Стандарт Unicode - универсальная схема кодирования символов для записи символов и текста. Он очень подробно определяет набор символов и некоторое число кодировок для него. Unicode представляет логичный способ кодирования многоязычных текстов, поддерживающий международный обмен текстовыми данными и создающий основу для написания программ, работающих в любой языковой среде.
Unicode поддерживает две схемы кодирования - UTF-16 и UTF-8.
По умолчанию используется схема кодирования UTF-16 с 16-битным форматом. UCS-2 представляет собой поднабор UTF-16, использующий для представления одного символа два байта. UCS-2 обычно воспринимается как универсальная кодовая страница, способная представлять все необходимые символы всех существующих одно- и двухбайтных кодовых страниц. UCS-2 зарегистрирована в IBM как кодовая страница 1200.
Другой формат кодирования Unicode - байт-ориентированный формат UTF-8, разработанный для облегчения его использования с существующими системами на основе ASCII. UTF-8 использует для хранения одного символа переменное число байтов (обычно 1 - 3, иногда 4). Инвариантные символы ASCII хранятся в виде одиночных байтов. Любой другой символ хранится, как несколько байт. В общем случае данные UTF-8 можно рассматривать как расширение данных ASCII, а не как код для многобайтных кодовых страниц. UTF-8 зарегистрирован в IBM как кодовая страница 1208.
Важно, чтобы прикладные программы учитывали требования к размеру данных при их преобразовании между национальной кодовой страницей, UCS-2 и UTF-8. Например, для 20 символов в UCS-2 потребуется ровно 40 байтов, а в UTF-8 - от 20 до 60 в зависимости от исходной кодовой страницы и использованных символов.
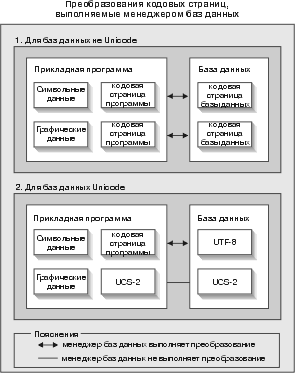
В Unix, Windows и OS/2 база данных DB2 UDB, созданная с указанием кодового набора UTF-8, может использоваться для хранения данных как в формате UCS-2, так и UTF-8. Такая база данных называется базой данных Unicode. Символьные данные SQL кодируются с использованием UTF-8, а графические - с использованием UCS-2. Это означает, что символы MBCS, как однобайтные, так и двухбайтные, хранятся в символьных столбцах, а символы DBCS - в графических.
Кодовая страница прикладной программы может не совпадать с кодовой страницей, которую DB2 использует для хранения данных. В других базах данных (не Unicode) при несовпадении этих кодовых страниц менеджер баз данных преобразует символьные и графические (исключительно DBCS) данные при переносе их между клиентом и сервером. В базе данных Unicode менеджер баз данных автоматически выполняет преобразование символьных данных между кодовой страницей клиента и UTF-8, но все графические данные (UCS-2) передаются между клиентом и сервером без преобразования.
Рис. 1. Преобразования кодовых страниц, выполняемые менеджером баз данных
Примечания:
Для прикладной программы можно указать кодовую страницу UTF-8, что означает, что она будет передавать и получать все графические данные в UCS-2, а символьные данные - в UTF-8. Эта кодовая страница прикладной программы поддерживается только для баз данных Unicode.
При использовании Unicode необходимо также принимать во внимание следующее:
CREATE DATABASE unidb USING CODESET UTF-8 TERRITORY US
db2set DB2CODEPAGE=1208
SELECT * FROM mytable WHERE mychar = 'данные utf-8' AND mygraphic = G'данные ucs-2'
В этих замечаниях изменена следующая информация об использовании Unicode с DB2 Версии 7.1:
Глава 3. Language Elements (Элементы языка)
Глава 4. Functions (Функции)
|Глава 6. SQL Statements (Операторы SQL)
Глава 3. Using Advanced Features (Использование дополнительных возможностей)
Приложение C. DB2 CLI and ODBC (CLI DB2 и ODBC)
Дополнительную информацию об использовании Unicode с DB2 смотрите в книге Руководство администратора, в приложении National Language Support (NLS, Поддержка национальных языков): "Unicode Support in DB2 UDB".