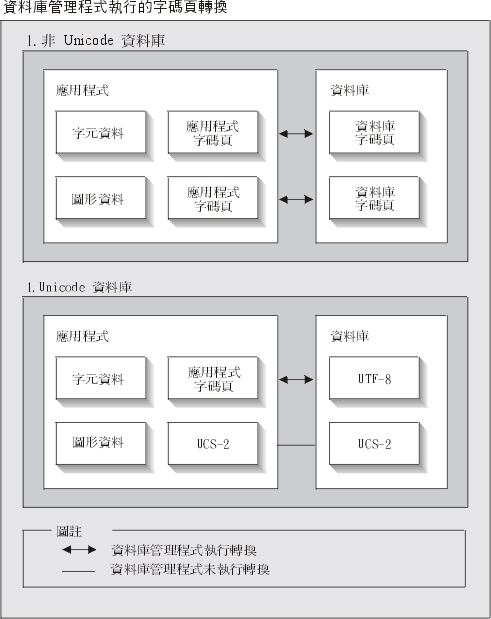
指定 UTF-8 字碼集所建立的 DB2 Universal Database for Unix、Windows 或 OS/2, 可用來儲存 UCS-2 及 UTF-8 兩種格式的資料。 這樣的資料庫可被視為 Unicode 資料庫。 SQL 字元資料是使用 UTF-8 進行編碼, 而 SQL 圖形資料是使用 UCS-2 進行編碼。這表示 MBCS 字元(包括單一位元組及雙位元組字元)儲存在字元直欄中, 而 DBCS 字元則儲存在圖形直欄中。
應用程式的字碼頁可能和 DB2 用來儲存資料的字碼頁不一樣。 在非 Unicode 資料庫中,在字碼頁不一樣時, 資料庫管理程式會轉換從屬站及伺服器之間傳送的字元及圖形 (pure DBCS) 資料。 在 Unicode 資料庫中,從屬站字碼頁與 UTF-8 之間的字元資料轉換會自動由資料庫管理程式來執行, 但是所有的圖形 (UCS-2) 資料不經過轉換就在從屬站及伺服器之間傳送。
註:
應用程式是可以指定 UTF-8 字碼頁,以指出它將用 UCS-2 來傳送及接收圖形資料, 並用 UTF-8 來傳送及接收字元資料。 此應用程式字碼頁只支援 Unicode 資料庫。
使用 Unicode 時要考慮的其它項目為:
CREATE DATABASE unidb USING CODESET UTF-8 TERRITORY US
db2set DB2CODEPAGE=1208
SELECT * FROM mytable WHERE mychar = 'utf-8 data' AND mygraphic = G'ucs-2 data'
這些版本注意事項中含有下列在 DB2 版本 7.1 中使用 Unicode 相關資訊的更新:
Chapter 3. Language Elements
Chapter 4. Functions
|Chapter 6. SQL Statements
Chapter 3. Using Advanced Features
Appendix C. DB2 CLI and ODBC
如需在 DB2 中使用 Unicode 的相關資訊,請參照 Administration Guide 的 National Language Support (NLS) appendix: "Unicode Support in DB2 UDB"。